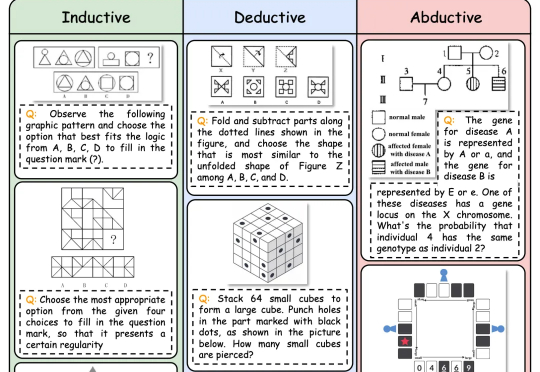
多模态推理新基准!最强Gemini 2.5 Pro仅得60分,复旦港中文上海AILab等出品
多模态推理新基准!最强Gemini 2.5 Pro仅得60分,复旦港中文上海AILab等出品逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
来自主题: AI技术研报
10101 点击 2025-06-07 10:35
 搜索
搜索
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)

首个专为ALLMs(音频大语言模型)设计的多维度可信度评估基准来了。

大语言模型(LLMs)作为由复杂算法和海量数据驱动的产物,会不会“无意中”学会了某些类似人类进化出来的行为模式?这听起来或许有些大胆,但背后的推理其实并不难理解:
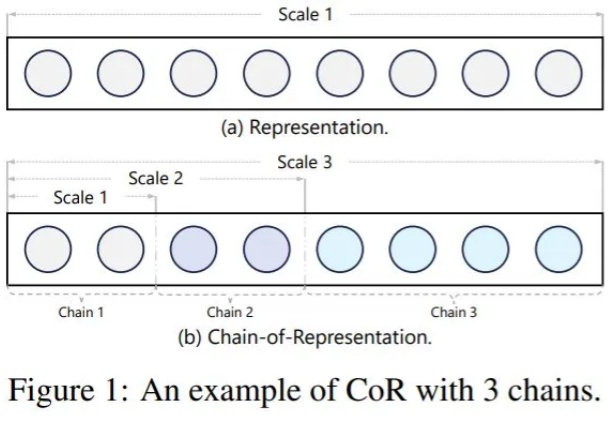
随着大语言模型 (LLM) 的出现,扩展 Transformer 架构已被视为彻底改变现有 AI 格局并在众多不同任务中取得最佳性能的有利途径。因此,无论是在工业界还是学术界,探索如何扩展 Transformer 模型日益成为一种趋势。

近年来,大语言模型(LLMs)的能力突飞猛进,但随之而来的隐私风险也逐渐浮出水面。

文章探讨AI时代深度思考的困境:大语言模型使人类思维系统萎缩,即时生成内容取代有机思考过程,削弱直觉与思辨力。作者以自身创作瓶颈为例,指出依赖AI导致认知基础流失,廉价知识无法替代深层理解,强调原始思考过程的价值,认为未经修饰的人类思考仍有独特意义。

近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。
你是否曾对大语言模型(LLMs)下达过明确的“长度指令”?
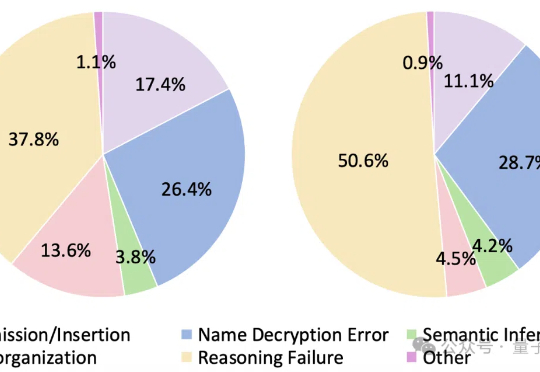
大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战: