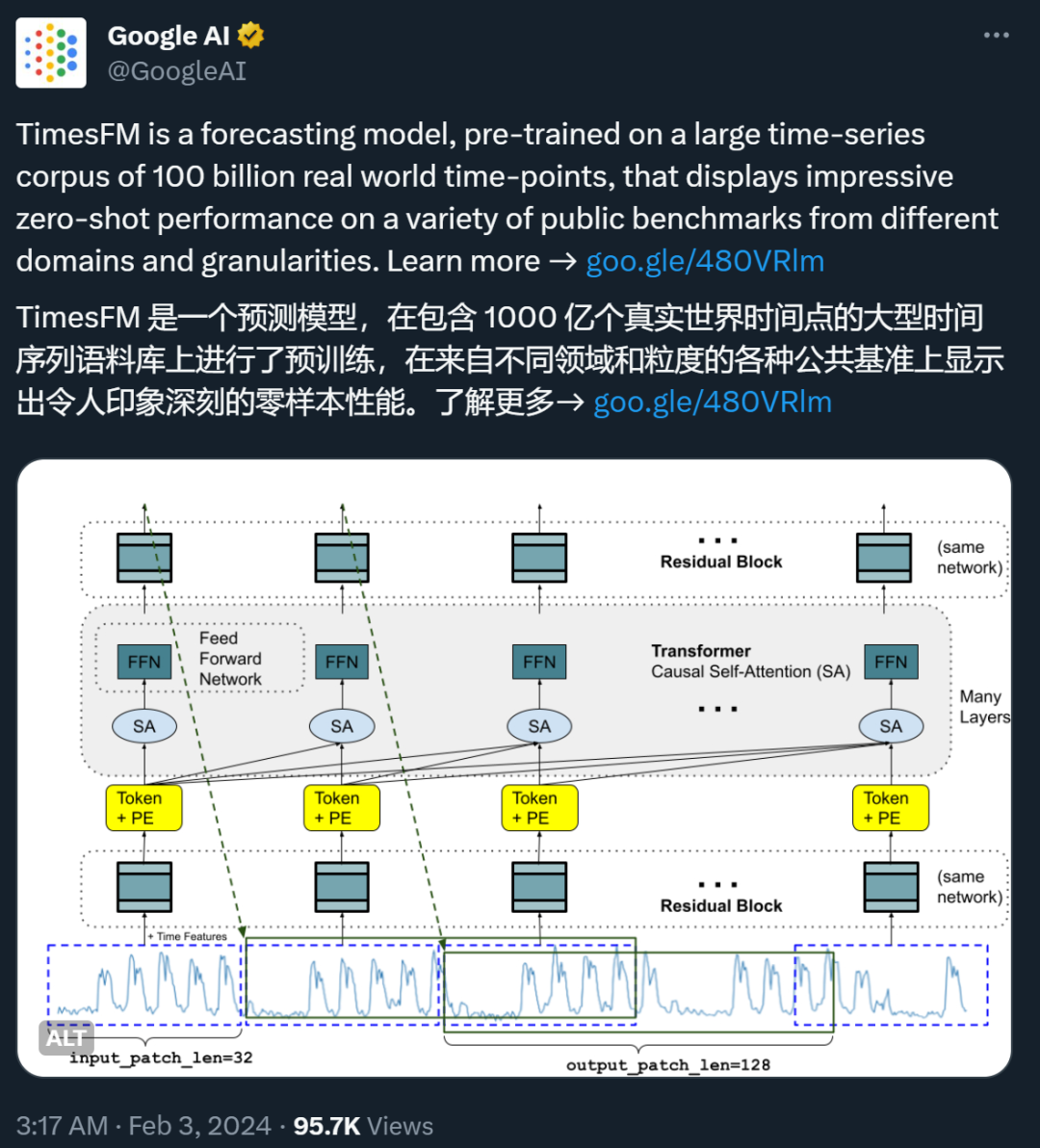
比OpenAI官方提示词指南更全,这26条黄金准则让LLM性能飙升50%以上
比OpenAI官方提示词指南更全,这26条黄金准则让LLM性能飙升50%以上今天,穆罕默德・本・扎耶德人工智能大学 VILA Lab 带来了一项关于如何更好地为不同规模的大模型书写提示词(prompt)的研究,让大模型性能在不需要任何额外训练的前提下轻松提升 50% 以上。该工作在 X (Twitter)、Reddit 和 LinkedIn 等平台上都引起了广泛的讨论和关注。
来自主题: AI技术研报
6382 点击 2024-02-05 14:39