
ZenMux 的 Token 经济学实验:当主流模型的价格被降到 DeepSeek 斩杀线,你会选择谁?
ZenMux 的 Token 经济学实验:当主流模型的价格被降到 DeepSeek 斩杀线,你会选择谁?你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?
来自主题: AI产品测评
9283 点击 2026-06-30 09:55
 搜索
搜索
你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?
模型众多,该如何选择? GPT-5:OpenAI的最新旗舰模型,统一智能系统,GPT-5 集成了多个模型,自动根据任务复杂度选择最适合的模型进行处理,多模态首选。 GPT-5 Thinking:GPT

用过才知道,「快」不是万能药。
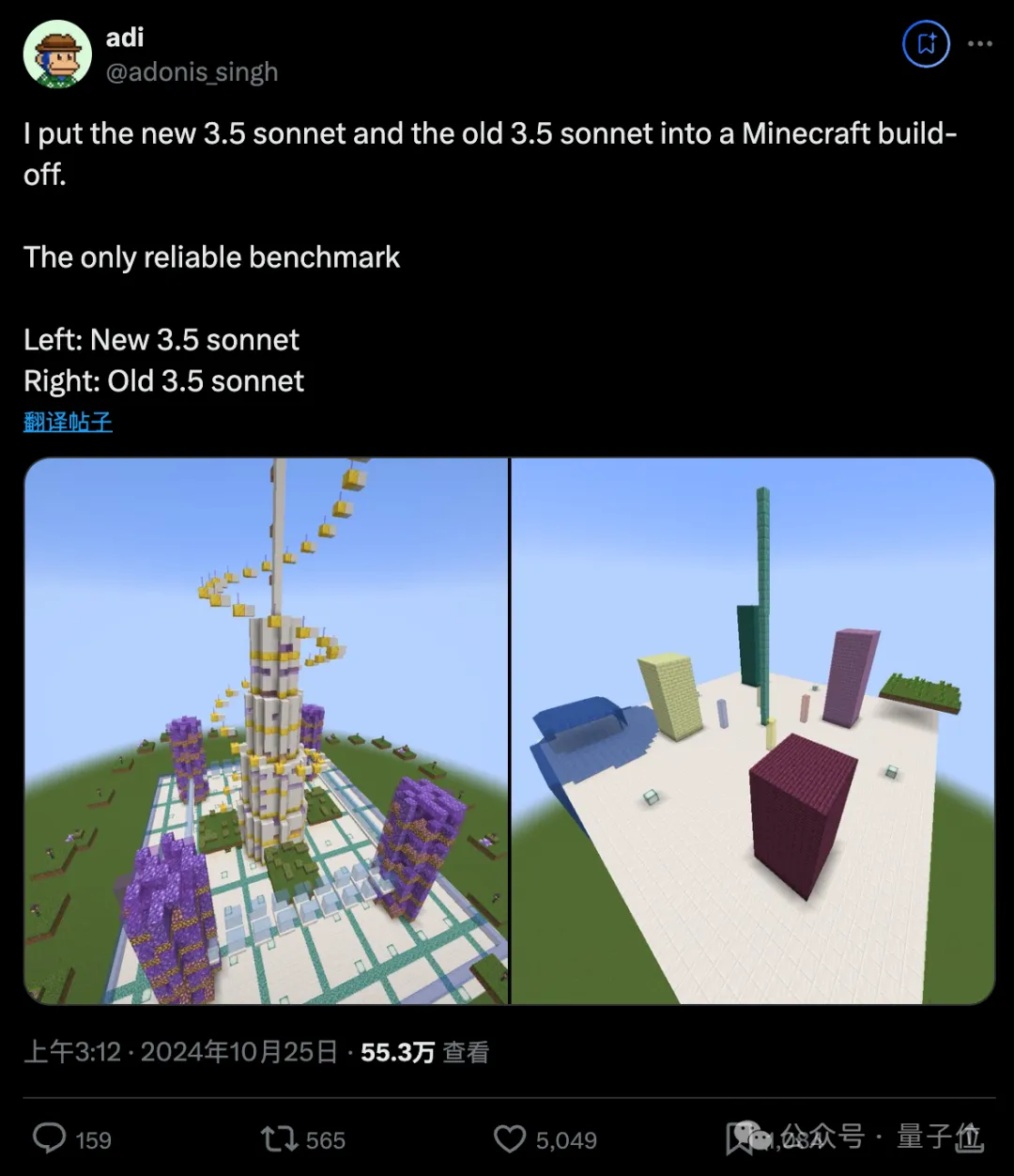
测评大模型Agent能力,从未如此直观。 新旧两版Claude 3.5 Sonnet在《我的世界》里PK盖楼,差距不要太明显,引来大量围观。
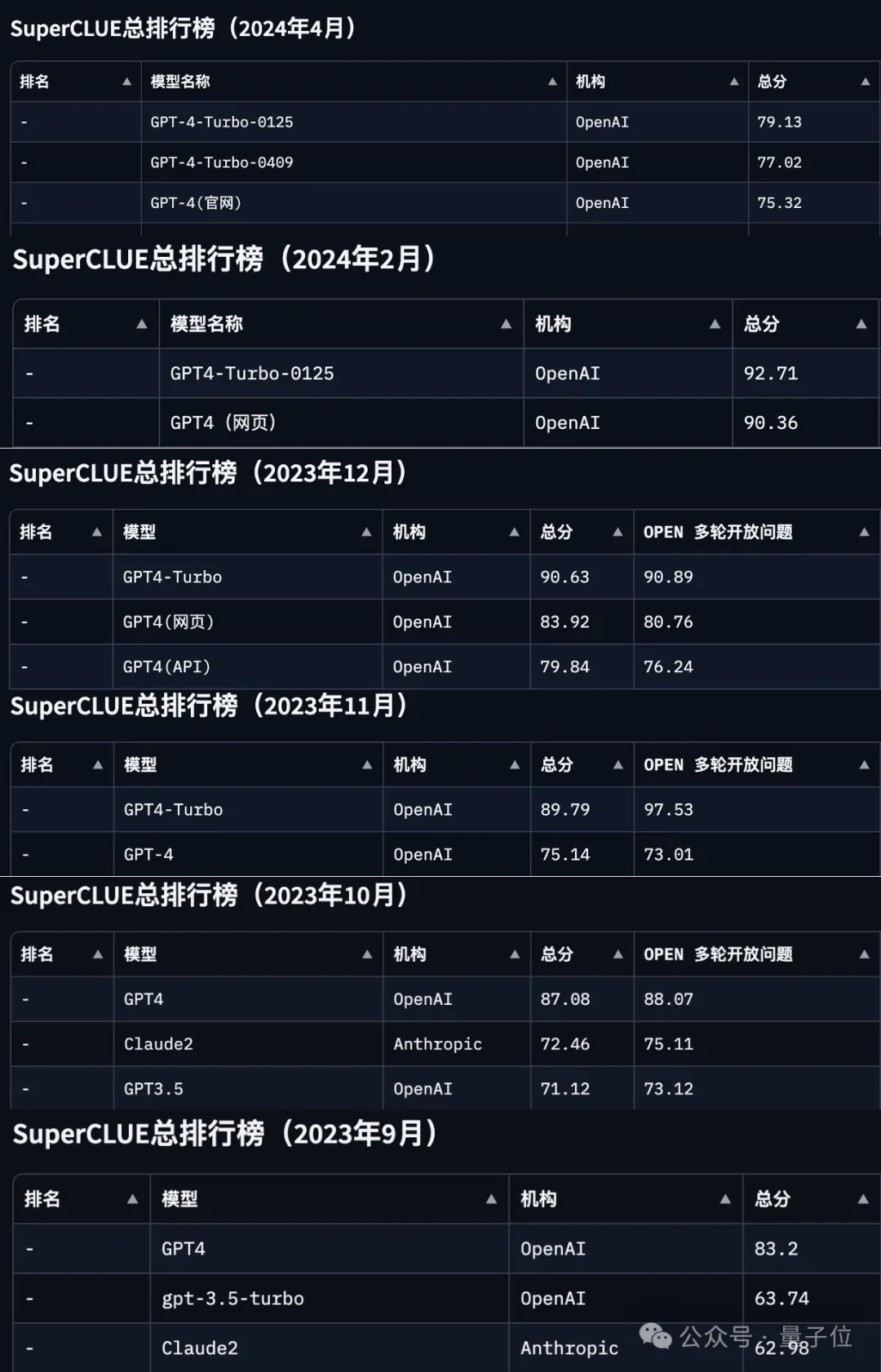
OpenAI长期霸榜的SuperCLUE(中文大模型测评基准),终于被国产大模型反将一军。

参照SuperCLUE(中文通用大模型综合性测评基准)框架专门定制了1000道题目集,一一测试了ChatGPT4、 智谱chatGLM-4、Baichuan2-Turbo、百度ERNIE-Bot 4.0、Yi-34B-chat、llama 2等模型在保险业务上的表现。
新华社研究院发布了《人工智能大模型体验报告2.0》,对国内主流大模型进行使用体验的横向测评。该榜单用500道题目评测了国内8款主流AI大模型,最终讯飞星火排名第一,百度文心一言排名第二,阿里通义千问排在倒数第二。