OpenAI科学家Noam Brown:AI的真正上限,可能根本没人测得起
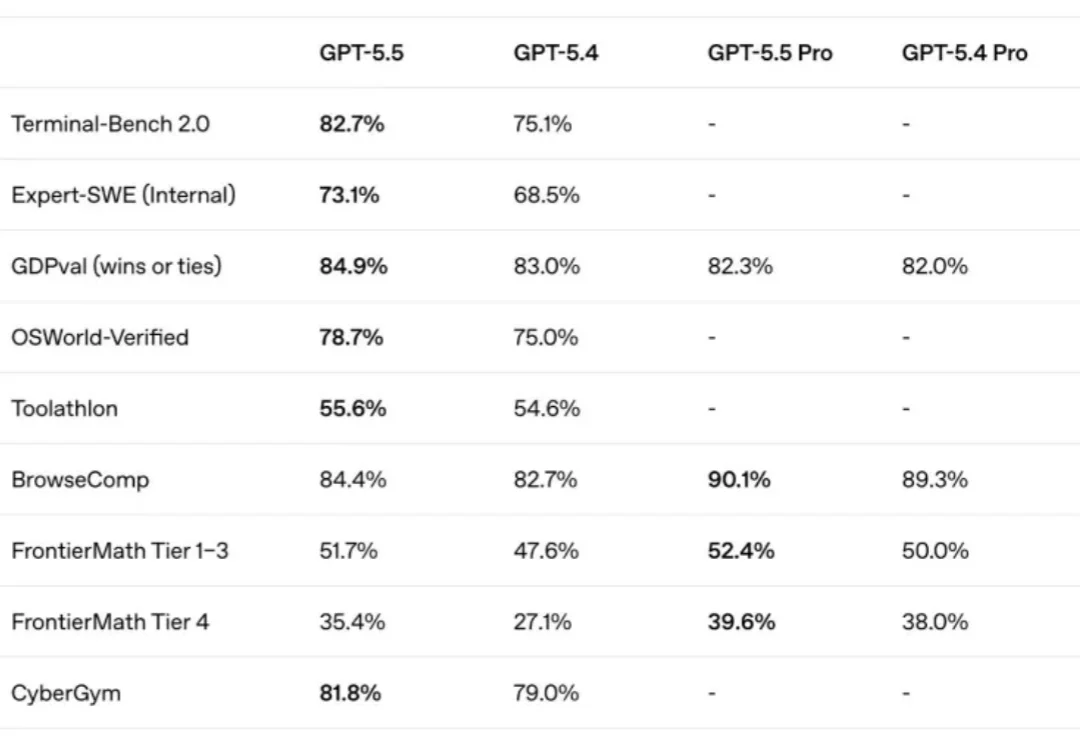
OpenAI科学家Noam Brown:AI的真正上限,可能根本没人测得起随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。
来自主题: AI资讯
6995 点击 2026-06-10 15:16
 搜索
搜索
随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。

今天,“港股AGI第一股”云知声发布其最新通用大语言模型U2,该模型是由云知声自研的、基于快慢思考融合的MoE(混合专家)范式构建的通用大语言模型。U2跳出了传统大模型盲目堆参数、堆Token的内卷路径,实现了“小参数强能力、少Token高产出、低算力低成本”的进化。
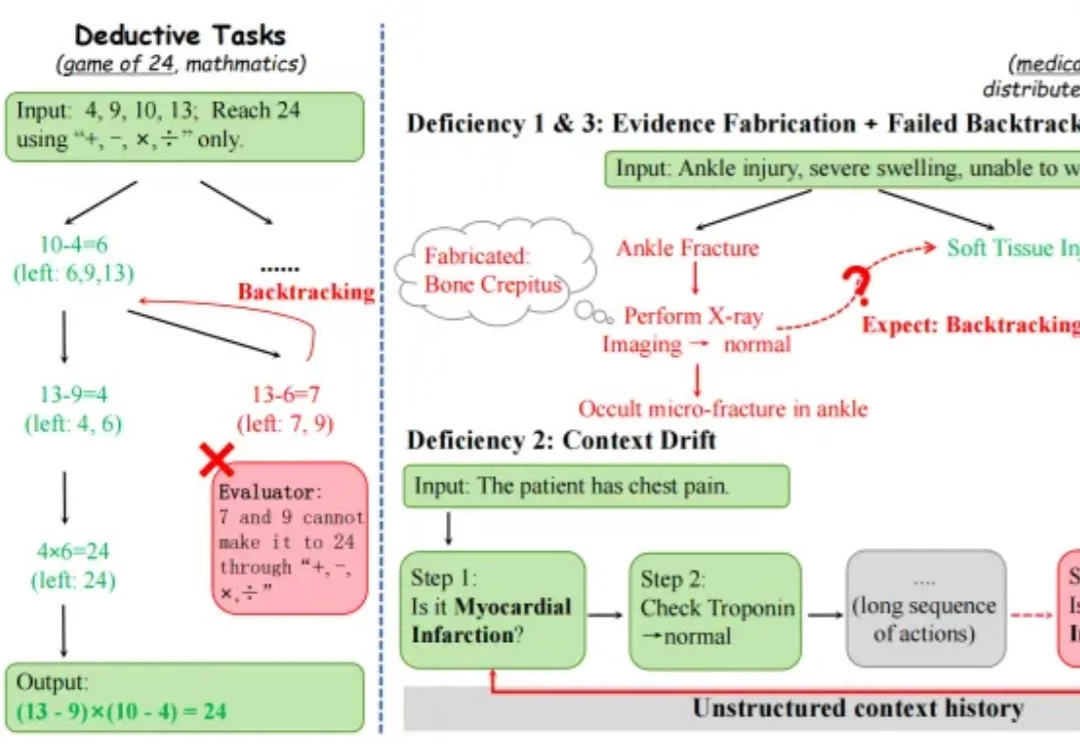
近年来,大语言模型在数学、代码等任务上的表现不断刷新上限,但到了医疗诊断、故障排查这类真实世界任务里,真正困难的是让多个智能体在不确定的动态环境中持续协作推理。
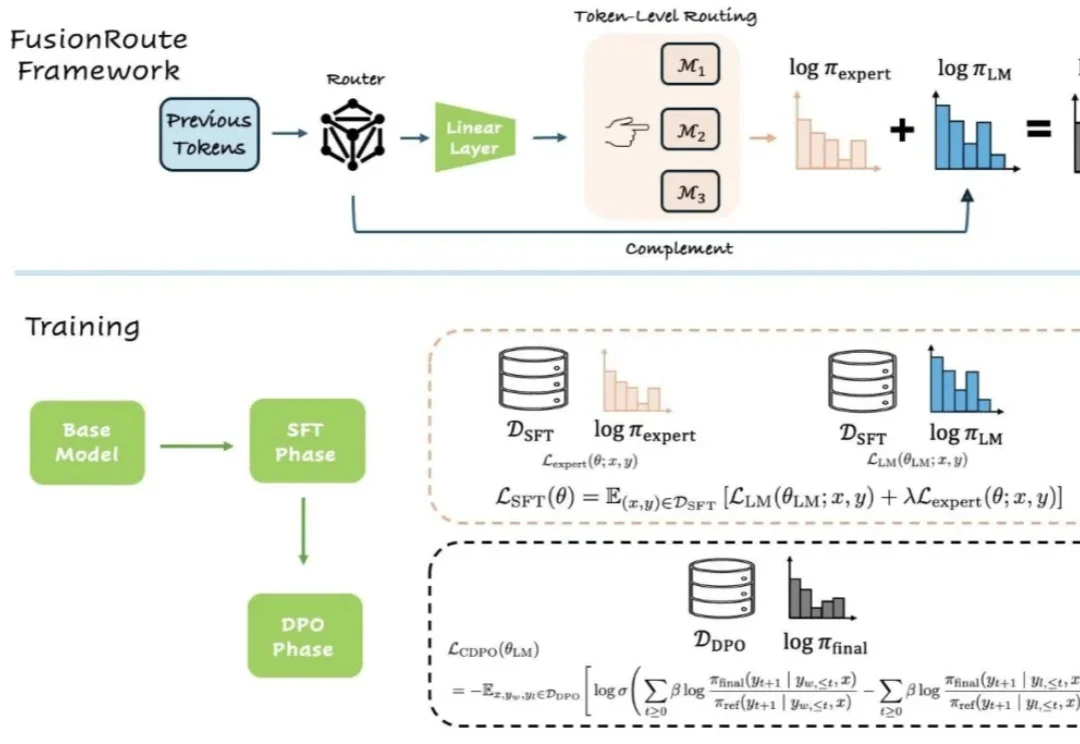
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。
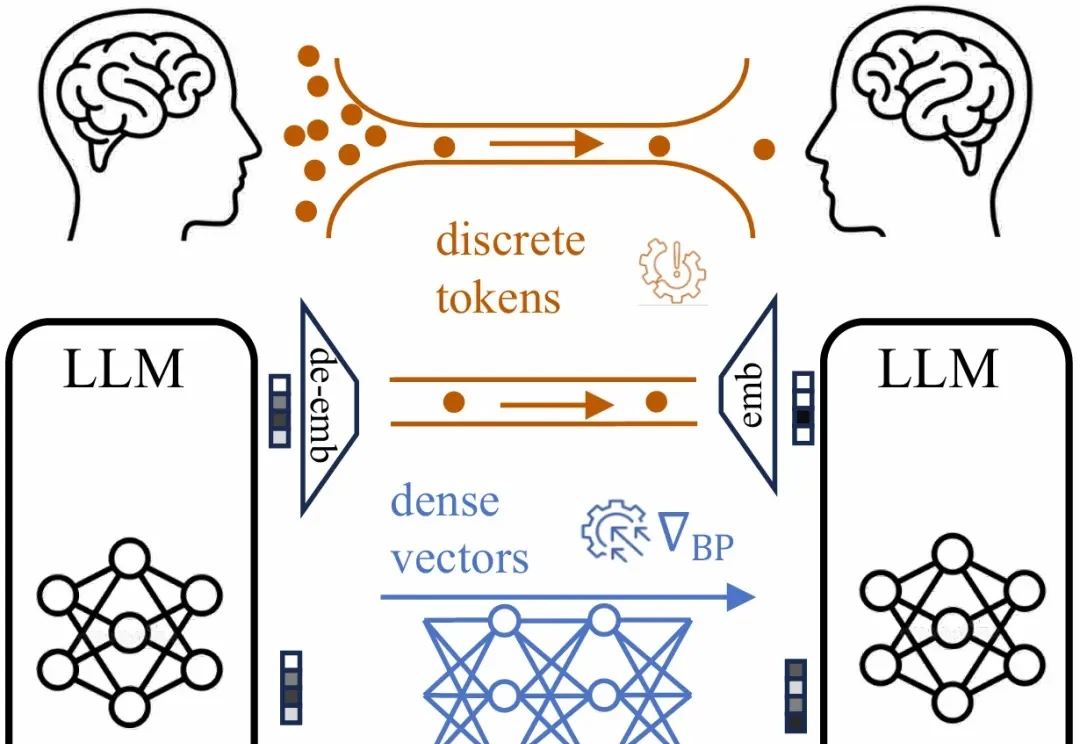
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。

Zig 由一家非营利组织以及一批贡献者共同维护。任何程序员都可以向它的代码仓库提交代码,只要遵守项目的行为准则。规则之一就是:禁止提交 AI 辅助生成的代码。政策写得很清楚:不接受任何由大语言模型生成的内容,也不接受由大语言模型改写、润色、编辑、头脑风暴或调试过的内容。简单来说,就是让 AI 离 Zig 的代码贡献远一点。
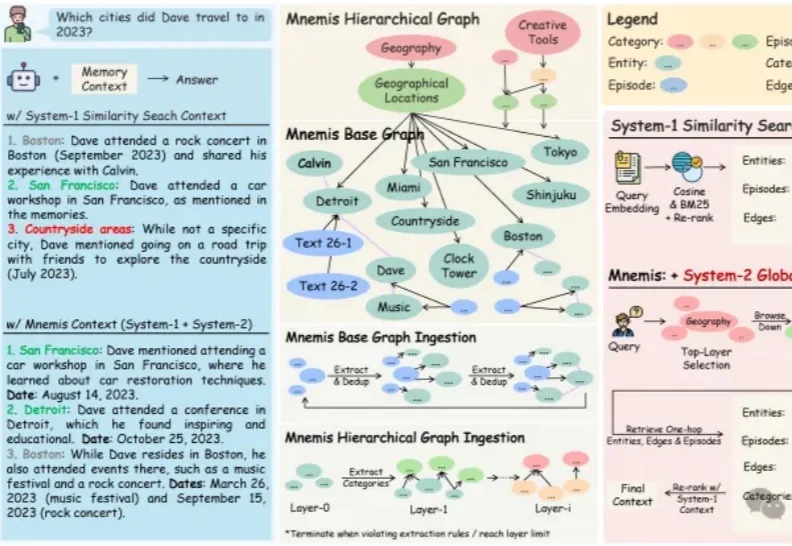
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。
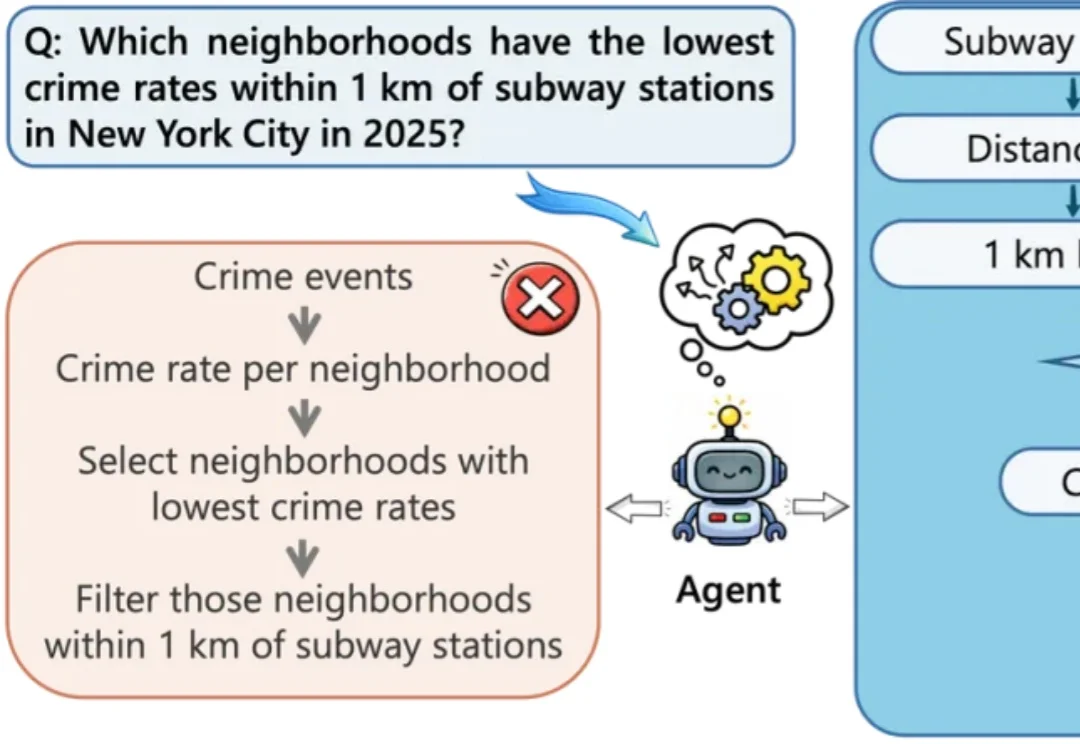
大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。

英伟达提出了全球首个三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。

大语言模型真的只能走“预测下一个token”的路子吗?