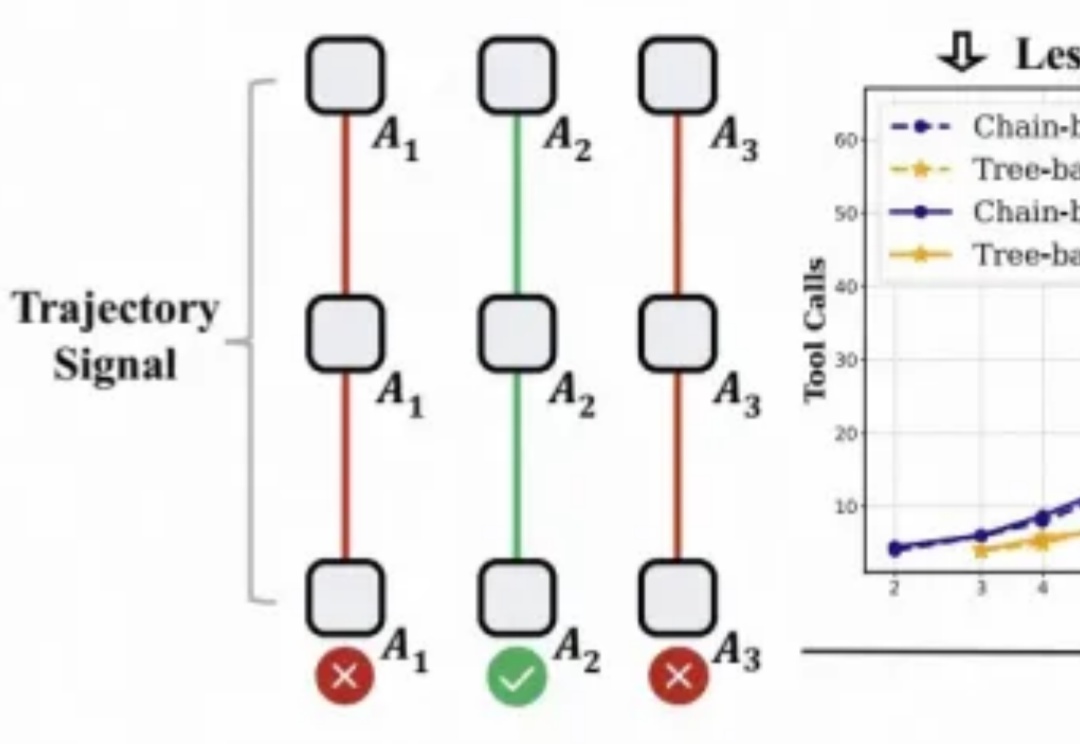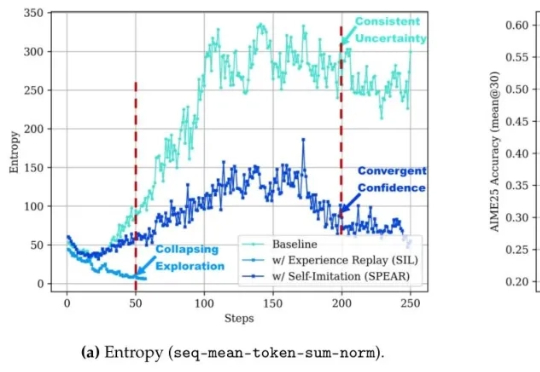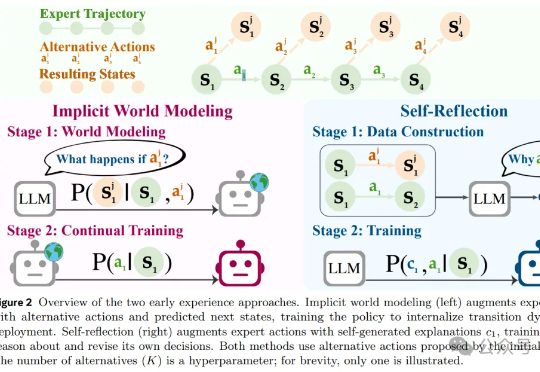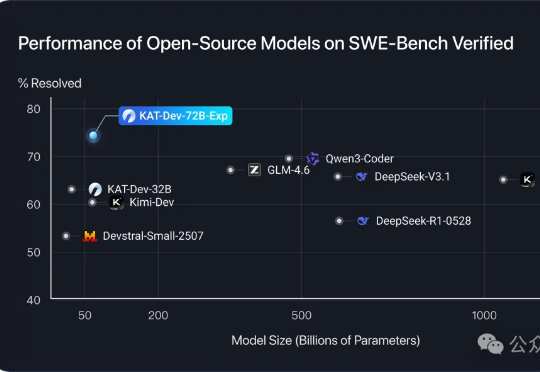
北大彭一杰教授课题组提出RiskPO,用风险度量优化重塑大模型后训练
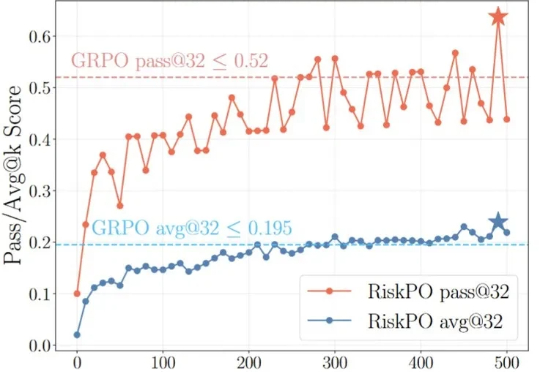
北大彭一杰教授课题组提出RiskPO,用风险度量优化重塑大模型后训练当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。从数学解题到代码生成,RLVR 本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑 —— 但现实是,以 GRPO 为代表的主流方法正陷入「均值优化陷阱」。
来自主题: AI技术研报
7372 点击 2025-10-15 14:19