ICML 2026|告别「单线程」思维,智能体进化出了原生的并行推理大脑
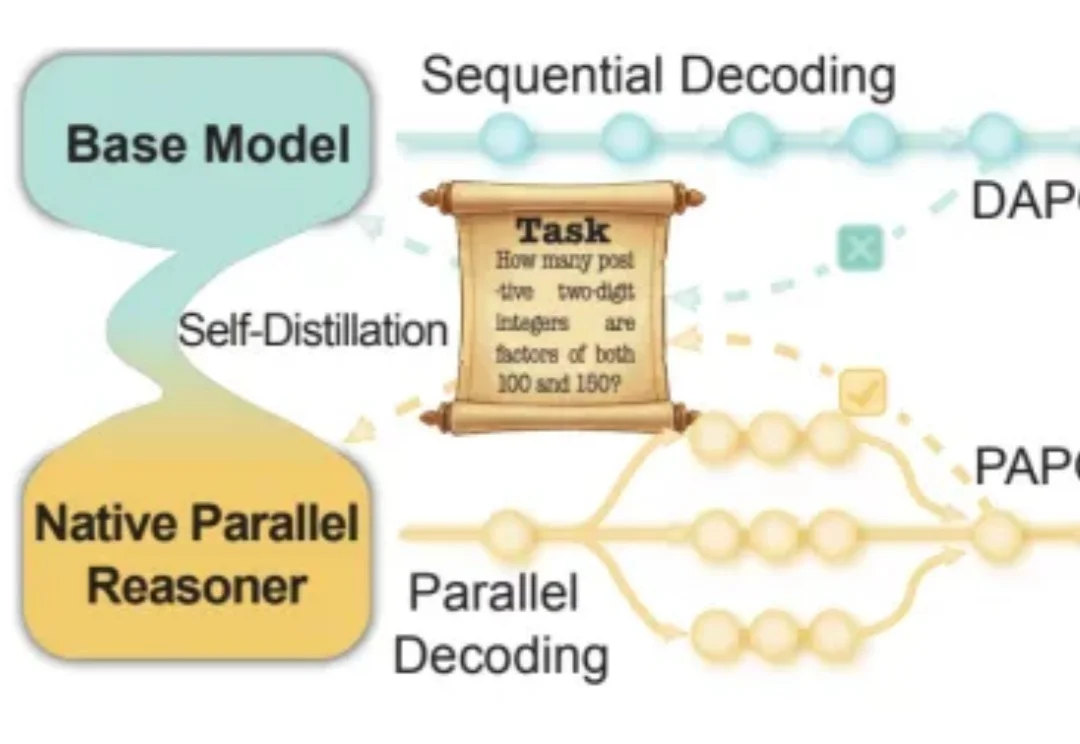
ICML 2026|告别「单线程」思维,智能体进化出了原生的并行推理大脑近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。
来自主题: AI技术研报
9901 点击 2026-05-19 10:01