
全面增强LLM推理/规划/执行力!北航提出全新「内置CoT」思考方法
全面增强LLM推理/规划/执行力!北航提出全新「内置CoT」思考方法基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
来自主题: AI资讯
7766 点击 2025-03-04 19:46
 搜索
搜索
基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
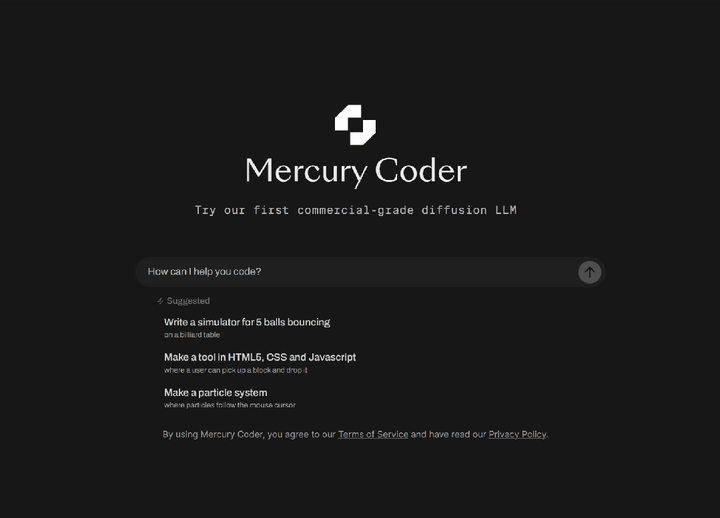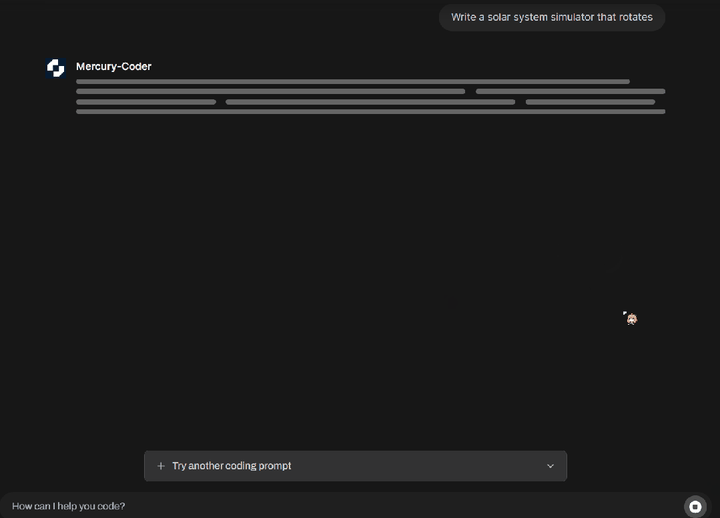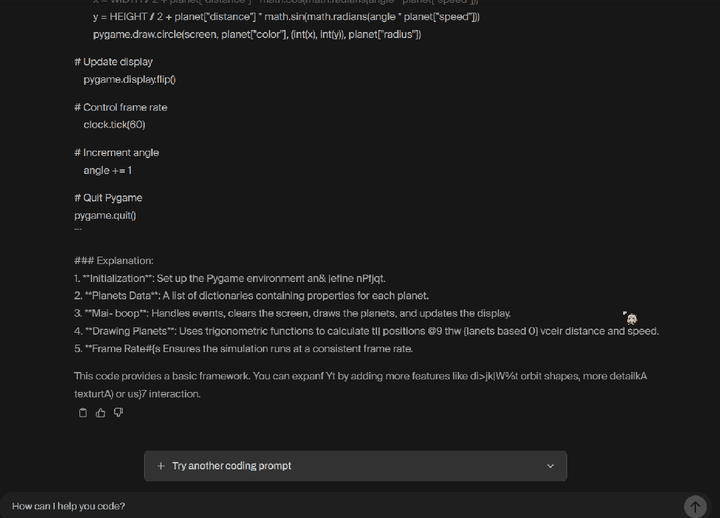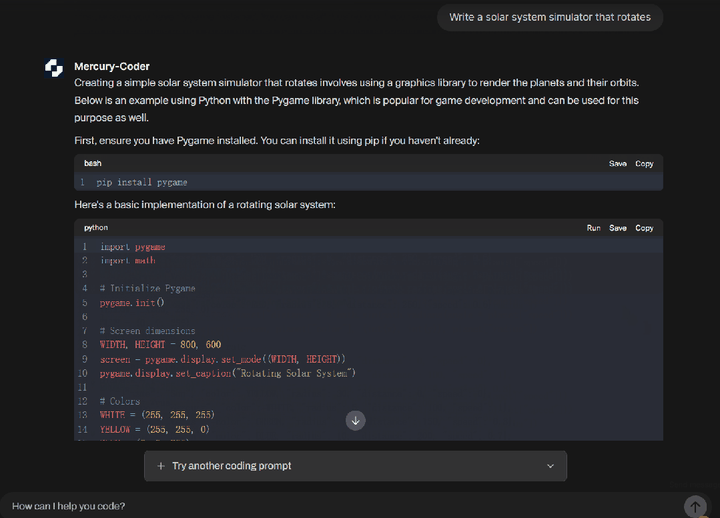
2025年2月27日,由前扩散模型领域顶尖研究者创立的Inception Labs正式发布了全球首个商业级扩散大语言模型(dLLM)——“Mercury”。这一里程碑式产品不仅在生成速度、硬件效率和成本控制上实现突破,更标志着自然语言处理技术从自回归(Autoregressive)范式向扩散(Diffusion)范式的重大跃迁。

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。

大语言模型(LLMs)在当今的自然语言处理领域扮演着越来越重要的角色,但其安全性问题也引发了广泛关注。
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

“放弃生成式模型,不研究LLM(大语言模型),我们没办法只通过文本训练让AI达到人类的智慧水平。”近日,Meta首席AI科学家杨立昆(Yann LeCun)在法国巴黎的2025年人工智能行动峰会上再一次炮轰了生成式AI。

在人工智能高速发展的今天,我们似乎迎来了一个"假设爆炸"的时代。大语言模型每天都在产生数以万计的研究假设,它们看似合理,却往往难以验证。这让我不禁想起了20世纪最具影响力的科学哲学家之一——卡尔·波普尔。
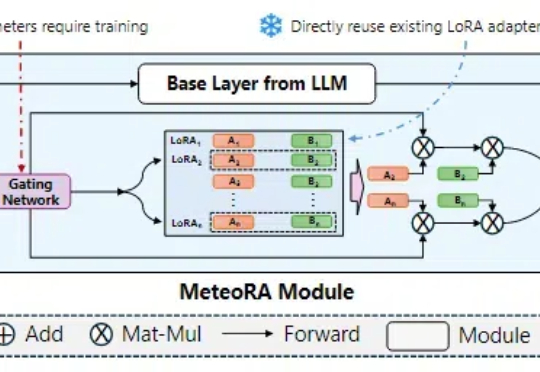
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。
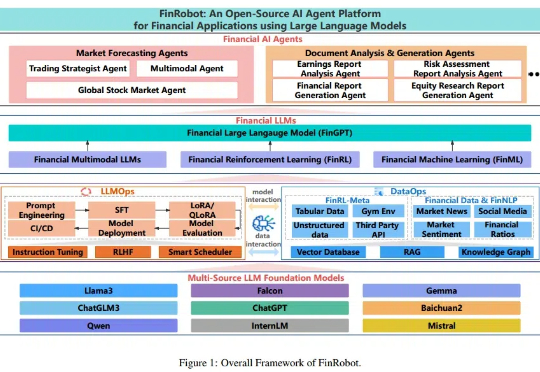
随着金融机构和专业人士越来越多地将大语言模型(LLMs)纳入其工作流程中,金融领域与人工智能社区之间依然存在显著障碍,包括专有数据和专业知识的壁垒。本文提出了 FinRobot,一种支持多个金融专业化人工智能智能体的新型开源 AI 智能体平台,每个代理均由 LLM 提供动力。