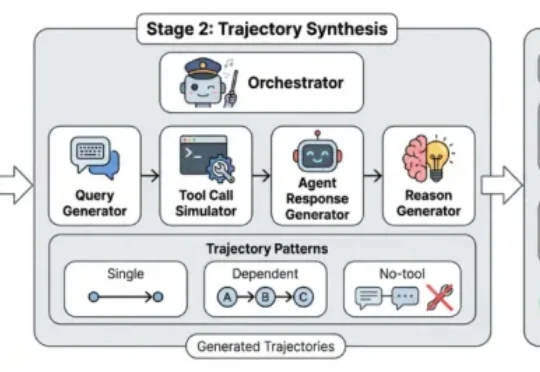
ICLR 2026 | 在Moltbook之外,上交大联合上海AI Lab模拟了AI原⽣社交的「真实暗⾯」
ICLR 2026 | 在Moltbook之外,上交大联合上海AI Lab模拟了AI原⽣社交的「真实暗⾯」本⽂的主要作者来⾃上海交通⼤学和上海⼈⼯智能实验室,核⼼贡献者包括任麒冰、郑志杰、郭嘉轩,指导⽼师为⻢利庄⽼师和邵婧⽼师,研究⽅向为安全可控⼤模型和智能体。 最近,Moltbook 的爆⽕与随后的迅速
来自主题: AI技术研报
10177 点击 2026-02-11 12:32