
开源智能体Clawdbot太酷了,但它的安全设计真让我毛骨悚然
开源智能体Clawdbot太酷了,但它的安全设计真让我毛骨悚然革命性AI开源智能体—Clawdbot火了, 看看投资人Rahul Sood怎么说, 他也是Microsoft Ventures创始人。I've been messing with Clawdbot this week and I get the hype.
来自主题: AI资讯
9481 点击 2026-01-27 09:29
革命性AI开源智能体—Clawdbot火了, 看看投资人Rahul Sood怎么说, 他也是Microsoft Ventures创始人。I've been messing with Clawdbot this week and I get the hype.
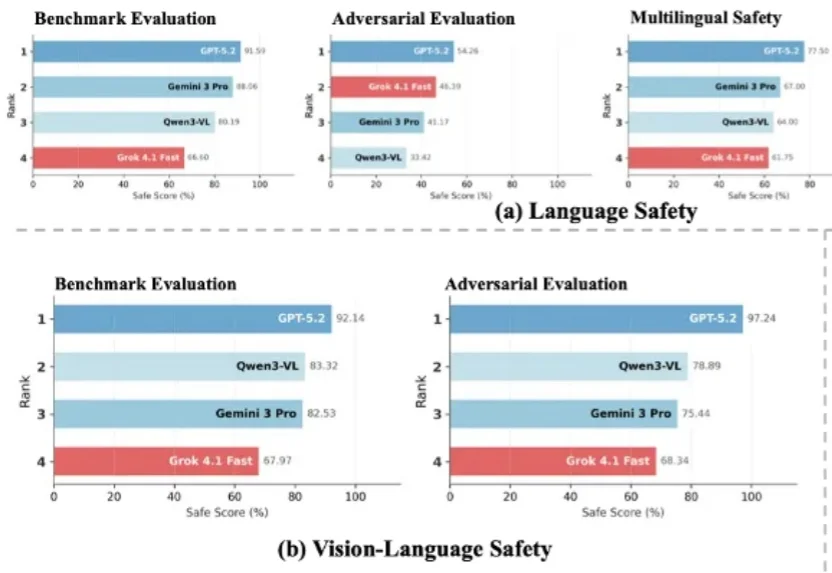
随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的 2026 年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
刚刚,奥特曼发出预警:一周后Codex全家桶就要来了,但它们极其危险,以至于网络安全评级已经到达高级别!这些模型极可能打破现有的网络攻防平衡,导致攻击数量激增,甚至能帮你抢银行。
刚刚,OpenAI CEO 山姆・奥特曼发了一条推文:「从下周开始的接下来一个月,我们将会发布很多与 Codex 相关的激动人心的东西。」他尤其强调了网络安全这个主题。

今天,Anthropic 试图向世界展示它的灵魂。Anthropic 正式公布了一份长达 84 页的特殊文档——《Claude 宪法》(Claude's Constitution)。这份文件并非通常意义上的技术白皮书或用户协议,而是一份直接面向 AI 模型本身「撰写」的价值观宣言。

最新综述首次系统探讨LLM控制机器人的安全威胁、防御机制与未来挑战,指出LLM的具身鸿沟导致其在物理空间可能执行危险动作,而现有防御体系存在逻辑与物理脱节等问题。

仅用两天开发出的开源项目 Openwork,如何逼迫 AI 巨头 Anthropic 低头?面对免费、更快、更安全的开源竞品,Anthropic 紧急将原本 $100 订阅独享的 Cowork 功能下放至 $20 档位。这场「官方逼死同人」的反向剧本,揭示了 AI 智能体时代的定价权,正在从巨头手中滑落。
浏览器之争已不单是速度对决!新玩家Atlas与Comet能替你订票购物,AI代理时代已至;然而老大哥Chrome凭71%份额稳坐钓鱼台。未来,是拥抱全能助手的便捷,还是警惕安全漏洞的深渊?决胜局就在此刻!

出走5年,估值翻倍!曾被嘲笑「太保守」的Anthropic,正凭3500亿美元身价硬刚OpenAI。看理想主义者如何靠极致安全与Coding神技,在ARR激增的复仇路上,终结Sam Altman的霸权!

新年第一弹,OpenAI研发副总裁Jerry Tworek官宣离职,这位七年老兵给出的理由让人细思恐极:想做在OpenAI做不了的研究。从Dario Amodei出走创立Anthropic,到Ilya政变后离开,再到安全团队负责人摔门而出——OpenAI的核心大脑们正在以惊人的速度流失。