
大模型如何推理?斯坦福CS25重要一课,DeepMind首席科学家主讲
大模型如何推理?斯坦福CS25重要一课,DeepMind首席科学家主讲所有学LLM的人都要知道的内容。 这可能是对于大语言模型(LLM)原理最清晰、易懂的解读。
来自主题: AI资讯
8970 点击 2025-08-17 13:49
 搜索
搜索
所有学LLM的人都要知道的内容。 这可能是对于大语言模型(LLM)原理最清晰、易懂的解读。
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。
当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。
当前训练强大的大语言模型(LLM),就像是培养一个顶尖运动员,需要大量的、由专家(人类标注员)精心设计的训练计划和教材(高质量的标注数据)。
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。
Tavily AI 的故事开始于一个开源项目。创始人 Rotem Weiss 在 2023 年创建了一个叫做 GPT Researcher 的开源工具,目的是让大语言模型能够获取实时的网络数据。当时 ChatGPT 还没有接入互联网搜索功能,这个小工具迅速在开发者社区中走红,收获了近 2 万个 GitHub stars。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
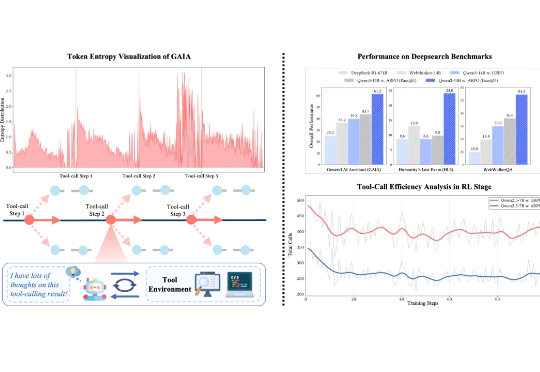
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
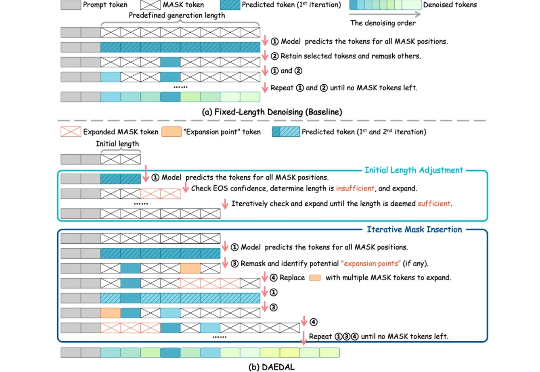
随着 Gemini-Diffusion,Seed-Diffusion 等扩散大语言模型(DLLM)的发布,这一领域成为了工业界和学术界的热门方向。但是,当前 DLLM 存在着在推理时必须采用预设固定长度的限制,对于不同任务都需要专门调整才能达到最优效果。