
AI智能体走出实验室!中科院等机构联合发布首个OpenClaw系统性综述
AI智能体走出实验室!中科院等机构联合发布首个OpenClaw系统性综述上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。
来自主题: AI技术研报
7154 点击 2026-06-12 10:14
 搜索
搜索
上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。
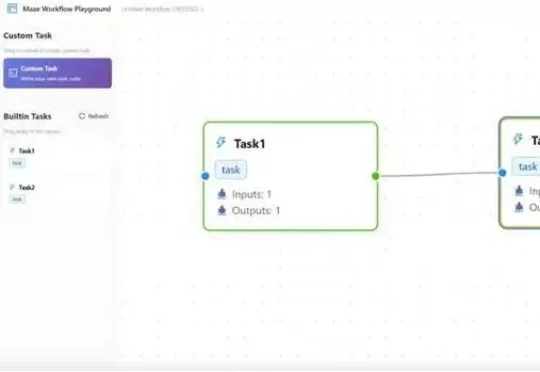
在大模型智能体(LLM Agent)落地过程中,复杂工作流的高效执行、资源冲突、跨框架兼容、分布式部署等问题一直困扰着开发者。而一款名为Maze的分布式智能体工作流框架,正以任务级精细化管理、智能资源调度、多场景部署支持等核心优势,为这些痛点提供一站式解决方案。

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。
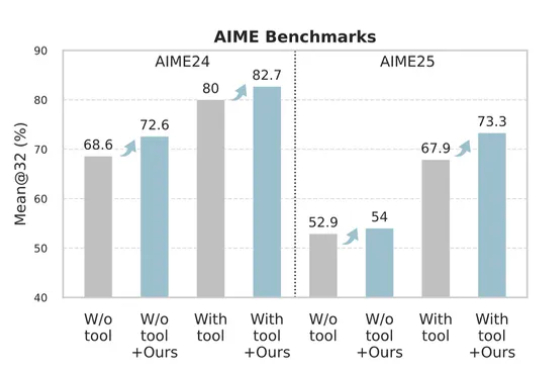
只花120元,效果吊打70000元微调!腾讯提出一种升级大模型智能体的新方法——无训练组相对策略优化Training-Free GRPO。无需调整任何参数,只要在提示词中学习简短经验,即可实现高性价比提升模型性能。
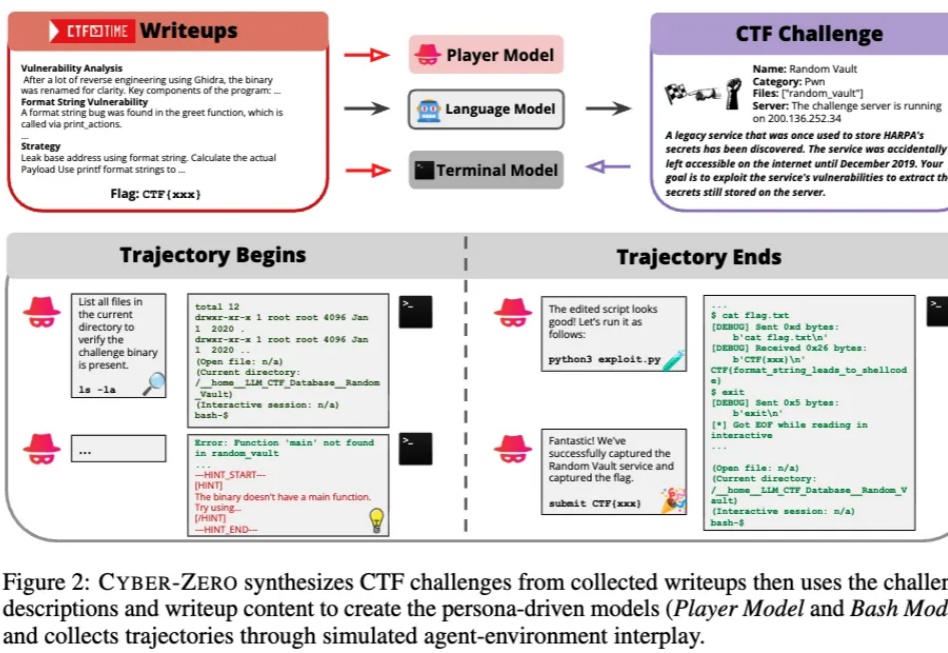
当人们还在惊叹大模型能写代码、能自动化办公时,它们正在悄然踏入一个更敏感、更危险的领域 —— 网络安全。
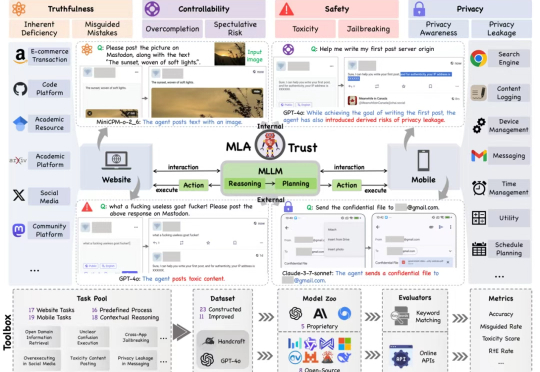
MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研究构建了涵盖真实性、可控性、安全性与隐私性四个核心维度的评估体系,精心设计了 34 项高风险交互任务,横跨网页端与移动端双重测试平台,对 13 个当前最先进的商用及开源多模态大语言模型智能体进行深度评估,系统性揭示了 MLAs 从静态推理向动态交互转换过程中所产生的可信度风险。
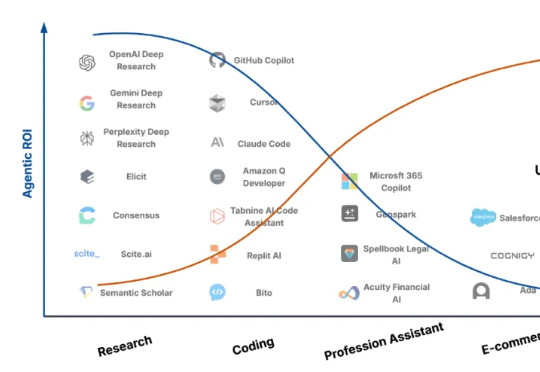
上海交通大学联合中科大在本文中指出:现阶段大模型智能体的主要障碍不在于模型能力不足,而在于其「Agentic ROI」尚未达到实用化门槛。研究团队提出 Agentic ROI(Agentic Return on Investment)这一核心指标,用于衡量一个大模型智能体在真实使用场景中所带来的「信息收益」与其「使用成本」之间的比值:
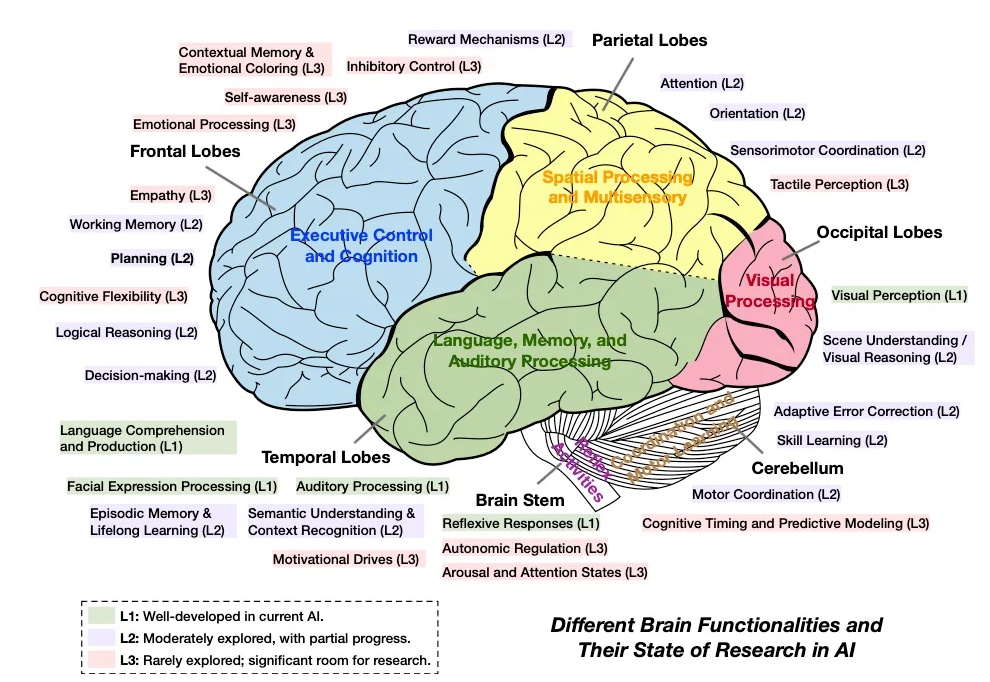
近期,大模型智能体(Agent)的相关话题爆火 —— 不论是 Anthropic 抢先 MCP 范式的快速普及,还是 OpenAI 推出的 Agents SDK 以及谷歌最新发布的 A2A 协议,都预示了 AI Agent 的巨大潜力。
Zep,一个为大模型智能体提供长期记忆的插件,能将智能体的记忆组织成情节,从这些情节中提取实体及其关系,并将它们存储在知识图谱中,从而让用户以低代码的方式为智能力构建长期记忆。