AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升
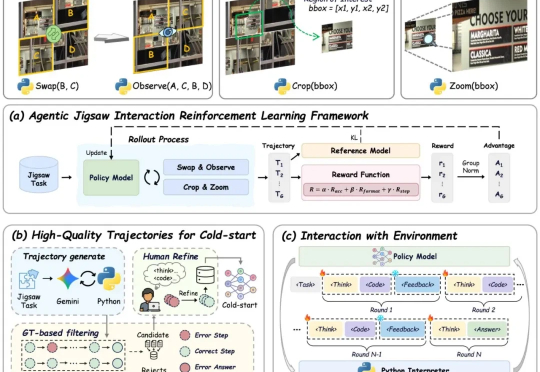
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
来自主题: AI技术研报
7802 点击 2025-10-21 15:30
 搜索
搜索
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
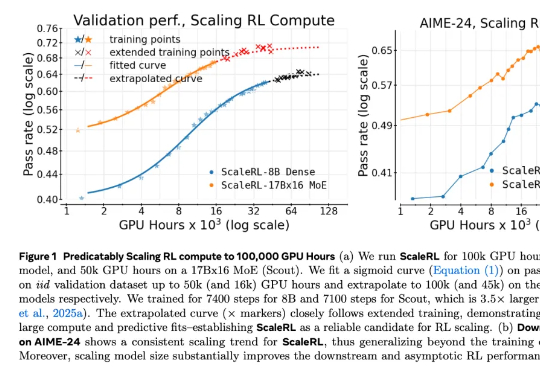
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?

在近日的一次访谈中,Andrej Karpathy深入探讨了AGI、智能体与AI未来十年的走向。他认为当前的「智能体」仍处早期阶段,强化学习虽不完美,却是目前的最优解。他预测未来10年的AI架构仍然可能是类似Transformer的巨大神经网络。
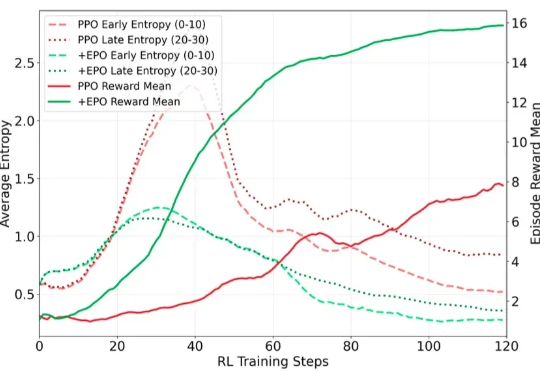
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
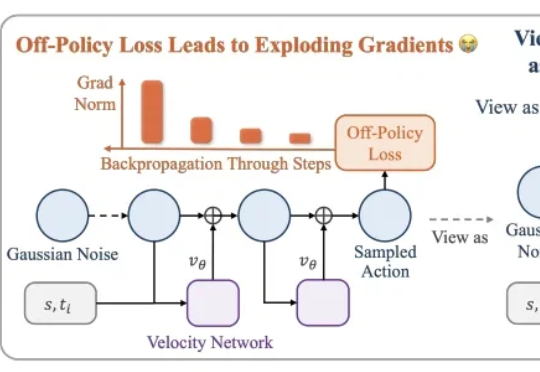
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。
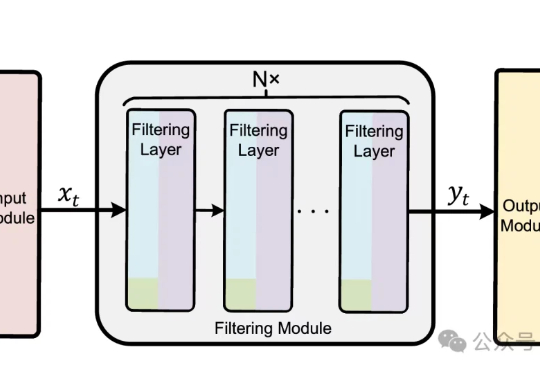
在机器人与自动驾驶领域,由强化学习训练的控制策略普遍存在控制动作不平滑的问题。这种高频的动作震荡不仅会加剧硬件磨损、导致系统过热,更会在真实世界的复杂扰动下引发系统失稳,是阻碍强化学习走向现实应用的关键挑战。
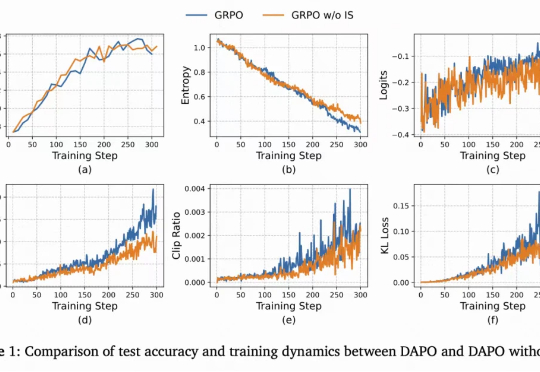
从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。

小米的最新大模型科研成果,对外曝光了。就在最近,小米AI团队携手北京大学联合发布了一篇聚焦MoE与强化学习的论文。而其中,因为更早之前在DeepSeek R1爆火前转会小米的罗福莉,也赫然在列,还是通讯作者。

大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。
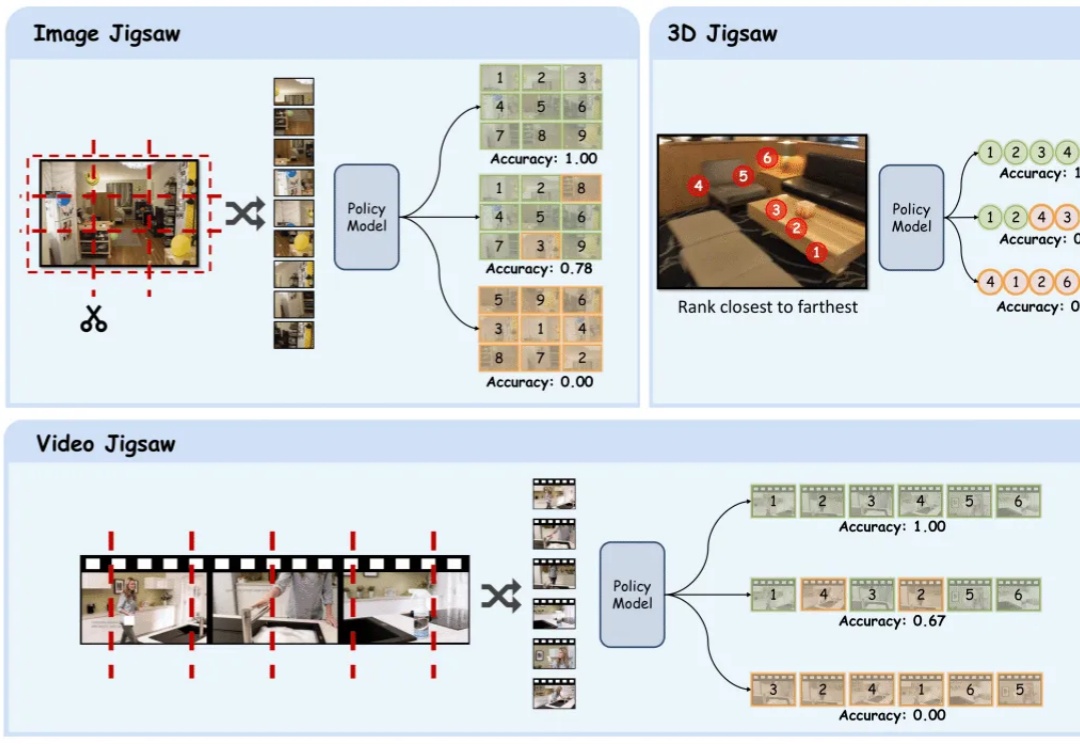
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。