
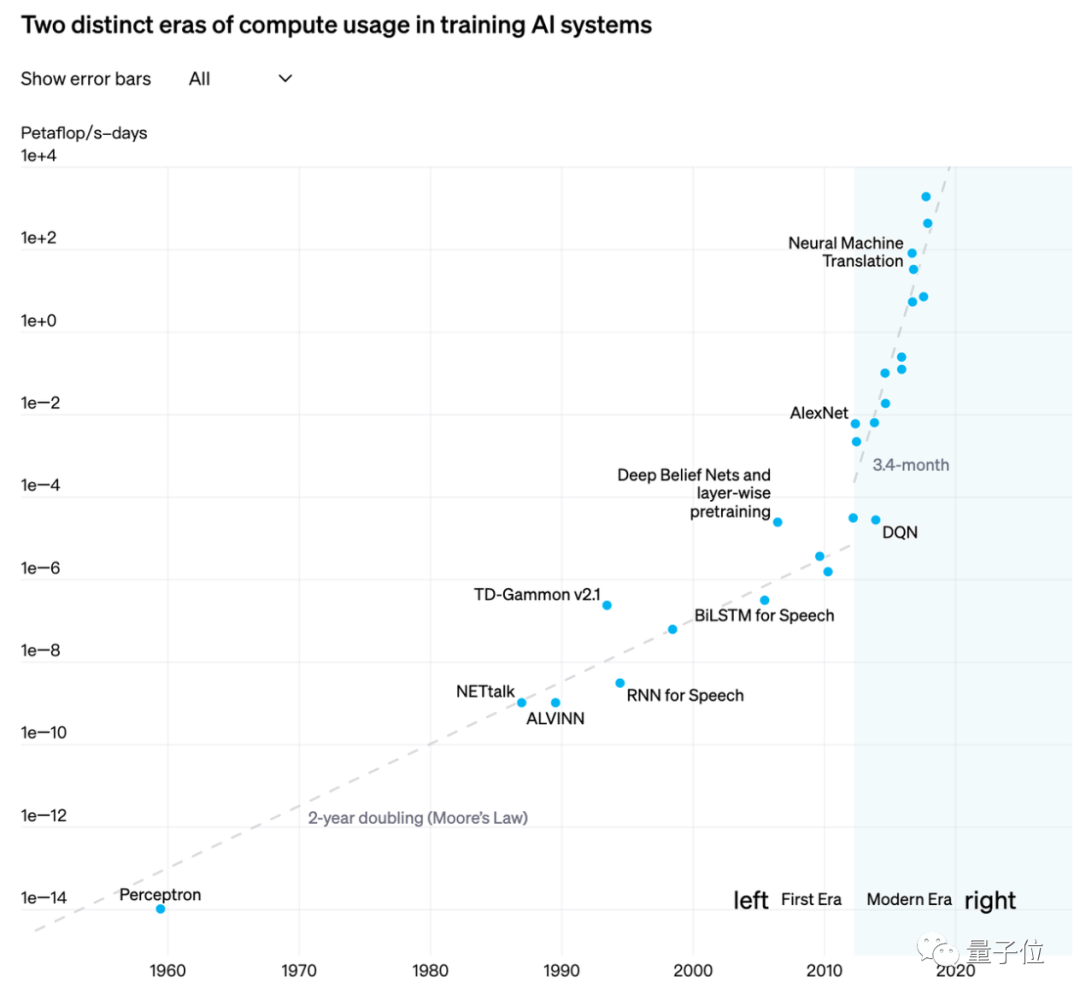
如果没有AI算力,大模型这场战役我们可能胜不了
如果没有AI算力,大模型这场战役我们可能胜不了没想到,在ChatGPT爆火后的一年里,竟然出现了一个隐藏“Boss”——量子位获悉,百度、360等互联网大厂均已开始基于昇腾部署AI模型;而知乎、新浪、美图这样全速推进AI业务的公司,背后同样出现了华为云昇腾AI云服务的身影。
来自主题: AI资讯
11629 点击 2023-12-08 14:45
没想到,在ChatGPT爆火后的一年里,竟然出现了一个隐藏“Boss”——量子位获悉,百度、360等互联网大厂均已开始基于昇腾部署AI模型;而知乎、新浪、美图这样全速推进AI业务的公司,背后同样出现了华为云昇腾AI云服务的身影。
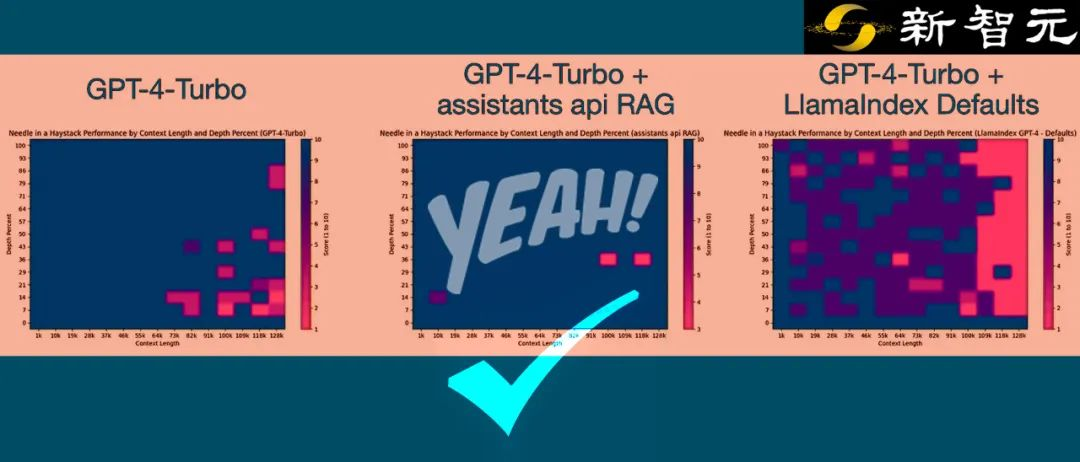
RAG或许就是大模型能力飙升下一个未来。RAG+GPT-4,4%的成本,便可拥有卓越的性能。

昨天深夜,Google 突然发布重磅 AI 杀手锏——Gemini。多模态 Gemini 可以理解、操作和结合不同类型的信息,包括文本、代码、音频、图像和视频。

时代变了?迄今为止规模最大,能力最强的谷歌大模型来了。当地时间 12 月 6 日,谷歌 CEO 桑达尔・皮查伊官宣 Gemini 1.0 版正式上线。
大模型究竟从下一个词预测任务中学到了什么呢?还记得 Jason Wei 吗?这位思维链的提出者还曾共同领导了指令调优的早期工作,并和 Yi Tay、Jeff Dean 等人合著了关于大模型涌现能力的论文。
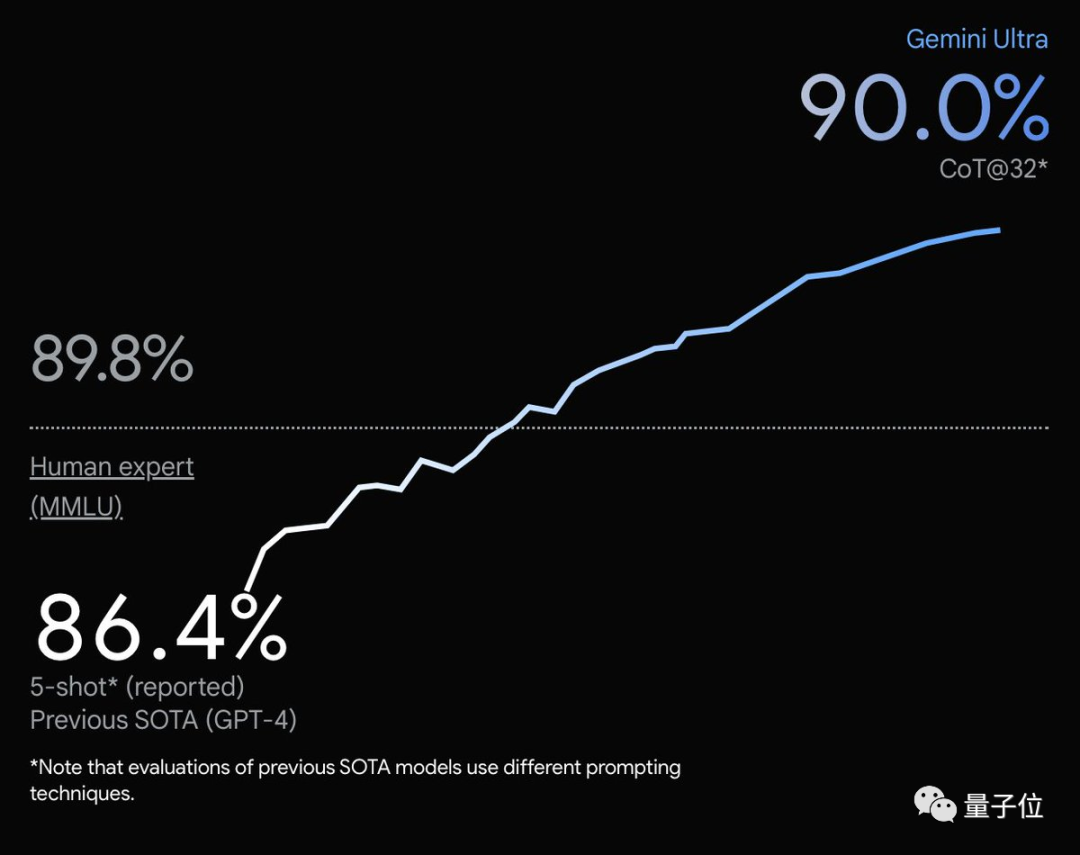
谷歌憋了许久的大招,双子座Gemini大模型终于发布!其中一图一视频最引人注目:一图,MMLU多任务语言理解数据集测试,Gemini Ultra不光超越GPT-4,甚至超越了人类专家。
苹果M系列芯片专属的机器学习框架,开源即爆火!现在,用上这个框架,你就能直接在苹果GPU上跑70亿参数大模型、训练Transformer模型或是搞LoRA微调。
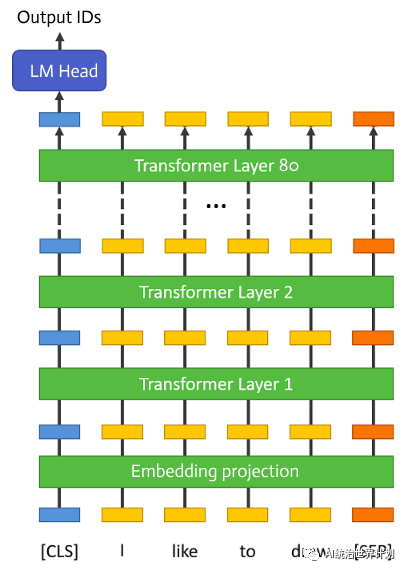
大语言模型需要消耗巨量的GPU内存。有可能一个单卡GPU跑推理吗?可以的话,最低多少显存?70B大语言模型仅参数量就有130GB,仅仅把模型加载到GPU显卡里边就需要2台顶配100GB内存的A100。

12月5-6日,主题为“未来AI设计”的美图创造力大会在厦门举行。美图公司发布自研AI视觉大模型MiracleVision(奇想智能)4.0版本,主打AI设计与AI视频。
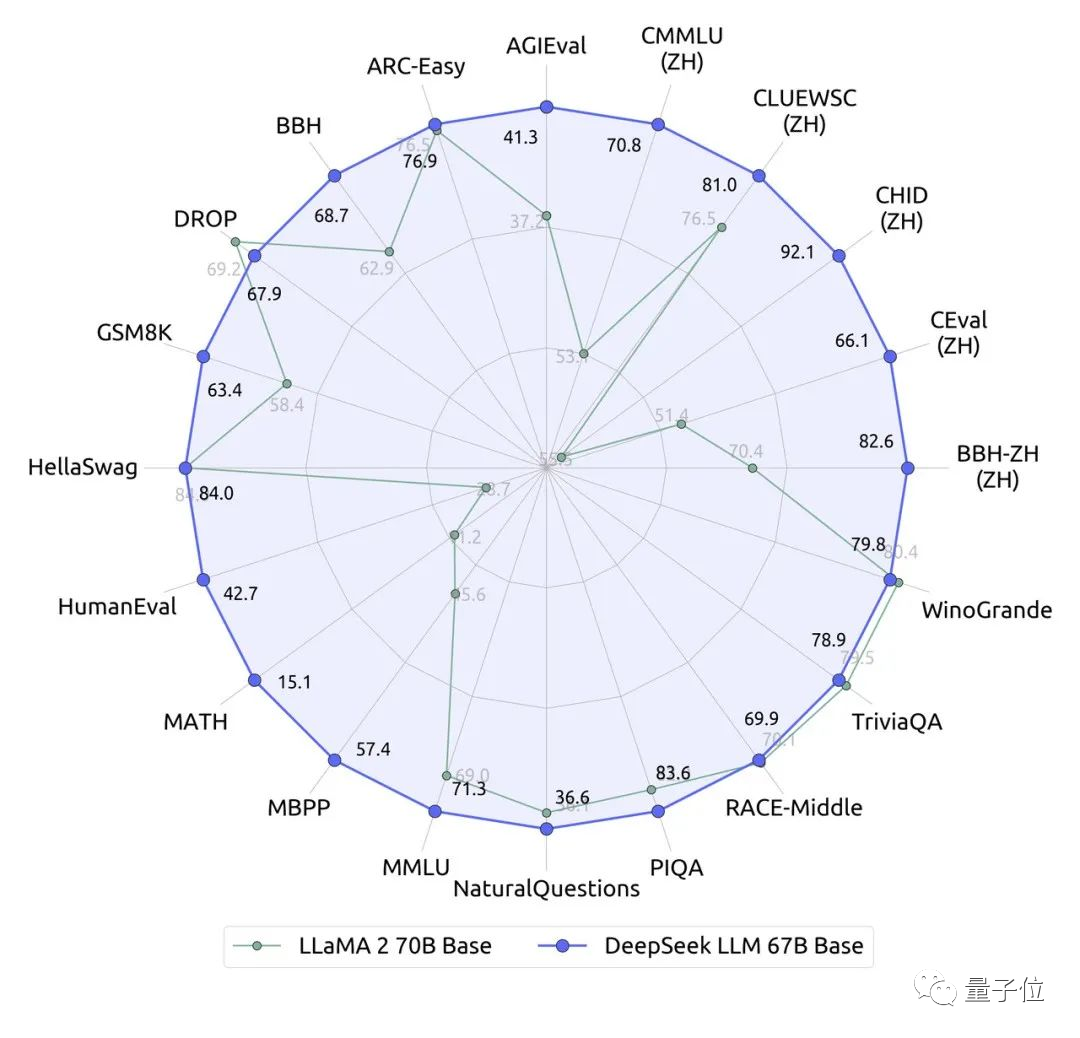
国产大模型刚刚出了一位全新选手:参数670亿的DeepSeek。它在近20个中英文的公开评测榜单上直接超越了同量级、700亿的Llama 2。