
Manus爆火的秘密武器Browser Use融资1700万美元!让AI「读懂」网页
Manus爆火的秘密武器Browser Use融资1700万美元!让AI「读懂」网页随着AI智能体的爆发,Browser Use异军突起,刚刚融资1700万美元。它能让AI智能体轻松地「读懂」网站并自动完成复杂任务,引领了一波AI应用热潮。
来自主题: AI资讯
8319 点击 2025-03-24 16:10
 搜索
搜索
随着AI智能体的爆发,Browser Use异军突起,刚刚融资1700万美元。它能让AI智能体轻松地「读懂」网站并自动完成复杂任务,引领了一波AI应用热潮。
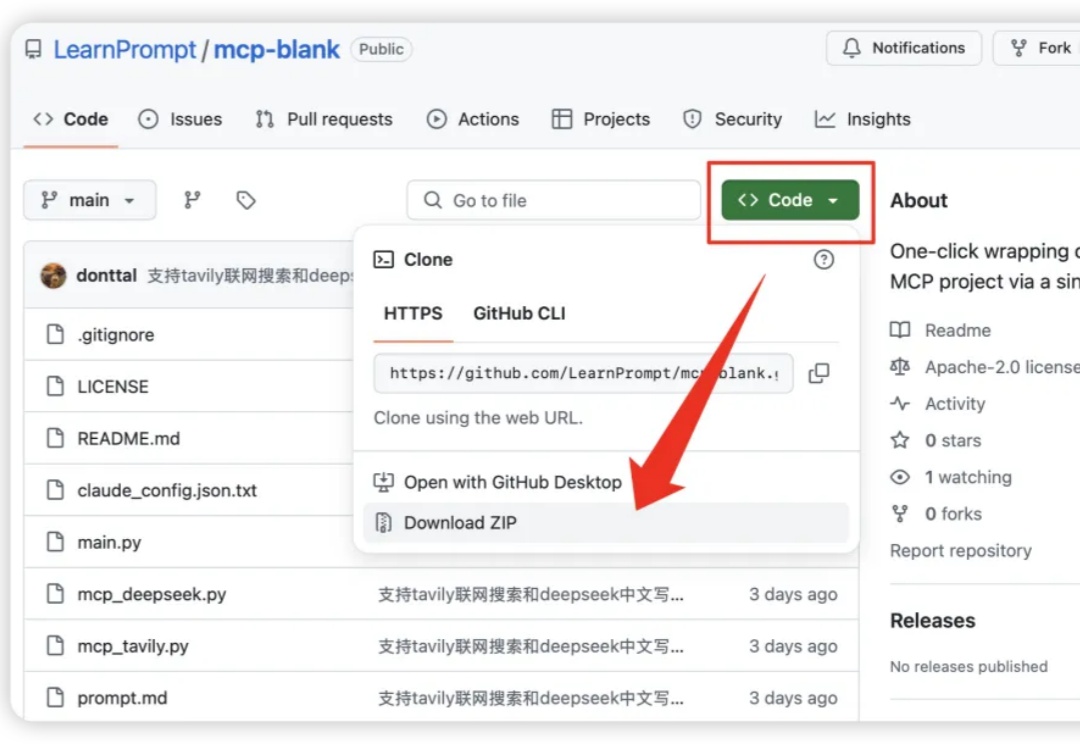
上期做了一个一键安装 MCP 项目的平价方案,

当前,传统生物制造方法在知识整合、数据处理和实验设计方面面临诸多挑战,限制了其在工业化应用中的效率和可扩展性。

华人学者、斯坦福大学副教授 James Zou 领导的团队提出了 TextGrad ,通过文本自动化“微分”反向传播大语言模型(LLM)文本反馈来优化 AI 系统。只需几行代码,你就可以自动将用于分类数据的“逐步推理”提示转换为一个更复杂的、针对特定应用的提示。

做表情包一度是很多文生图、文生视频应用的场景。Pika在去年就靠魔法猫,在国外出圈了一把。
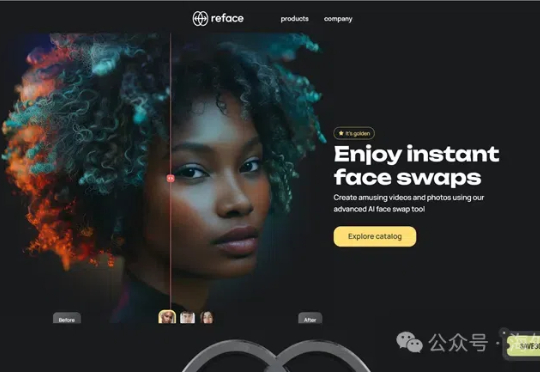
Dima Shvets作为天使投资人兼Reface联合创始人,其打造的AI换脸应用下载量突破2.5亿次。该应用的成功源于"实时换脸"技术的先发优势与病毒式传播特性的双重驱动。以下是Dima分享关于如何成功打造Reface的经验分享

日前,北京市教委出台《北京市推进中小学人工智能教育工作方案(2025—2027年)》(简称《方案》),计划从今年起,通过创新培育“京娃”系列智能体、全覆盖开展中小学人工智能通识教育、打造一批“助教、助学、助育、助评、助研、助管”应用场景等系列举措,全方位推动人工智能赋能首都基础教育改革发展。
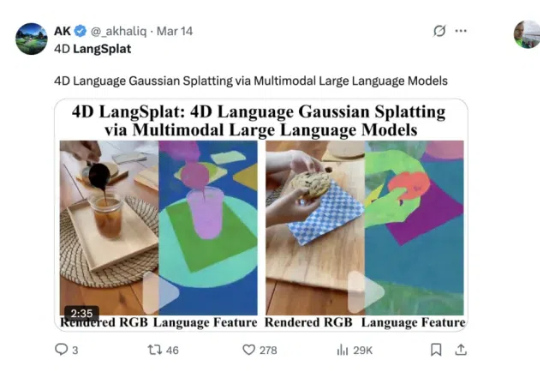
来自清华大学、哈佛大学等机构的研究团队提出了一种创新方法——4D LangSplat。该方法基于动态三维高斯泼溅技术,成功重建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。这一突破为相关领域的研究与应用提供了新的可能性, 该工作目前已经被CVPR2025接收。

3月20日,国家儿童医学中心、首都医科大学附属北京儿童医院(以下简称“北京儿童医院”)联合北京百川智能科技有限公司(以下简称“百川智能”)、小儿方健康科技(北京)有限公司(以下简称“小儿方”)正式发布国内首个儿科大模型——“福棠·百川”儿科大模型,同时发布两款人工智能应用即AI儿科医生基层版和专家版。

估计AI行业又要躁动一会了。最近,据官方消息披露,前DeepSeek核心成员出去创业了。更准确地说,是原幻方量化(DeepSeek母公司)的核心成员——项国明,出去创立了一家新公司,名叫迪洛斯智能,主攻企业AI应用平台。