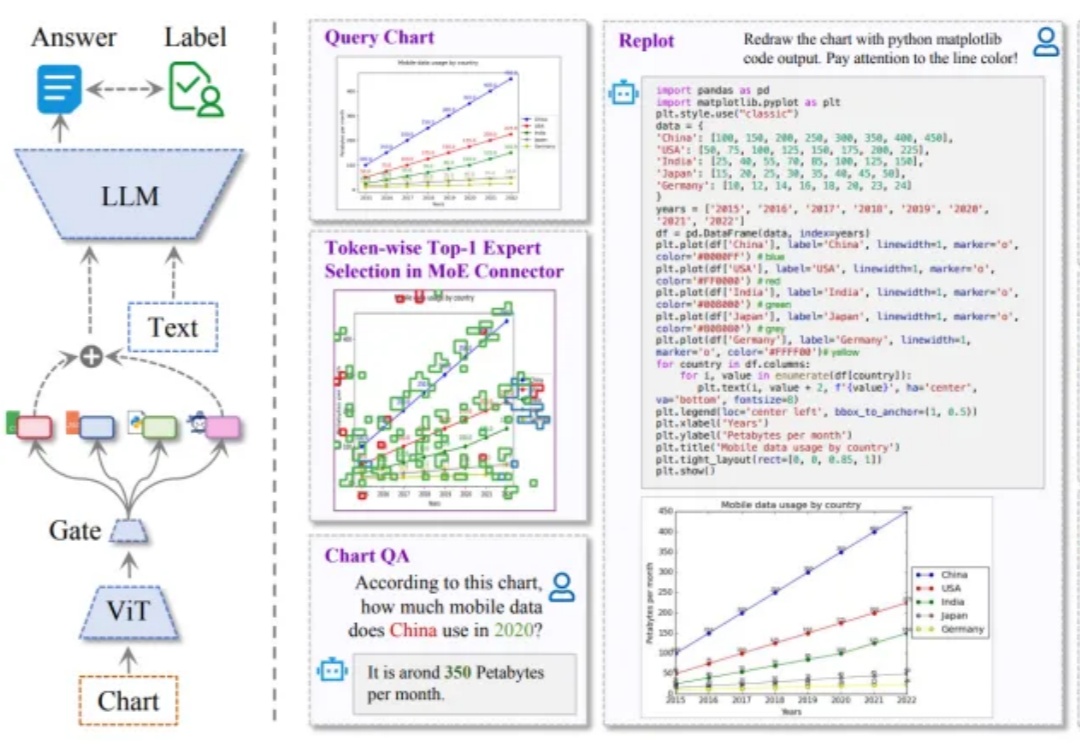
ICLR 2025 Oral | IDEA联合清华北大提出ChartMoE:探究下游任务中多样化对齐MoE的表征和知识
ICLR 2025 Oral | IDEA联合清华北大提出ChartMoE:探究下游任务中多样化对齐MoE的表征和知识最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%
来自主题: AI技术研报
5880 点击 2025-04-01 15:27