拒绝成为落后的开发者:用TRAE Skills构建你的10倍效能工具箱
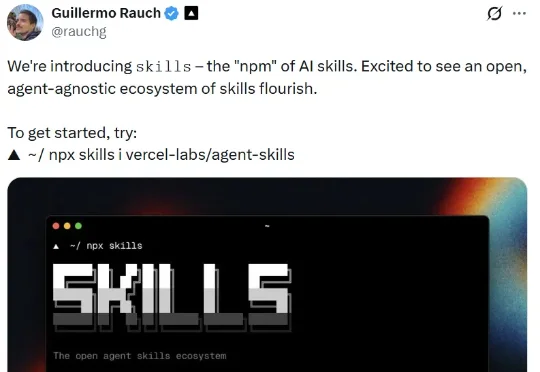
拒绝成为落后的开发者:用TRAE Skills构建你的10倍效能工具箱比如前些天,Vercel 创始人 Guillermo Rauch 推出了所谓的「AI skill 的 npm」,让用户仅需一个简单命令 npx skills add [package],就能为自己的 AI 智能体轻松注入专业能力。
来自主题: AI资讯
12057 点击 2026-01-22 12:36
 搜索
搜索
比如前些天,Vercel 创始人 Guillermo Rauch 推出了所谓的「AI skill 的 npm」,让用户仅需一个简单命令 npx skills add [package],就能为自己的 AI 智能体轻松注入专业能力。

就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。
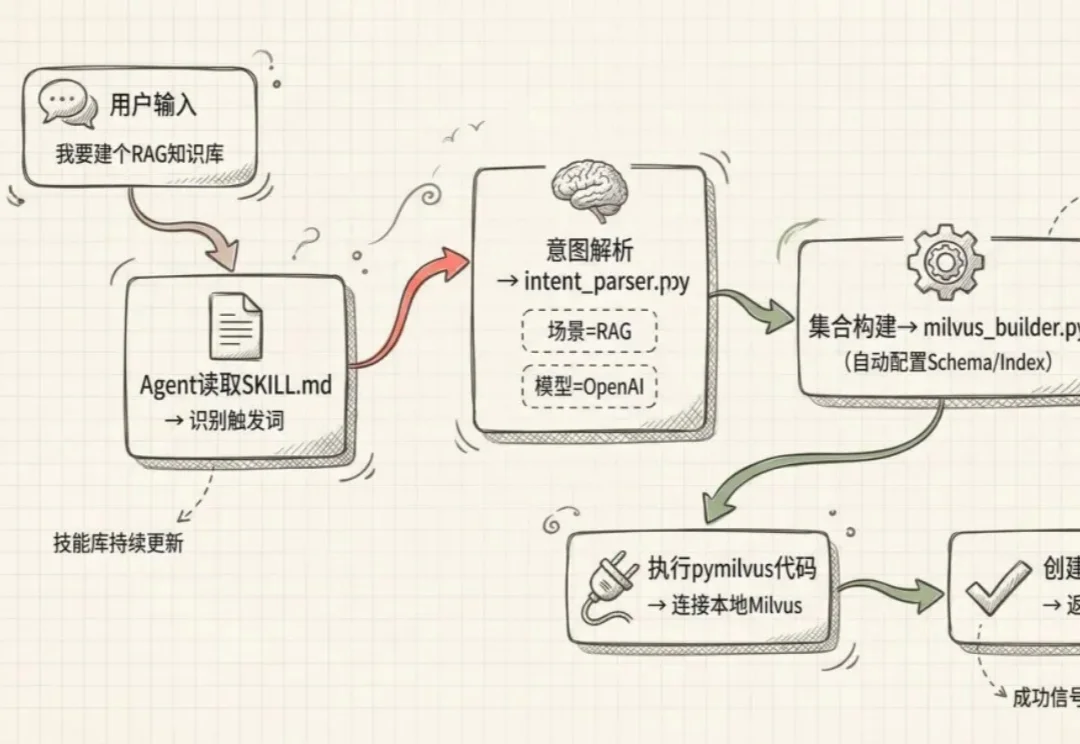
Agent很好,但要做好工具调用能才能跑得通。

摩尔线程 AI 算力本(MTT AIBOOK)是专为 AI 学习与开发者打造的个人智算平台。它搭载自研智能 SoC 芯片「长江」,提供 50TOPS 异构 AI 算力,支持混合精度计算。运行基于 Linux 内核的 MT AIOS 操作系统,具备多系统兼容能力,并预置完整 AI 开发环境与工具链。

华东师范大学Planing Lab提出APEX框架,通过自然语言指令实现学术海报的局部可控编辑,并引入「审查—调整」机制提升编辑可靠性。

这两天都在研究 ralph,一个你睡觉时,都能不眠不休替你干需求、榨干任何 Coding Agent 的工具。
没有太小的需求,只有太少的想象力。最近在社群里看到一张图,我足足盯着看了半分钟。那是一张课程总结图,第一眼看着就很喜欢,有种淡淡的真人手绘的「松弛感」:我当时立马私信问他用的什么工具,他说是 Excalidraw。

这不是一个普通的Skill,而是一把“把经验变成Skill”的工具:Claudeception是一个Meta-Skill,即专门用来“生产技能”的技能。

我们进入了一个模型不再只是“工具”的时代。真正的突破,不在于它能做多少事,而在于它是否能读懂你的意图、情绪与沉默。

测了一堆AI视频生成工具后,骡子马发现了个真东西——Flova。