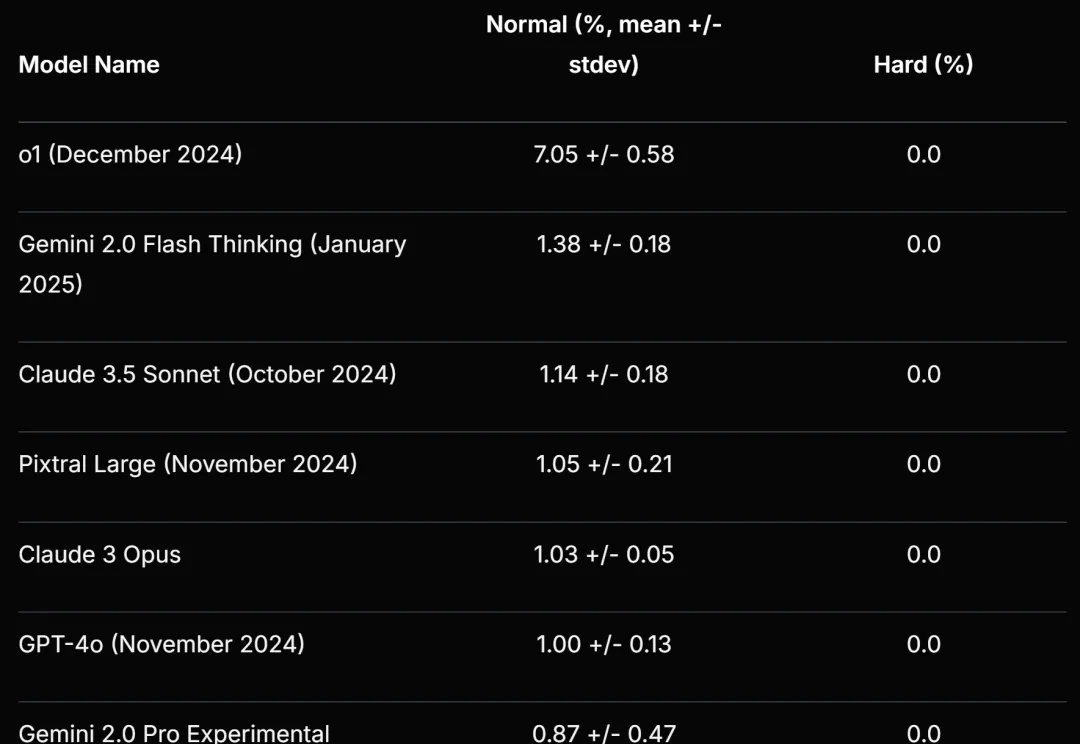
AI无法攻克的235道谜题!让o1、Gemini 2.0 Flash Thinking集体挂零
AI无法攻克的235道谜题!让o1、Gemini 2.0 Flash Thinking集体挂零Scale AI 等提出的新基准再次暴露了大语言模型的弱点。
来自主题: AI技术研报
10811 点击 2025-02-17 14:49
 搜索
搜索
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。

近年来,多模态大模型(MLLM)在视觉理解领域突飞猛进,但如何让大语言模型(LLM)低成本掌握视觉生成能力仍是业界难题!

最新大语言模型推理测试引众议,DeepSeek R1常常在提供错误答案前就“我放弃”了?? Cursor刚刚参与了一项研究,他们基于NPR周日谜题挑战(The Sunday Puzzle),构建了一个包含近600个问题新基准测试。
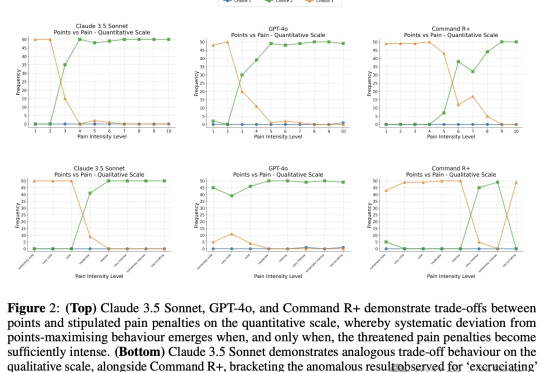
以大语言模型为代表的AI在智力方面已经逐渐逼近甚至超过人类,但能否像人类一样有痛苦、快乐这样的感知呢?近日,谷歌团队和LSE发表了一项研究,他们发现,LLM能够做出避免痛苦的权衡选择,这也许是实现「有意识AI」的第一步。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。

近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。
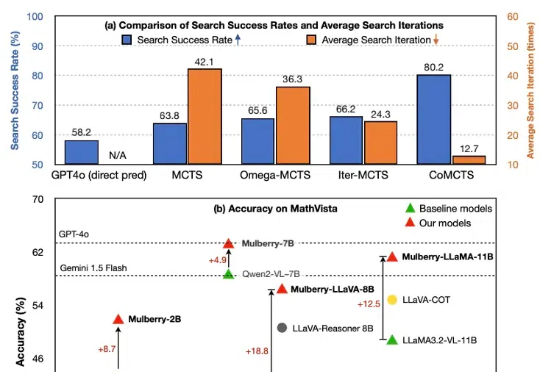
尽管多模态大语言模型(MLLM)在简单任务上最近取得了显著进展,但在复杂推理任务中表现仍然不佳。费曼的格言可能是这种现象的完美隐喻:只有掌握推理过程的每一步,才能真正解决问题。然而,当前的 MLLM 更擅长直接生成简短的最终答案,缺乏中间推理能力。本篇文章旨在开发一种通过学习创造推理过程中每个中间步骤直至最终答案的 MLLM,以实现问题的深入理解与解决。
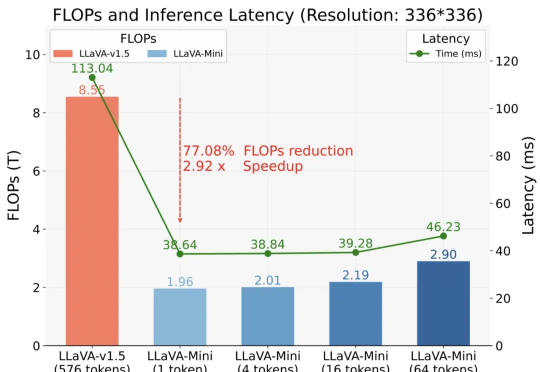
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

“垃圾进,垃圾出!”在中文互联网上,一场针对国产AI技术的恶意攻击正在悄然蔓延。某些自媒体以“污染中文互联网”为名,对DeepSeek等国产大语言模型发起了一场看似正义、实则荒谬的讨伐。他们将“幻觉”这一技术术语污名化,试图用莫须有的罪名抹黑国产AI的进步。