# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

在大语言模型席卷全球的时代,坚持更接近生命本质的智能是少有人走的路。2025年7月初,一篇来自Numenta与Thousand Brains Project的论文,首次通过一个名为“Monty”的AI系统,实验性地验证了神经科学家杰夫·霍金斯(Jeff Hawkins)提出的“千脑智能理论”。Monty抛弃了对海量静态数据的依赖,转而通过类似生物的“触摸”和“移动”来学习世界。它不仅能以惊人的效率识别三维物体,还能在持续学习中免于遗忘,其学习成本更是远低于深度学习模型。这项研究不仅为我们揭示了大脑运作的深层奥秘,也可能预示着通用人工智能的另一种未来。

▷论文:https://arxiv.org/abs/2507.04494
要理解智能,我们必须记住,大脑首先是一台行动的机器,而不是一台静态的观察仪。
——Jeff Hawkins
2025年,我们正生活在一个被人工智能的辉煌成就所包围的时代。大语言模型(LLMs)能写诗、能编程、能进行富有逻辑的对话,其能力边界似乎每天都在被刷新。然而,在这片繁荣景象的背后,一头“房间里的大象”愈发显眼——这些令人惊叹的AI系统,在本质上与生物智能,尤其是人类智能,存在着一条难以逾越的鸿沟。
它们是数据饕餮,需要吞噬整个互联网规模的数据才能获得智能的表象;它们患有严重的遗忘症,在学习新知识时会灾难性地忘记(catastrophic forgetting)旧知识;最重要的是,它们的“理解”似乎是无根之木,缺乏与物理世界真实的、可感知的交互作为基础。它们能描述苹果的味道,却从未“尝”过;能解释杯子的用法,却从未“握”过。
正如论文《千脑智能系统:用于快速、鲁棒学习和推理的感官运动智能》中所指出的:
当前的AI系统在许多任务上取得了令人印象深刻的性能,但它们缺乏生物智能的核心属性,包括快速、持续的学习,植根于感知运动交互的表征,以及能够实现高效泛化的结构化知识。
面对这条鸿沟,大多数研究者选择在现有路线上继续深挖,用更大的模型、更多的数据、更强的算力去填补,一次又一次寄希望于所谓“Scaling Law”的奇迹,但也有人选择另辟蹊径,回到一切智能的起点——大脑本身,去寻找答案。
这个人就是杰夫·霍金斯(Jeff Hawkins)。
你可能对这个名字有些印象。他是硅谷的传奇人物,上世纪90年代发明了第一台成功的掌上电脑PalmPilot,后来又创立了Numenta公司,将毕生精力投入到破解大脑新皮层(neocortex)密码的漫长征途。2004和2021年,他先后出版了《千脑智能》(A Thousand Brains)和《新机器智能》(On Intelligence)两本书,系统地阐述了他关于大脑如何工作的革命性理论。


这本书描绘了一幅与传统观点截然不同的智能图景:智能并非源于一个单一、庞大的中央处理器,而是源于大脑新皮层中成千上万个几乎相同的、微小的计算单元——皮层柱(cortical column)的分布式协同工作。每一个皮层柱都是一个完整的感知运动(sensorimotor)系统,独立地学习着世界的模型。我们的大脑,实际上拥有成千上万个“大脑”。
而近些年神经科学的研究,有好几项重量级发现:网格细胞(grid cell)、树突级预测编码与动觉对齐原理,都为Monty的设计提供了意外而坚实的神经生物学背书:
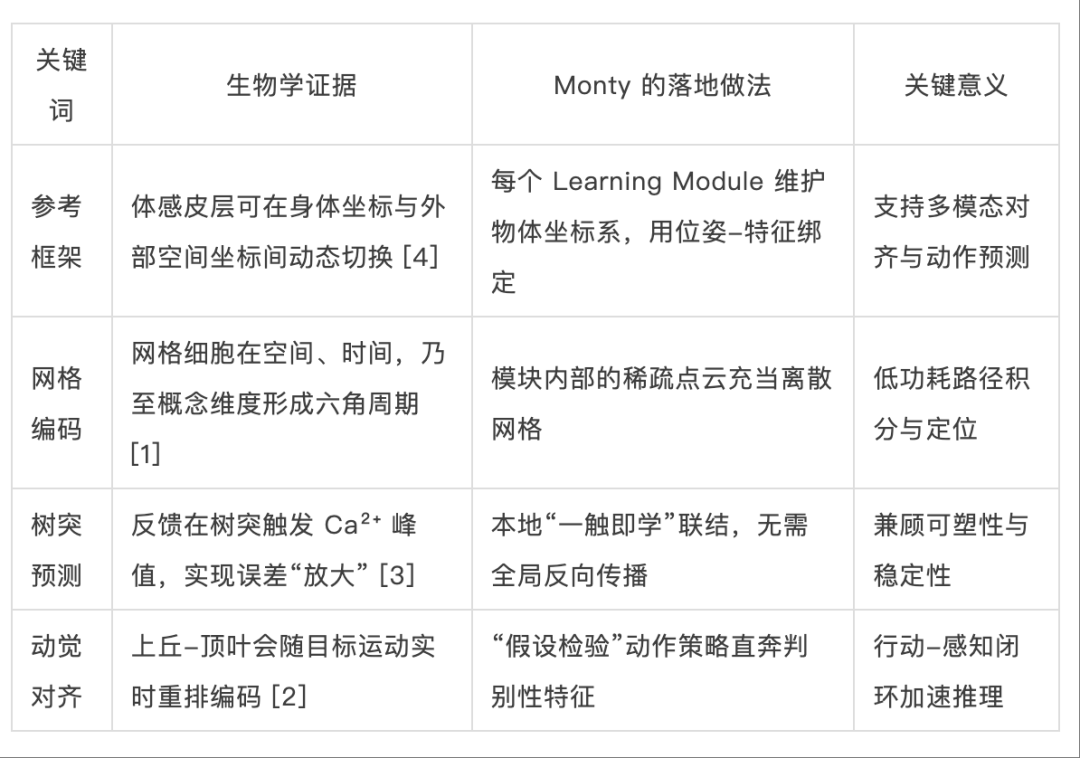
▷表1:千脑智能系统的神经生物学证据
当然理论固然优美,但依然需要被验证才有效。而我们今天要深入解读的这篇论文,正是“千脑智能理论”的第一次大规模、系统性的实验证明。论文的主角,一个名为Monty的AI系统,就是依照霍金斯的理论蓝图构建的。
要理解Monty,我们必须先理解它所模仿的对象——大脑新皮层。
新皮层就像是智能的“芯片工厂”。但奇怪的是,这家工厂只生产一种型号的“芯片”,那就是皮层柱,无论是用于视觉、听觉、触觉,还是语言概念和抽象推理,其底层的神经结构都惊人地一致,它就像大脑的通用计算单元。这引发了一个深刻的问题:大自然是如何用一种标准模块,实现了如此多样和灵活的智能?
霍金斯的答案是:通过感知-运动的方式,在参考框架(reference frames)中学习世界模型。这听起来很抽象,我们用一个简单的例子来拆解。
核心概念:参考框架(Reference Frame)
拿起你手边的咖啡杯。当你用手指触摸它时,你感受到了什么?你可能感觉到杯柄的弧度、杯壁的光滑、杯沿的锋利。在传统AI看来,这些是独立的特征(features)。但在“千脑理论”中,大脑处理的信息远不止于此。它记录的不是“一个弧度”,而是“在杯子这个物体的特定位置上的一个弧度”。
这个“物体的特定位置”,就是参考框架。你可以把参考框架想象成一个附着在咖啡杯上的、无形的3D坐标系,或者一个虚拟的脚手架。它定义了物体上每一个点的相对位置。你的大脑为世界上你认识的每一个物体,都学习了一个或多个这样的参考框架。
关键机制:运动(Movement)
参考框架不是凭空产生的,它是在运动中被建立起来的。当你的手指划过杯子表面时,你的皮层柱在做什么?
1.它接收来自手指的感官输入(曲率、温度、纹理等)。
2.同时,它追踪你手指的运动(通过肌肉和关节的位置变化)。
3.然后,它将感官输入“绑定”到参考框架中相应的位置上。
就像一个3D打印机,你的手指是打印头,感官信号是“墨水”,大脑通过移动手指,将关于杯子的信息一点点地“打印”到它的三维模型上。每一次触摸,都在填充这个模型的细节。看,也是同理。你的眼睛不断地进行微小的、快速的跳动(saccades),你的视网膜中心凹(fovea)就像一个高分辨率的探针,通过移动,扫描并构建出整个场景的完整模型。
这与当前AI的学习方式形成了鲜明对比。主流 AI像一个只能被动看照片的学生,通过一次性看完数百万张静态图片来学习“杯子”的概念。而生物智能则像一个亲手触摸、把玩杯子的婴儿,通过主动的探索和持续的交互,建立起对杯子牢固、多维度的理解。
正如论文所强调的:
生物系统通过主动探索和持续的感知运动整合来获取知识……而领先的AI架构则依赖于对互联网规模数据集的被动处理。
这种基于感知运动和参考框架的学习方式,赋予了生物智能强大的能力:
1.高效性:只需几次触摸或扫视,就能建立起一个物体的基本模型。
2.鲁棒性:模型是关于物体结构(shape)的,而非表面细节(texture)。无论杯子是什么颜色、什么材质,它的结构模型都是稳定的。
3.泛化能力:一旦你学会了“杯子”的模型,你就能从任何角度、在任何光线下认出它,甚至能认出你从未见过的、奇形怪状的杯子。
这就是“千脑智能”理论的核心思想。现在,让我们看看科学家们如何将这个思想变成现实。
Monty,这个名字是为了致敬最早发现皮层柱结构的神经科学家弗农·蒙特卡索(Vernon Mountcastle)。它是世界上第一个真正意义上的“千脑系统”(thousand-brains system)。
Monty的架构设计精妙地模拟了大脑的组织原则,主要由三个部分和一种通用通信协议构成(图1):
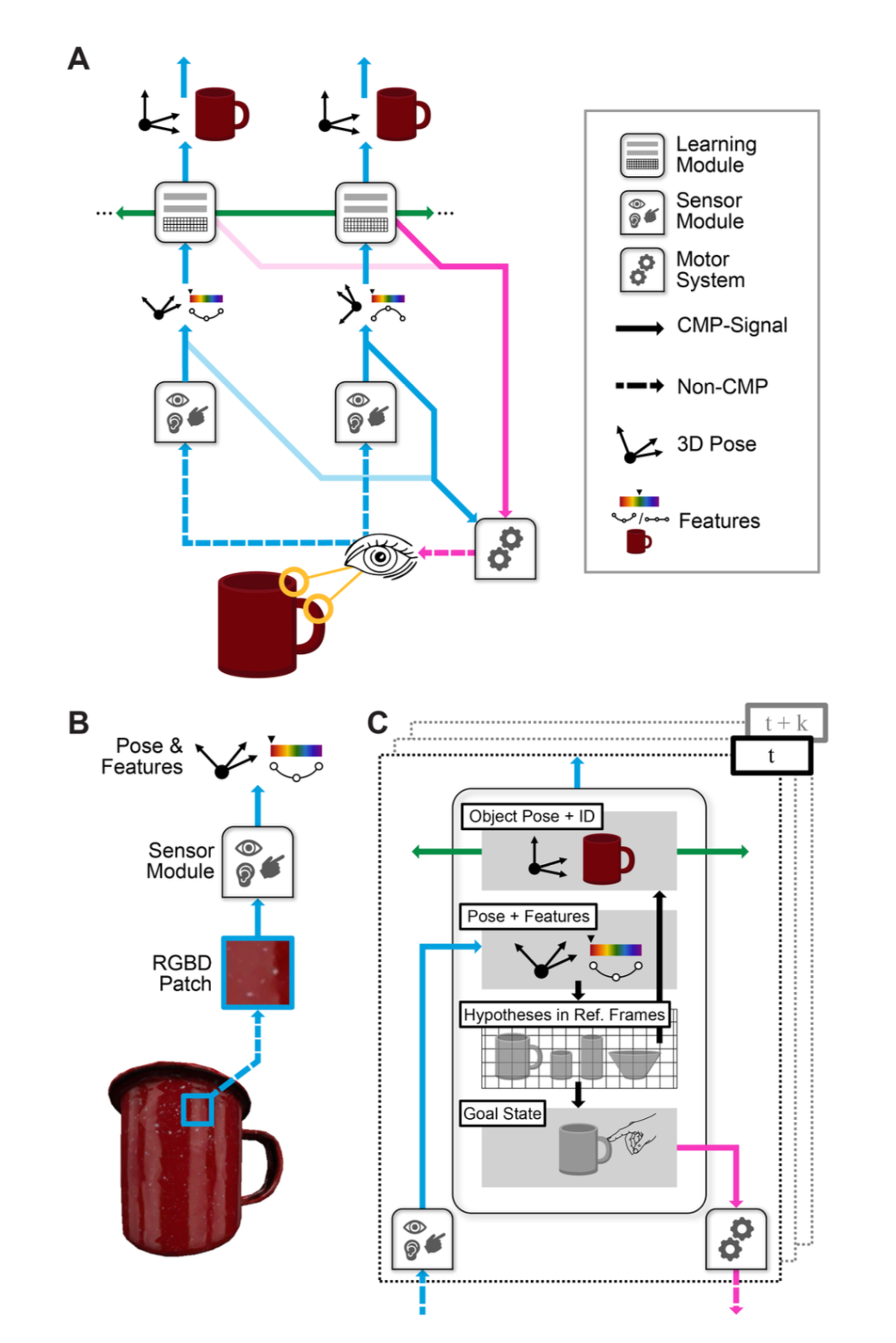
▷图1:千脑智能系统Monty的架构
Monty是如何学习一个新物体的?
让我们跟随Monty的视角,学习一个YCB数据集(一个包含77种日常家居用品的公开数据集)中的马克杯。
1.初次相遇:当一个马克杯首次出现时,一个学习模块(LM)会为它初始化一个新的、空白的参考框架。
2.移动与感知:运动系统驱动传感器模块(SM)开始在杯子表面移动。假设SM移动到了杯柄上,它会感知到局部的表面朝向、曲率和颜色,并将这些信息打包成一条 CMP消息发送给LM。
3.绑定与建模:LM接收到这条消息。它知道当前SM的位置(通过运动系统),于是它将感知到的特征(“这是一个弯曲的、红色的表面”)与该位置“绑定”,在参考框架的对应坐标上存下一个数据点。
4.模型构建:SM继续移动,扫过杯壁、杯沿、杯底。每到一处,LM就在参考框架中添加一个新的“特征-位置”数据点。很快,一个由许多离散点构成的、描述马克杯三维结构的“点云模型”就建立起来了(见图2)。这个模型是稀疏的,但抓住了物体的核心结构。
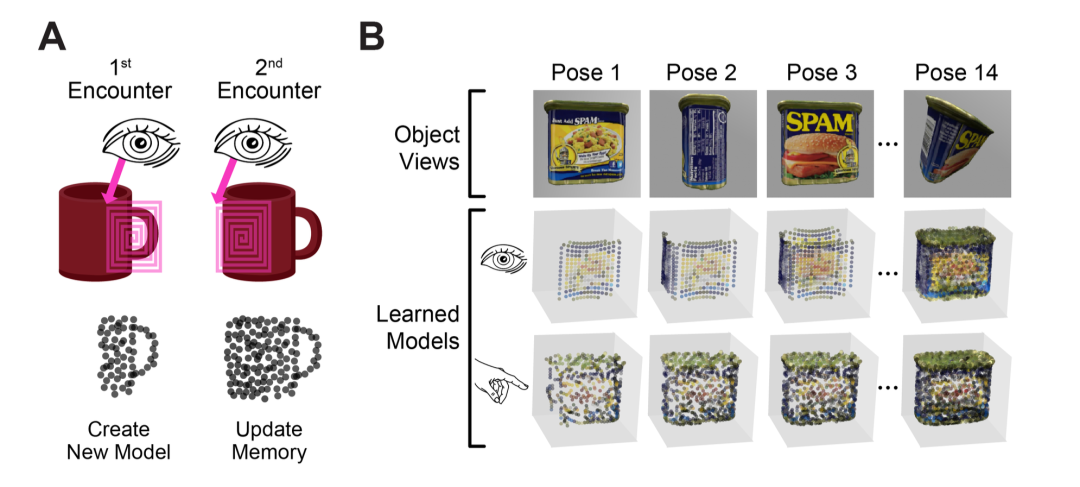
▷(图2:Monty的学习)
这个学习过程有几个关键特点:
1.本地化:学习只发生在当前被激活的参考框架的当前位置上,是一种类似赫布学习(Hebbian learning)的、极其简单的关联绑定。这与深度学习中需要调整全网络数百万参数的反向传播算法(back-propagation)截然不同。
2.增量式:如果Monty再次遇到同一个马克杯,但从一个新角度观察,它不会从头学习,而是在已有的参考框架模型上,添加新的观测点,不断完善模型。
3.监督信号的巧用:在论文的实验中,为了定量评估,Monty采用了监督学习。在学习阶段,系统被告知正在看的是“马克杯”以及它的朝向。这个信息的作用,仅仅是帮助Monty将所有观测数据正确地整合到“马克杯”这同一个参考框架中。在无监督的真实世界里,系统需要自己推断出“这是一个连贯的物体”。
通过这种方式,Monty将大脑皮层的核心工作原理——通过运动构建结构化世界模型——转化为了具体的算法和代码。那么,这个“人造大脑皮层”的表现究竟如何?它是否真的拥有生物智能的那些宝贵特质?
前面我们绍了Monty系统如何通过模仿大脑新皮层来学习和理解世界。现在,让我们深入其背后,揭开驱动这一切的数学公式的神秘面纱。这些公式不仅是代码的蓝图,更是“千脑智能理论”思想的精确表达。



论文的后续部分,通过一系列精心设计的实验,全方位地检验了Monty的能力。结果不仅令人信服,甚至在某些方面超越了预期。
(1)表现一:坚不可摧的鲁棒推理
推理,就是识别已知物体的过程。Monty的推理方式也和学习一样,是一个主动的、动态的过程。当一个未知物体出现时,Monty的学习模块(LM)会同时激活所有已知物体的模型,并提出成千上万个假设,比如:
每个假设都有一个“证据值”。接着,Monty开始移动它的传感器。如果下一步的“感官-运动”序列(比如:我向右移动了1厘米,感知到了一个平坦表面)与“马克杯”模型的预测相符,那么关于马克杯的假设证据值就会增加;反之,与“碗”和“高尔夫球”模型的预测不符,它们的证据值就会下降。
通过一连串的移动和验证,错误的假设被迅速排除,正确的假设脱颖而出。这就像在一个物体的三维地图上进行定位,最终确定“你在这里”。
实验结果1:对噪声和新视角的免疫力
研究人员对Monty进行了“压力测试”(图3D)。他们向传感器数据中注入噪声(比如位置信息的随机抖动),或者从Monty在学习阶段从未见过的全新角度来呈现物体。

▷(图3:鲁棒性感知运动推理)
结果令人惊叹。在基准测试中,Monty的物体识别准确率高达98.6%,姿态估计(判断物体的朝向)的中位数误差为0度。在加入噪声、采用全新旋转角度,甚至两者结合的恶劣条件下,Monty的性能仅有轻微下降。
最极端的测试是,研究者将所有物体的所有部分的颜色信息都强制设置为同一种蓝色,完全剥夺了纹理线索。在这种情况下,许多形状相似的物体(比如不同样式的杯子)对人类来说都难以分辨。即便如此,Monty依然达到了 73.1%的识别准确率。
这雄辩地证明了,Monty的识别能力主要依赖于它所建立的物体三维结构模型(shape),而不是表面的颜色或纹理(texture)。这与人类的视觉认知偏好高度一致,却与深度学习模型形成了鲜明对比——后者已被证明严重依赖纹理,这也是它们容易被对抗性攻击欺骗的原因之一。
实验结果2:对形状和对称性的深刻理解
Monty对形状的理解有多深刻?研究者向它展示了10种可以被人类归为“餐具”、“盒子”、“杯子”的物体。通过分析Monty在识别过程中内部假设的相似度,他们绘制了一张聚类图(见下图4A)。
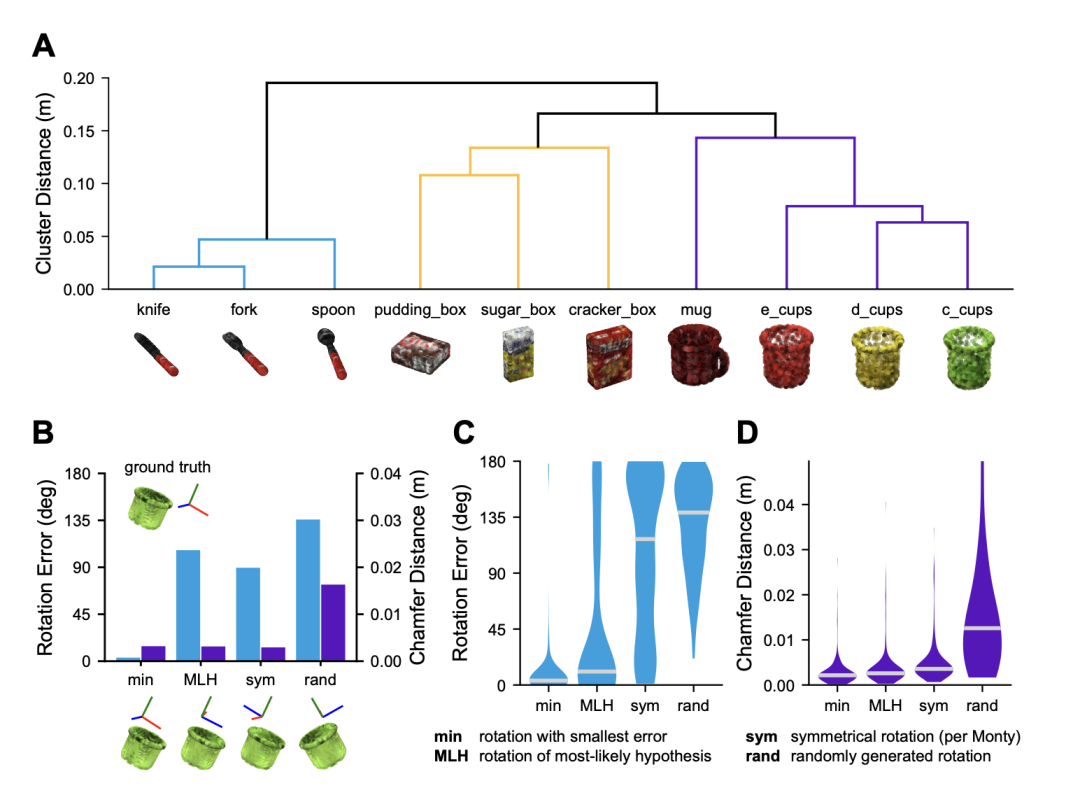
▷图4:结构化对象表征与对称性
结果清晰地显示,Monty自发地将刀、叉、勺聚在一起,将各种盒子聚在一起,将各种杯子聚在一起。它正确地识别出了这些物体在形态学上的分组,尽管它从未被教过这些类别概念。
更令人称奇的是,Monty自然而然地学会了处理对称性(symmetry)。当面对一个对称物体(比如一个圆柱形的罐头)时,它在探索后会发现,从某些不同角度观察,得到的感知运动体验是完全无法区分的。这时,它不会强行选择一个“正确”的姿态,而是会报告:“这个物体存在一组对称姿态”。论文中称之为“感知运动对称”(Sensorimotor Symmetric, SMS)。
这种对对称性的内在理解,是许多AI系统难以企及的。它意味着Monty能够以一种更高效、更抽象的方式来表征世界,避免了在等效的姿态上浪费计算资源。
(2)表现二:闪电般的快速推理
生物智能不仅要准,还要快。Monty通过两种方式实现了快速推理:智能的运动策略和高效的并行“投票”。
实验结果3:会“思考”的动作——模型指导的策略
随机的移动虽然能探索物体,但效率低下。Monty可以采用更智能的策略。
无模型策略(Model-Free Policy):这是一种基于当前感官输入的、类似本能的策略。例如,当传感器接触到物体表面时,它会有一种沿着表面锐利边缘或高曲率区域移动的“癖好”,这能让它更快地找到物体的关键特征。
基于模型的策略(Model-Based Policy):这是Monty的杀手锏,被称为“假设检验策略”(hypothesis-testing policy)。当Monty对两个或多个假设举棋不定时(比如,“这到底是叉子还是勺子?”),它不会盲目移动。它的学习模块(LM)会在“脑中”进行推演:它比较叉子和勺子的三维模型,找到两者差异最大的地方——显然是尖端部分。然后,它会生成一个目标,直接驱动传感器移动到那个最能提供区分性信息的位置(图5C-F)。
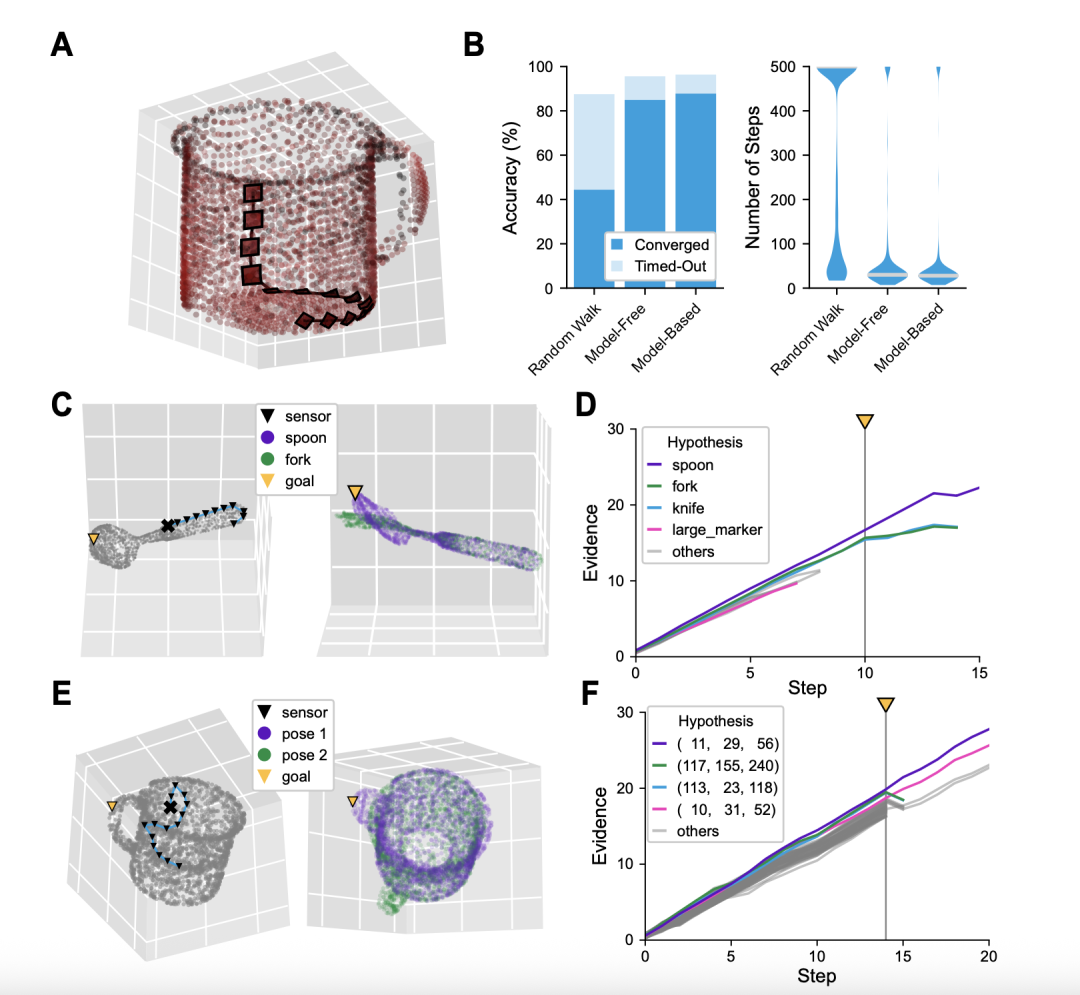
▷(图5:无模型与基于模型策略的快速推理)
这不再是简单的感知,而是一种主动的、有目的的探究行为。它像一个真正的科学家,为了验证假设而设计并执行关键实验。这种能力使得Monty能够极快地解决模糊性,收敛到正确答案。
实验结果4:千脑协同——“投票”的力量
现在,我们终于来到了“千脑”的核心。如果 Monty不只有一个学习模块(LM),而是有多个(比如16个),分别连接到传感器的不同区域(模拟视网膜上的多个感受野),会发生什么?
它们会进行“投票”(voting)。
但这并非简单的“少数服从多数”。Monty的投票机制同样是基于空间和结构的。假设LM1感知到了杯柄,它会向其他LM广播一条信息,这条信息不仅仅是“我认为这是个杯子”,而是更精确的:“根据我的模型,我正处于杯柄位置。考虑到我们之间的相对位移,LM2你应该在杯壁上,LM3你应该在杯沿上……”
接收到投票的LM会检查这些预测是否与自己的感知相符。如果相符,相关假设的证据值就会飙升。这种基于空间一致性的投票,使得所有 LM能够以惊人的速度达成共识(图6)。
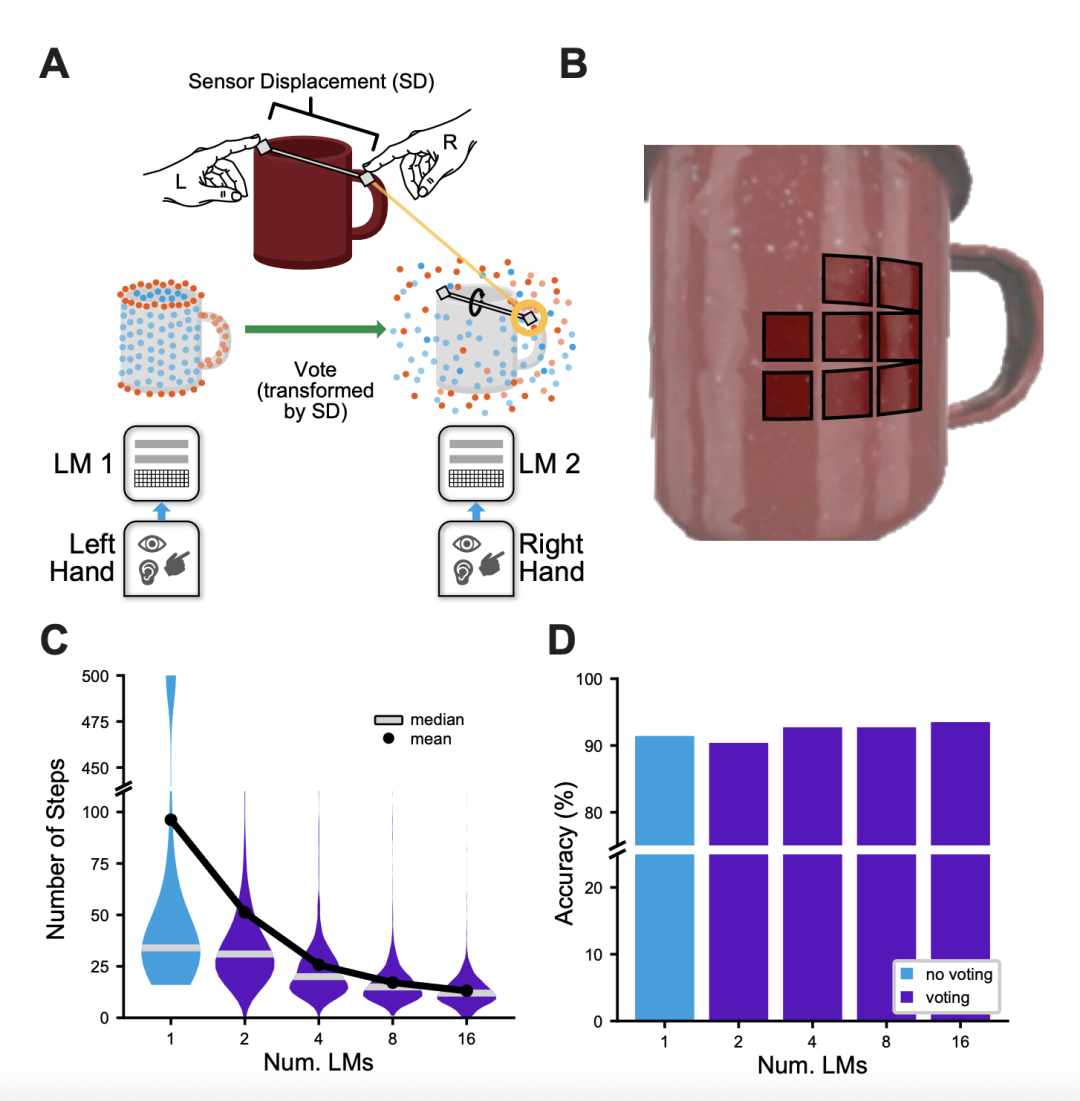
▷图6:基于投票的快速推理
实验显示,当LM数量从1增加到16时,Monty 达到收敛所需的平均步数从100多步锐减到不足20步,而准确率保持不变。这完美地诠释了“千脑”的力量:通过大量简单模块的并行协作,实现远超单个模块的效率和速度。
(3)表现三:极致的高效学习
如果说Monty在推理上的表现已经足够亮眼,那么它在学习上的表现则堪称颠覆性。
实验结果5:告别数据饥渴——小样本学习(Few-Shot Learning)
研究者比较了Monty和强大的视觉大模型 Vision Transformer(ViT)在学习YCB数据集时的效率。他们控制了每个物体向模型展示的“视角”(旋转角度)数量。
结果(图7A)显示:
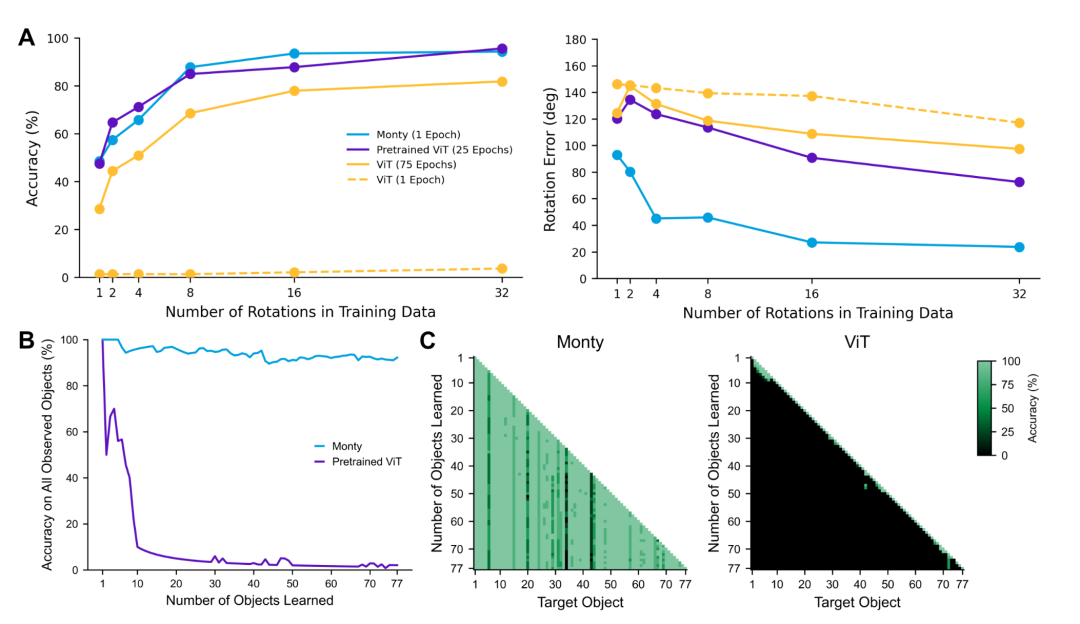
▷(图7:小样本学习和持续学习)
Monty的学习效率为何如此之高?因为它采用了本地化的、关联式的学习规则。每一次观察都只是在对应参考框架的对应位置上,建立一个简单的连接。它不需要通过复杂的梯度计算和全局优化来寻找解决方案。
实验结果6:终身学习的圣杯——持续学习(Continual Learning)
这或许是Monty最重要的能力之一。研究者设计了一个残酷的持续学习任务:让模型一个接一个地学习77种物体。每学习一个新物体,就测试它对所有已学物体的识别能力。
结果(图7B、7C)是压倒性的:
Monty能够持续学习的秘诀,正在于它的模块化和本地化学习。学习一个新物体,本质上是启用一个新的学习模块(或参考框架),在这个“新大脑”里建立模型,而不会去干扰那些已经存有旧知识的“老大脑”。
实验结果7:令人难以置信的计算效率
最后,研究者计算了学习过程中的计算成本,以浮点运算次数(FLOPs)来衡量。
结果(图8A)足以让任何从事AI工程的人感到震惊:
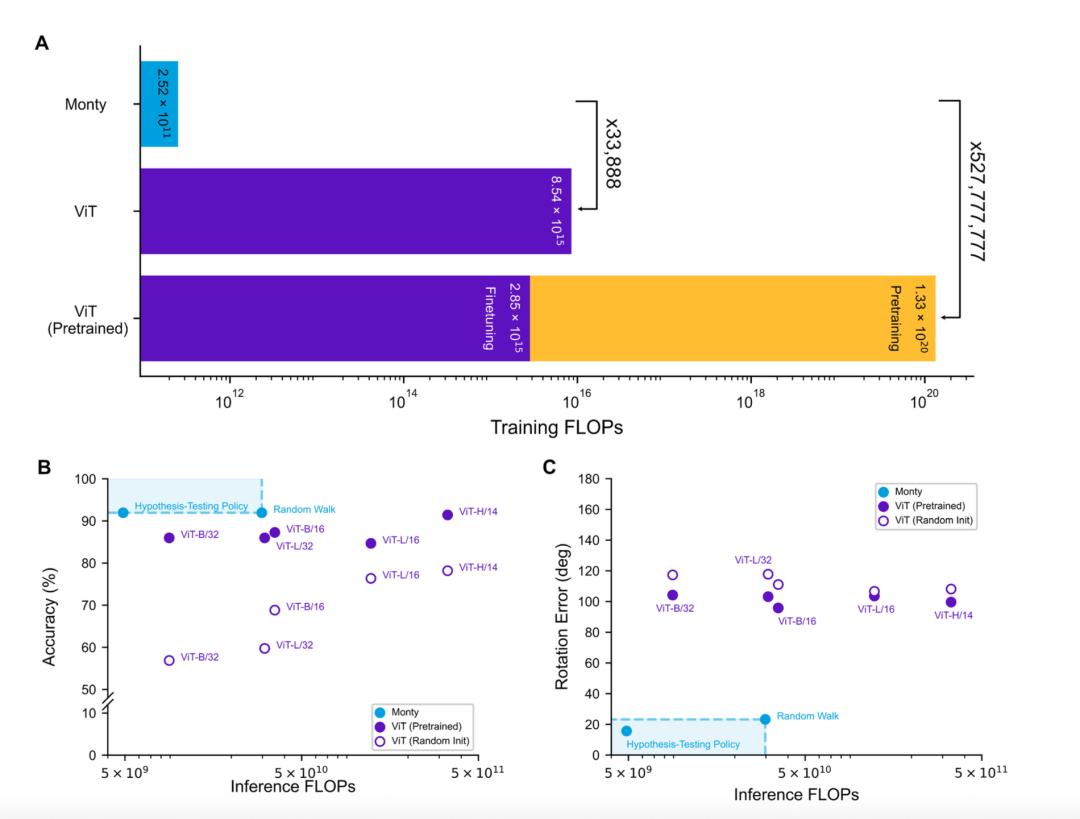
▷图8:学习与推理的计算效率
是的,你没有看错,是“亿”倍。这源于两者学习机制的根本不同。深度学习的“蛮力”——通过对海量数据进行全局、迭代的优化——在计算上是极其昂贵的。而Monty所代表的生物智能的“巧劲”——通过本地化的、一次性的关联来构建结构化模型——则表现出无与伦比的效率。
真正的通用智能,也许并不在机房的轰鸣中,而在一只饥饿小鼠嗅着奶酪的静默里。
回到我们最初的问题。Monty的一系列实验结果,强有力地回应了当前AI面临的挑战。它证明了,一个基于大脑新皮层工作原理构建的系统,可以:
这不仅仅是一次技术上的成功,更是一次思想上的胜利。它告诉我们,通往通用人工智能的道路可能不止一条。除了将现有深度学习模型越做越大、越喂越多的“暴力美学”之路,还存在着一条更精巧、更高效、更接近生命本质的“仿生美学”之路。
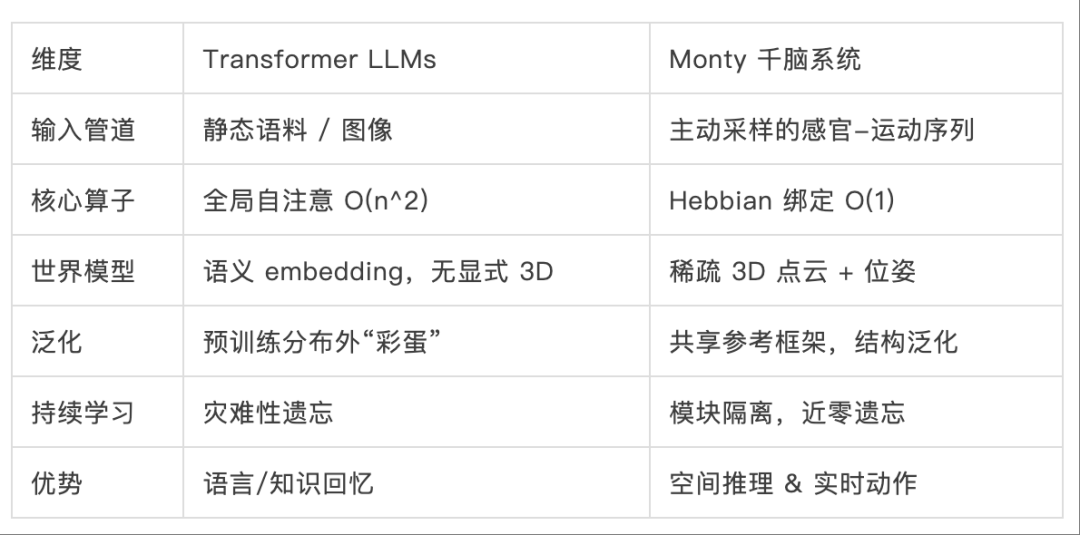
▷表2:暴力美学 vs 仿生美学
当然,正如论文作者所坦言,Monty仍处于发展的早期阶段。它目前还局限于三维物体感知,尚未涉及更复杂的任务,如理解动态事件、进行层级化的组合推理(比如将“轮子”、“车身”、“方向盘”组合成“汽车”模型),或是在真实世界中进行无监督学习。这些都是千脑智能项目未来需要攻克的难关。
但Monty已经为我们掀开了未来的一角。在那个未来里,AI可能不再是运行在遥远数据中心里的、冰冷的庞然大物。它们可能会变得更小、更省电、更具适应性,能够被部署到机器人、自动驾驶汽车、便携医疗设备等各种终端上。它们将通过与世界的真实互动来学习,它们的智能将拥有坚实的物理基础(grounding)。
过去十年,AI的主旋律是“更大模型+更多 GPU”。杰夫·霍金斯和他的团队,则展示了另一条路线:结构先验+行动闭环,用少量高熵经历,换取高质量世界模型。Monty这样的生物智能模型提醒我们:经过数十亿年进化所塑造的大脑,至今仍然是我们探索智能奥秘最宝贵的藏宝图。
或许,创造真正智能的最佳方式,不是凭空发明,而是谦逊地去复现那个我们每个人头颅中都拥有的、由自然所造化成千上万个微小大脑所协同共现的奇迹。
参考文献:
1.Constantinescu, A. O. et al. “Grid-like code in conceptual knowledge.” Nature Neuroscience (2024).
2.Liu, Y. et al. “Dynamic remapping for interceptive actions in the superior colliculus-parietal circuit.” Nature (2024).
3.Takahashi, N. et al. “Dendritic predictive coding in the visual cortex.” Nature (2023).
4.Gallivan, J. P. & Culham, J. C. “Somatosensory and external spatial reference frames in parietal cortex.” Frontiers in Human Neuroscience (2024).
文章来自于微信公众号“追问nextquestion”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
