# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。

每秒 1024 token 的流畅解码,超过 4000 token 的峰值吞吐,只需要搭载在通用服务器上。这个成绩不仅刷新了国产 GPU 的推理性能记录,更以稳定的低延迟,验证了其 AI 算力的高效与可用性,成为了国产算力的一个里程碑。
上周六,国产 GPU 第一股摩尔线程,首次完整揭幕了其新一代统一计算架构 MUSA 的路线图。从芯片设计、AI 基础设施、基础软件到生态,MUSA 架构旨在为各种形态的 AI 与图形计算需求,提供全方位的支持。
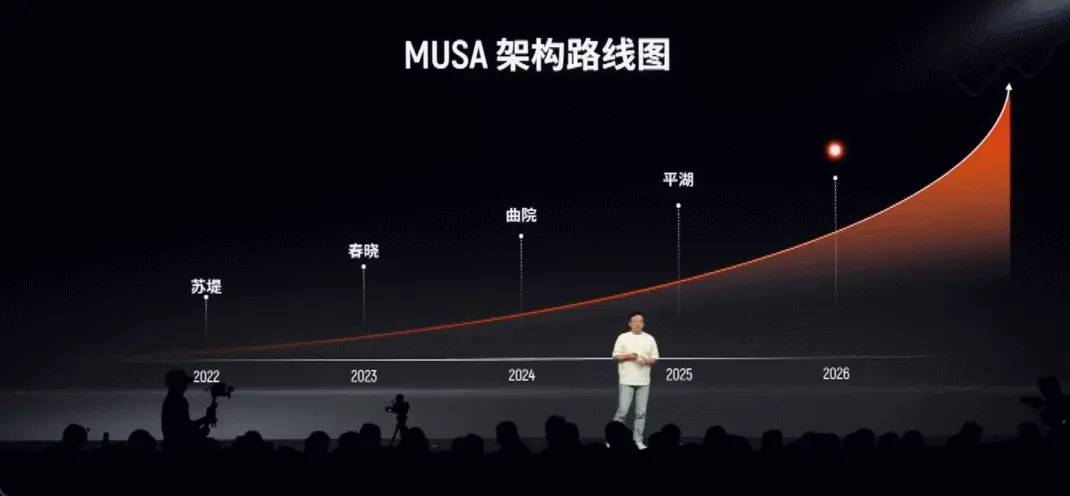
这是摩尔线程的首届 MUSA 开发者大会,也是其上市后技术体系的首次集中亮相。在长达两个半小时的 Keynote 中,摩尔线程创始人、董事长兼 CEO 张建中系统总结了过去五年的技术沉淀与研究成果,密集发布了一系列新产品,并对未来的发展路径进行了展望。
整场发布会,从底层架构到具体芯片,从整机到万卡集群,再到对具身智能、科学智能(AI4S)与量子计算等前沿领域的布局 —— 信息量巨大,新产品应接不暇,看起来已经有点 GTC 大会的样子了。
在这其中,最先被介绍的是其技术底座:MUSA,元计算统一系统架构。
MUSA(Meta-computing Unified System Architecture)是摩尔线程自主研发的、覆盖从芯片架构、指令集、编程模型到软件运行库及驱动程序框架等的全栈技术体系。它是贯穿摩尔线程全栈产品体系的技术基石,相当于从软件到硬件所有产品的设计蓝图。
张建中将 MUSA 架构分为几个层级进行了介绍,其最底层是全功能 GPU 架构,其上为硬件产品与系统(从单卡到大规模集群),最上层为全套软件栈与开发者生态。

在硬件层,本次发布的全功能 GPU 架构「花港」,标志着国产 GPU 在核心技术上的突破。

据介绍,「花港」在处理器架构、指令集层面进行了重新设计,旨在实现算力密度与能效比的飞跃。数据显示,相比上代,花港架构在同芯片面积下的算力密度提升了 50%,能效提升了 10 倍。
作为全功能 GPU 的载体,花港在原有 MTFP8 的技术下,新增 MTFP6/MTFP4 及混合低精度支持,支持从 FP4 到 FP64 的全精度端到端计算加速,覆盖了从低精度 AI 推理到高精度科学计算的广泛场景。MUSA 支持国际主流 GPU 生态,同时还支持国际通用的 CPU 系统,也支持所有国产主流 CPU、操作系统和国内开发环境。在安全层面,该架构采用了全硬件设计的安全保护机制,从底层筑牢了算力设施的安全防线,实现自主可控。
异步编程与超大规模互联是新架构突出的特点。「花港」带来了新一代的异步编程模型加速技术,全面优化异步编程模型、任务与资源调度机制,提升并行执行效率,这一能力能够大幅提升大模型训练的效率。与此同时,其自研 MTLink 互联技术实现了速度高达 1314GB/s 的片间互联,支持十万卡以上规模的智能集群扩展,为未来「AI 工厂」的建设奠定了基础。
图形处理方面,新架构集成了 AI 生成式渲染架构(AGR),增强的硬件光线追踪加速引擎(光线追踪性能比上一代提升 50 倍),并完整支持了 DirectX 12 Ultimate,这是国产 GPU 首次实现对行业顶级图形标准的完整支持。
与硬件架构同步升级的,是基础软件层 MUSA 5.0 软件栈。

张建中表示,MUSA 在 AI 框架上适配 PyTorch、Paddle 并新增了对 Jax、TensorFlow 的框架支持;训练套件在分布式训练框架 Megatron、DeepSpeed 的基础上,新增了强化学习训练框架 MT VeRL;推理套件在 MTT 推理引擎和深度学习模型 TensorX 的基础上,新增了对 SGLang、VLLM、Ollama 等推理框架的适配。
摩尔线程特别强调了在计算与通讯效率上的突破:其核心计算库在 GEMM(通用矩阵乘法)上的效率据称超过 98%,通讯效率达到 97%,这极大地降低了开发者在国产硬件上移植和优化应用的成本。
为了降低开发门槛,加速生态建设,摩尔线程计划逐步开源一系列高性能算子库。与此同时,摩尔线程准备推出四大基础库:
这些工具计划在明年陆续提供给开发者们使用。
通过 MUSA 基础架构的升级,摩尔线程可以实现芯片性能指数级的提升,与此同时也大幅降低了基于国产芯片的开发门槛。
有了新架构,下个问题就是:即将量产的产品是什么?
基于「花港」架构,摩尔线程公布了未来两款芯片的路线图,分别对应 AI 计算与专业图形渲染两大主战场。
在 AI 计算领域,新一代芯片「华山」被定位为对标国际顶尖水平的 AI 训推一体芯片。张建中在演讲中透露,「华山」在浮点计算能力上处于 NVIDIA Hopper 与 Blackwell 芯片产品之间。
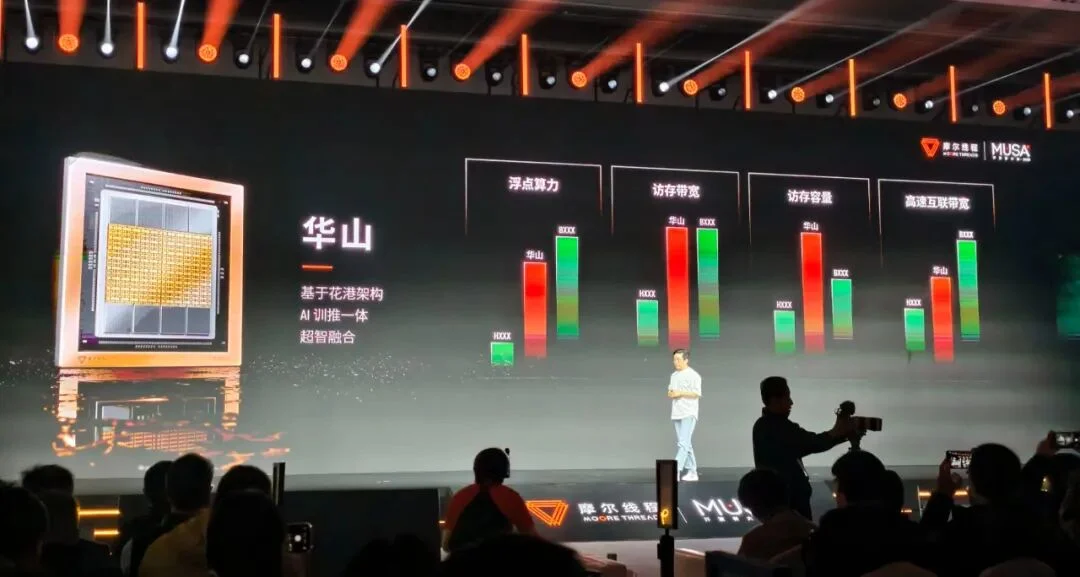
除了继承新架构的异步编程与超大规模互联能力,「华山」在访存带宽与容量设计上向国际一流产品看齐,并集成了新一代张量计算单元(TCE)。通过独特的 TCE-PAIR 模式,两个计算单元可共享数据,从而大幅减少数据调用开销,提升计算效率。
新一代芯片还内置了大语言模型专用加速引擎,可对 LLM 计算的全流程进行硬件加速。
此外,为满足万卡级集群需求,「华山」内置了支持多种协议的 MTLink 4.0,单节点即支持 1024 卡高速互联。
从列出的数据上可以看到,作为高端 AI 芯片,「华山」的综合能力已经跻身第一梯队水平,已经可以承接目前科技公司对于领先大模型的训练和推理需求。
在图形渲染领域,代号「庐山」的芯片则聚焦于解决国产显卡在游戏与专业设计领域的性能瓶颈。数据显示,相比上一代 S80 显卡,「庐山」的 3A 游戏性能提升了 15 倍。
摩尔线程还列出了一系列更加细化的数据提升:

在游戏玩家、专业用户关注的图形处理领域,「庐山」GPU 给出了具有说服力的水平。张建中表示:「据我们所知,庐山具有目前全球最高的几何能力。它不光能用来打 3A 游戏,所有的 CAD、CAE 等各种应用场景都能胜任。」
「庐山」的核心亮点在于引入了 AI 生成式渲染架构(AGR)和第二代硬件光线追踪引擎。除此之外,它搭载的统一任务引擎可以极致优化任务分配、平衡和同步,无论计算核心数量是多少,都能实现高效调度,,大幅提升运行效率。
从「花港」、「华山」到「庐山」,摩尔线程提供的新一代体系,可以带来开发者们渴望已久的一流计算速度与图形性能。
单卡性能之上,高性能芯片面向 AI 计算等场景还要面临大规模互联(Scale-up)的挑战。
摩尔线程展示了当前产品的落地实测数据,以此回应市场对国产算力「实际效能」的关切,并给大家看了看姱娥(KUAE)万卡智算集群的样子。

摩尔线程正式发布了夸娥万卡智算集群(KUAE2.0)。作为中国自主研发的超级 AI 基础设施,其拥有 10 Exa-FLOPS 算力,可以支持万亿参数大模型的训练。它在 Dense 大模型上的训练算力利用率(MFU)超过 60%,线性加速比达到 95%,训练线性扩展效率达 95%,证明了国产算力已具备承接超大规模模型训练工程化落地的卓越稳定性。
摩尔线程还计划推出超级节点产品 MTT C256,它能够以一层 scale up 网络实现两柜 256GPU 全互联,规避两层以上网络带来的带宽损失和额外延迟,大幅提高新型智算中心 GPU 部署密度。

当前,AI 算力竞赛正在进入「系统级对决」时代,单卡性能的比拼正在转向「系统升维」,通过对通信能力、负载效率的优化,摩尔线程正在将国产芯片的集群效应推向极致。
面向未来,摩尔线程展开了其在前沿计算场景的广阔布局,其着眼的方面不仅在于大模型、图形技术,还包括具身智能、AI for Science、量子计算、AI For 6G 等融合创新计算领域。
它们是一系列 AI 算力生态构建的探索与成果,也是未来国产算力更大规模应用的开始。

在图形计算方面,摩尔线程的 GPU 架构已迈入实时光线追踪时代,基于花港架构的硬件光线追踪加速引擎可实现对 DirectX Raytracing 的支持,同时推出的全自研的 AI 生成式渲染技术 MTAGR 1.0,推动渲染技术范式从「计算」走向「生成」。
在具身智能领域,摩尔线程发布了 MT Lambda 具身智能仿真训练平台,深度融合物理、渲染与 AI 三大引擎,其还推出了基于智能 SoC 芯片「长江」、AI 模组 MTT E300 和夸娥智算集群「端云结合」的 MT Robot 具身智能解决方案。
更多领域上,更广泛的前沿融合计算探索也已展开,MUSA 生态已与合作伙伴在科学智能、量子科技、AI for 6G 等前沿交叉领域开展工作,持续拓展全功能 GPU 作为通用算力底座的技术边界与应用价值。
一切技术的最终价值,在于生态的繁荣。
为此,摩尔线程发起了「摩尔学院」,它专为 GPU 开发者、科研人员以及产业实践者设计,提供从入门到精通的全方位培训。摩尔线程表示,这项行动已经走进了全国 200 多所高校,吸引了超过 10 万名青年学子参与。面向更广泛开发者的「MUSA 开发者计划」也已启动。
最后,还有一款普通人最容易接触得到的产品。
摩尔线程在大会上发布了 AI 算力笔记本 MTT AIBOOK,作为连接开发者与 MUSA 生态的核心入口,旨在让先进算力赋予每一个创作者和开发者。

MTT AIBOOK 是专为 AI 学习与开发的个人智算平台,搭载了自主研发的智能 SoC 芯片「长江」,其中集成了 CPU、GPU、NPU、VPU、DPU、DSP、ISP 等 IP 核心,异构 AI 算力达 50TOPS,可以在本地运行 30B 参数的端侧大模型,承载多种任务负载,并配置了可以自由构建 Agent 的「工具集」,大幅降低 AI 开发的门槛。
同时,AIBOOK 还支持 Windows 虚拟机、Linux、安卓容器以及所有国产操作系统,实现了从芯片、驱动到开发环境的全栈整合,还内置了智能体「小麦」及多种 AI 应用,在保留传统 PC 的完整功能上,实现了「开箱即用」的一站式 AI 开发体验
目前 AIBOOK 已经可以在京东上下单,明年一月就会发货。面向 AI 开发者和专业用户市场,甚至 AI 爱好者与初学者也能使用。估计过不了多久,就会出现不少有关 AIBOOK 算力本的第三方评测了。
从 MTT AIBOOK 上,我们可以看到摩尔线程打造「全功能」计算产品的决心,它面向所有的数据类型与应用场景,可以解决各个领域、行业的不同需求,也是最普遍意义上计算能力的体现。
在当前 AI 爆发与计算范式变革的关键节点,摩尔线程用一系列扎实的技术突破与清晰的生态蓝图,有力宣告了国产算力自主化的时代,正加速到来。
文章来自于“机器之心”,作者 “泽南、+0”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
