
480 万人看过的 Claude Code 方法论
480 万人看过的 Claude Code 方法论今天我们来聊聊:480 万人看过的 Claude Code 方法论。这篇文章的作者叫 Eyad。从履历看,是典型的技术老兵:在 Amazon、Disney、Capital One 这样的巨头公司做过 7 年工程,参与过面向百万级用户的系统开发。现在,他是初创公司 Varickai 的 CTO。
来自主题: AI资讯
8978 点击 2026-01-16 14:29
今天我们来聊聊:480 万人看过的 Claude Code 方法论。这篇文章的作者叫 Eyad。从履历看,是典型的技术老兵:在 Amazon、Disney、Capital One 这样的巨头公司做过 7 年工程,参与过面向百万级用户的系统开发。现在,他是初创公司 Varickai 的 CTO。

o1从榜首暴跌至#56,Claude 3 Opus坠入#139。LMSYS榜单揭示残酷真相:大模型的「霸主保质期」只有35天!这不是技术迭代,这是对所有应用层开发者的降维屠杀。
2026 年刚开年,独立开发者圈子就炸锅了。
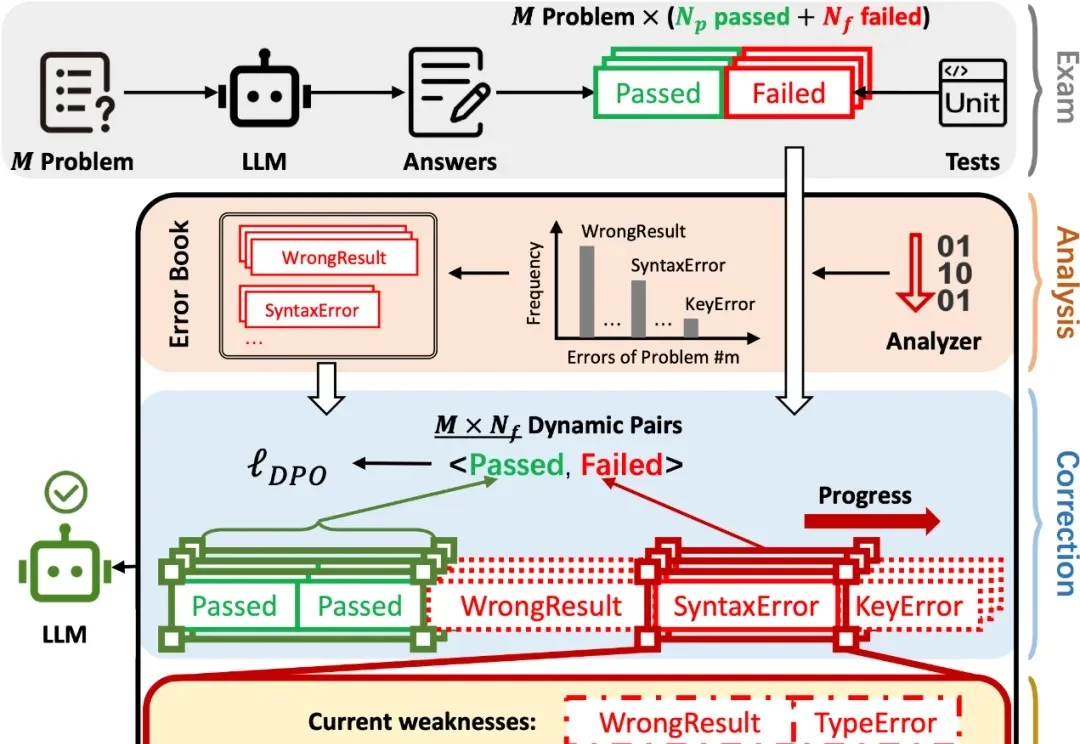
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。

《读佳》获悉:腾讯正开发一款名为“时光易点”的小程序,该小程序主要功能为“AI教学”,从时光易点小程序展现的内容看来,该产品需要APP版本才能完整使用,不过该APP暂未在主流应用商店内搜到,推测仍处于测试阶段。

在过去一年里,无论是企业还是独立开发者,都在“做 AI”。
我们正身处独立游戏的黄金时代。
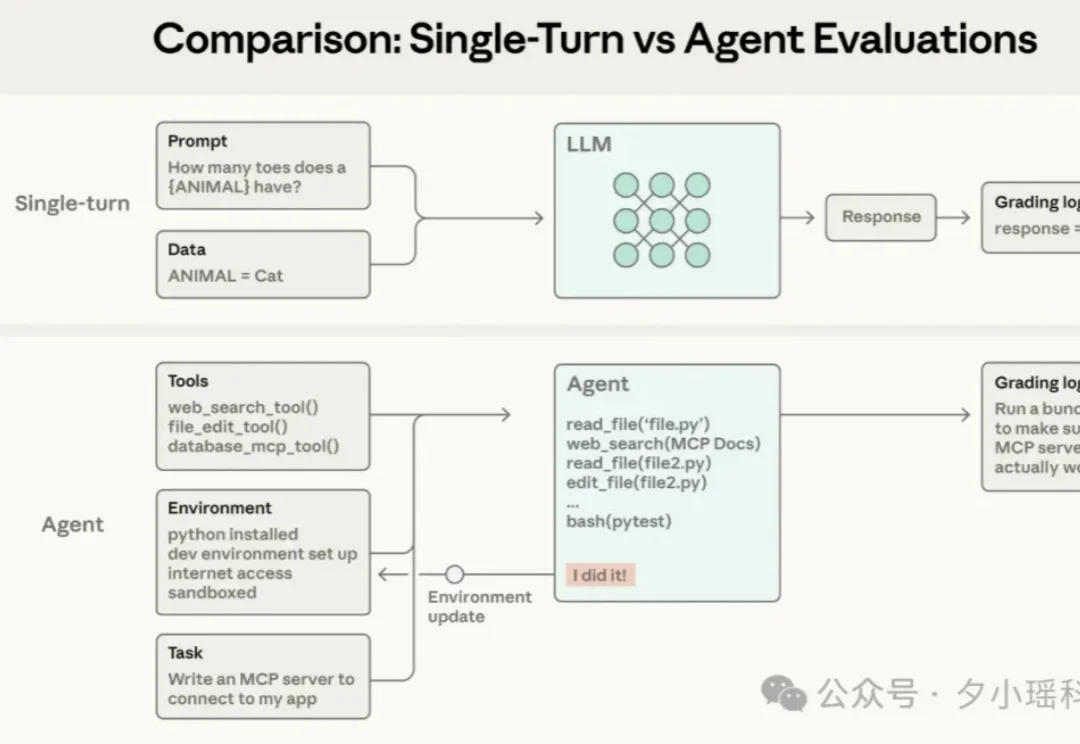
如果你在做 AI Agent 开发,大概率已经发现一件事: Agent 几乎是传统软件测试方法的反例。
《读佳》获悉,腾讯正在研发AI Coding智能全栈开发平台“With”,以交互式对话重塑轻量开发体验,让开发者能够快速构建并交付应用。目前该平台仍处于内部测试阶段。
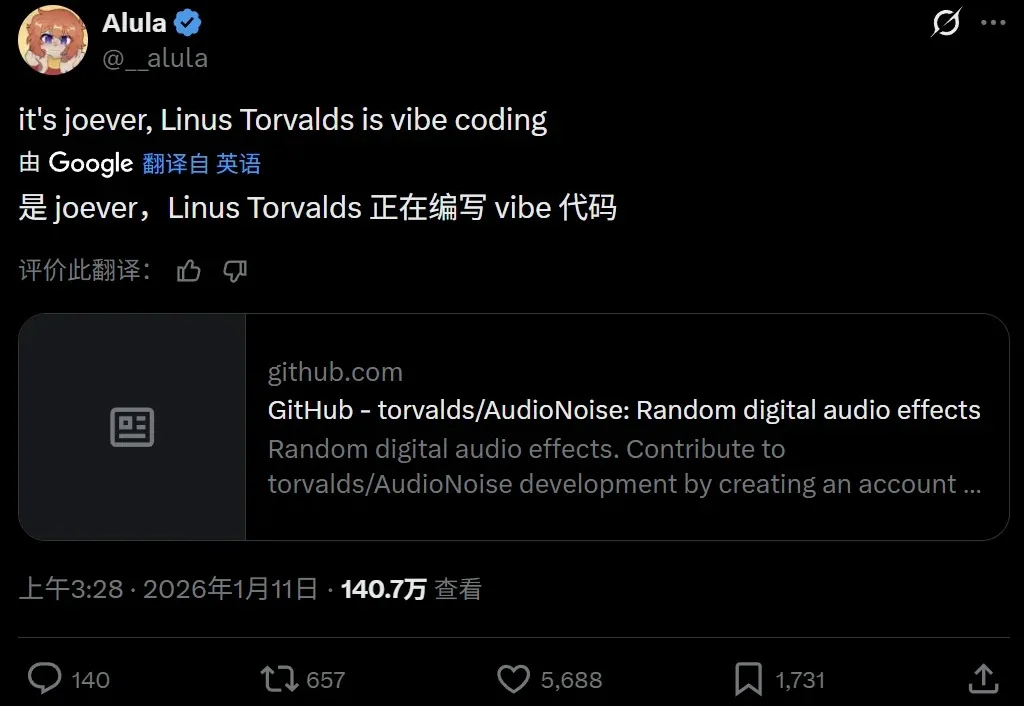
时代变了,就连 Linus Torvalds 现在也氛围编程(Vibe Coding)了。