
GPT-5变蠢背后:抑制AI的幻觉,反而让模型没用了?
GPT-5变蠢背后:抑制AI的幻觉,反而让模型没用了?OpenAI的GPT-5因大幅降低AI幻觉而被批"变蠢",输出呆板创造力减弱,反映出幻觉降低限制模型灵活性。对话嘉宾甄焱鲲分析幻觉本质无法根除,需辩证看待,并探讨类型分5类、缓解方法如In-Context-Learning及RAG,影响企业应用场景的容忍度与决策,强调未来模型或通过世界模型深化理解。
来自主题: AI资讯
10513 点击 2025-08-23 10:32
 搜索
搜索
OpenAI的GPT-5因大幅降低AI幻觉而被批"变蠢",输出呆板创造力减弱,反映出幻觉降低限制模型灵活性。对话嘉宾甄焱鲲分析幻觉本质无法根除,需辩证看待,并探讨类型分5类、缓解方法如In-Context-Learning及RAG,影响企业应用场景的容忍度与决策,强调未来模型或通过世界模型深化理解。
在人工智能技术迅速迭代的当下,一种新的幻觉机制正在悄然成型。

在 AI 工具层出不穷的当下,很多人开始尝试用一个 AI 写故事、编脚本、润色文案。但对于日常需要写稿、整理内容的工作者来说,一个「替你写」的 AI,未必是最优解。幻觉、记忆、上下文,都是问题。
幻觉,作为AI圈家喻户晓的概念,这个词您可能已经听得耳朵起茧了。我们都知道它存在,也普遍接受了它似乎无法根除,是一个“老大难”问题。但正因如此,一个更危险的问题随之而来:当我们对幻觉的存在习以为常时,我们是否也开始对它背后的系统性风险变得麻木?我们是真的从第一性原理上理解了它,还是仅仅在用一个又一个的补丁(比如RAG)来被动地应对它?
GPT-oss放飞自我了?!居然出现了明显的幻觉行为。 在没有提示词的情况下,消耗超过30000个token凭空想出一个问题,还反复求解了5000多次?!
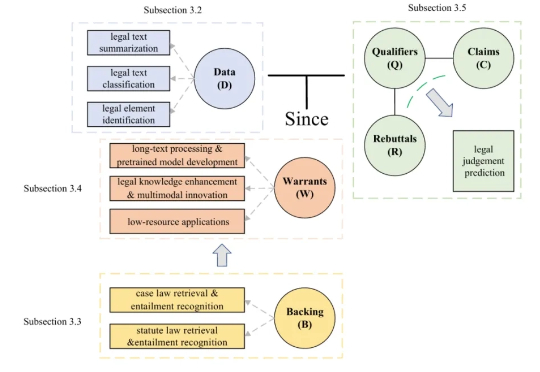
研究人员首次系统综述了大型语言模型(LLM)在法律领域的应用,提出创新的双重视角分类法,融合法律推理框架(经典的法律论证型式框架)与职业本体(律师/法官/当事人角色),统一梳理技术突破与伦理治理挑战。论文涵盖LLM在法律文本处理、知识整合、推理形式化方面的进展,并指出幻觉、可解释性缺失、跨法域适应等核心问题,为下一代法律人工智能奠定理论基础与实践路线图。

取名大王 Karpathy。

当前AI应用层,无数创业者都曾尝试或正走在AI+游戏的这条赛道上。AI正不断拓展游戏的边界,从赋予游戏角色(NPC)智慧,到自动化生成海量内容。然而,这条赛道并非坦途,性能、幻觉问题、玩家接受度等一系列难关等待从业者去克服。

RAG(检索增强生成)作为解决大模型"幻觉"和知识时效性问题的关键技术,已成为企业AI应用的主流架构。Contextual AI由RAG技术的创始研究者组建,致力于开发能应对复杂知识密集型任务的专业智能体。
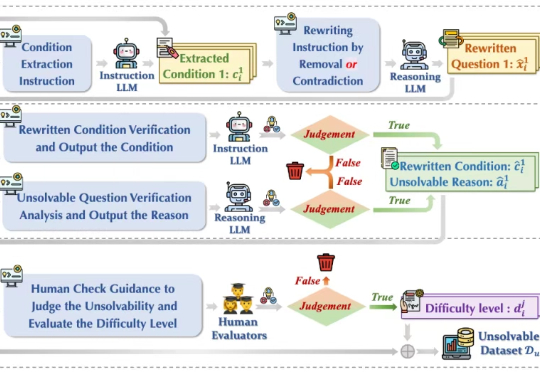
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。