
360开源高质量图文对齐数据集!收纳1200万张图像+1000万组细粒度负样本,让模型告别“图文不符”
360开源高质量图文对齐数据集!收纳1200万张图像+1000万组细粒度负样本,让模型告别“图文不符”如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。
来自主题: AI技术研报
10465 点击 2025-06-02 15:17
 搜索
搜索
如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。

刚刚发布的Claude 4被发现,它可能会自主判断用户行为,如果用户做的事情极其邪恶,且模型有对工具的访问权限,它可能就要通过邮件联系相关部门,把你锁出系统。这事儿,Anthropic团队负责模型对齐工作的一位老哥亲口说的。

在多模态大模型快速发展的当下,如何精准评估其生成内容的质量,正成为多模态大模型与人类偏好对齐的核心挑战。然而,当前主流多模态奖励模型往往只能直接给出评分决策,或仅具备浅层推理能力,缺乏对复杂奖励任务的深入理解与解释能力,在高复杂度场景中常出现 “失真失准”。

最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。

作为一家公司,我们专注于三件事:预训练、微调和对齐。我们使用自有数据集进行预训练,这一点非常关键,而很多公司并不具备这样的能力。然后,我们用专家手工整理的数据进行微调。最有趣、最重要的部分在于对齐,这与简单地寻找“当前最优解”是截然不同的。
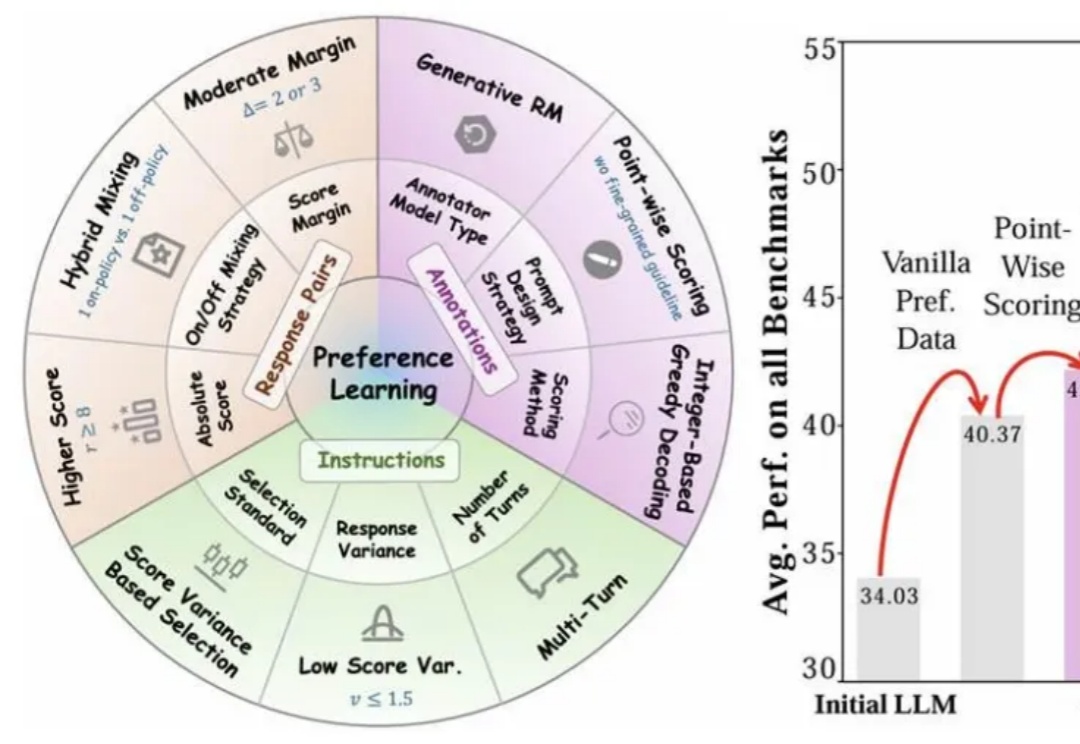
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
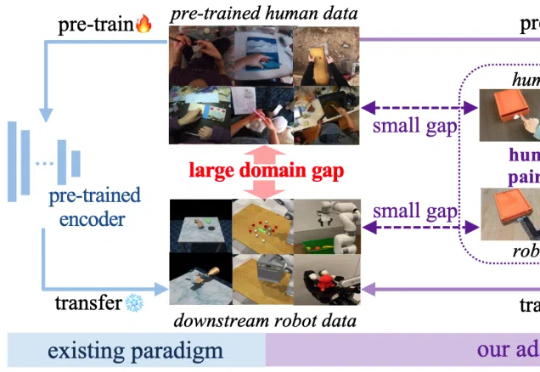
“让机器人看懂世界、听懂指令、动手干活”正从科幻走向现实。
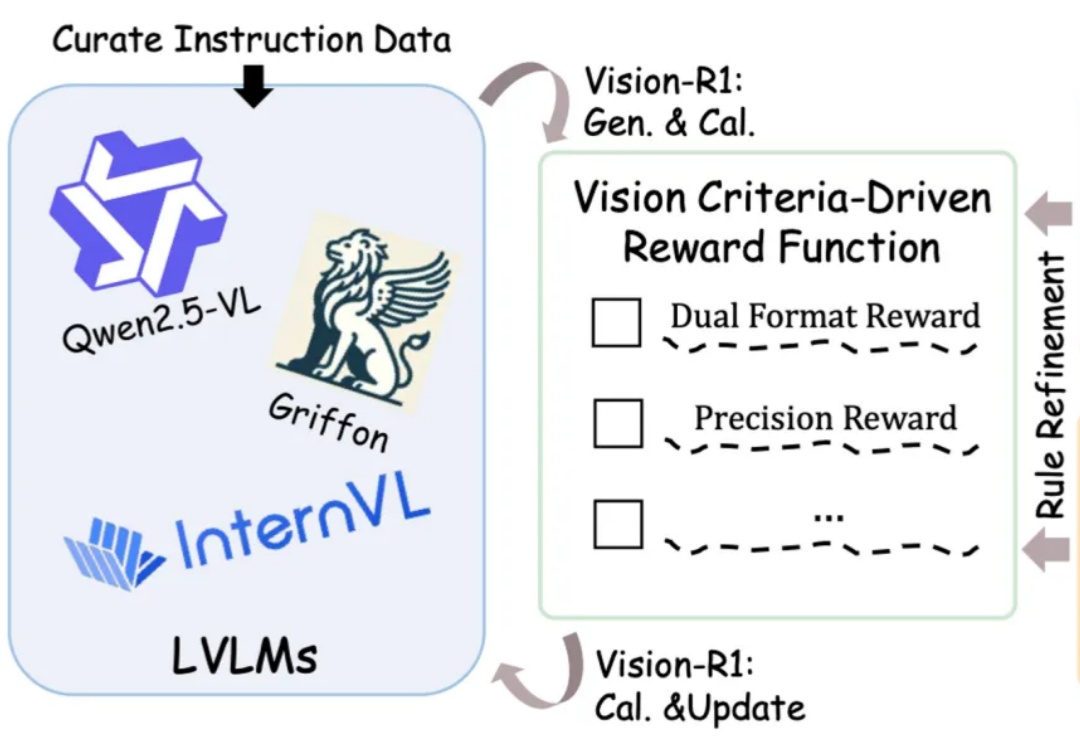
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
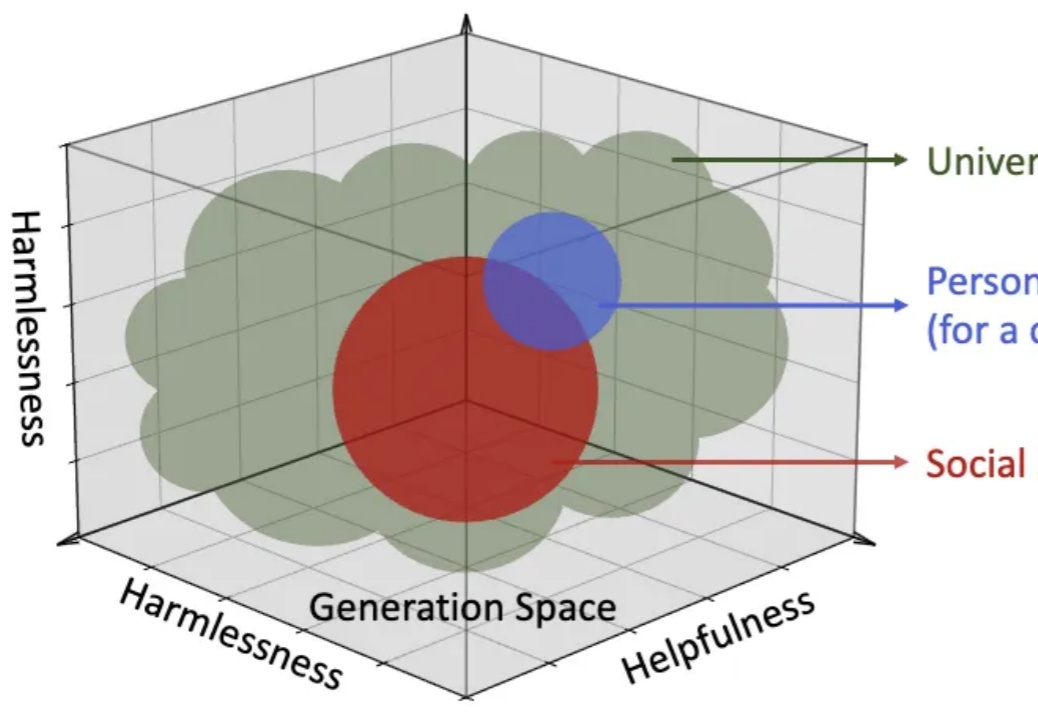
如何让大模型更懂「人」?
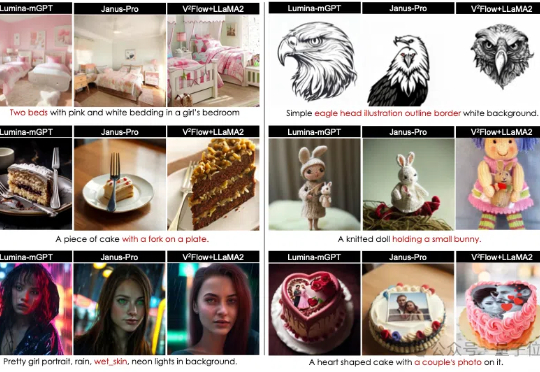
视觉Token可以与LLMs词表无缝对齐了!