
RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案
RL是「点金石」还是「挖掘机」?CMU 用可控实验给出答案近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。
来自主题: AI技术研报
6954 点击 2025-12-16 16:26
 搜索
搜索
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。
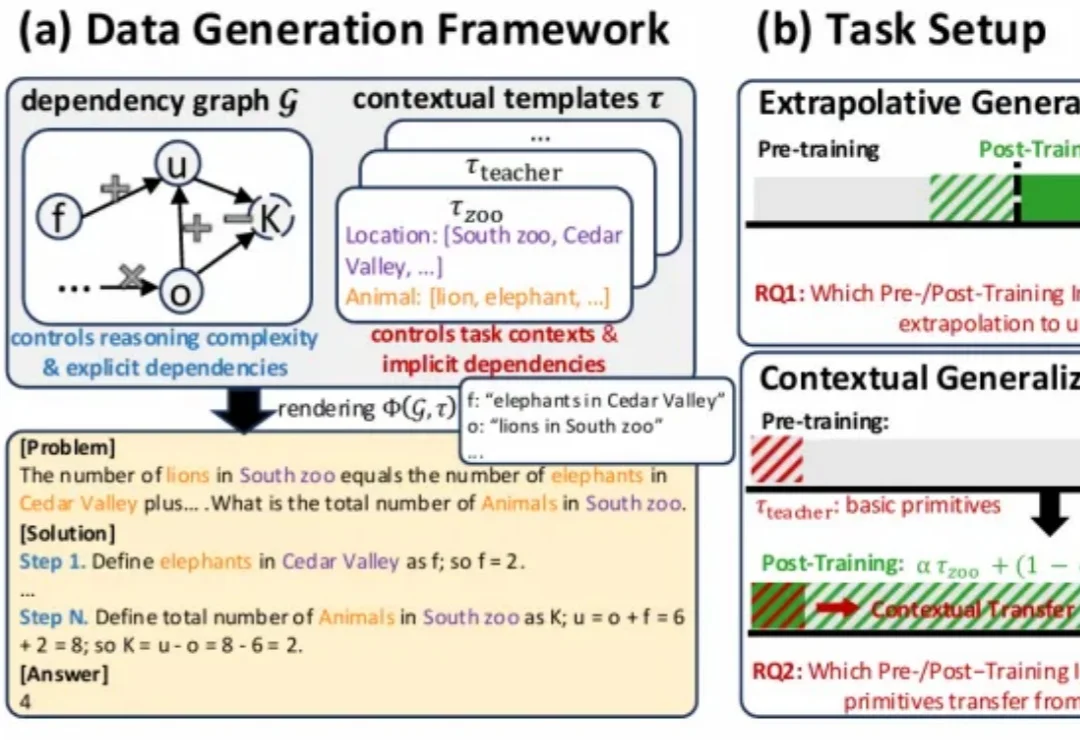
近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。

在 Physical Intelligence 最新的成果 π0.6 论文里,他们介绍了 π0.6 迭代式强化学习的思路来源:

灵初智能发布全球首个具身原生人类数据采集方案 Psi-SynEngine。该方案由灵初智能全栈自研,包含便携式外骨骼触觉手套数采套装、大规模 in the wild 数采数据管线、基于世界模型和强化学习的跨本体数据迁移模型,并已率先将采集到的人类数据应用于物流等真实场景。

最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。
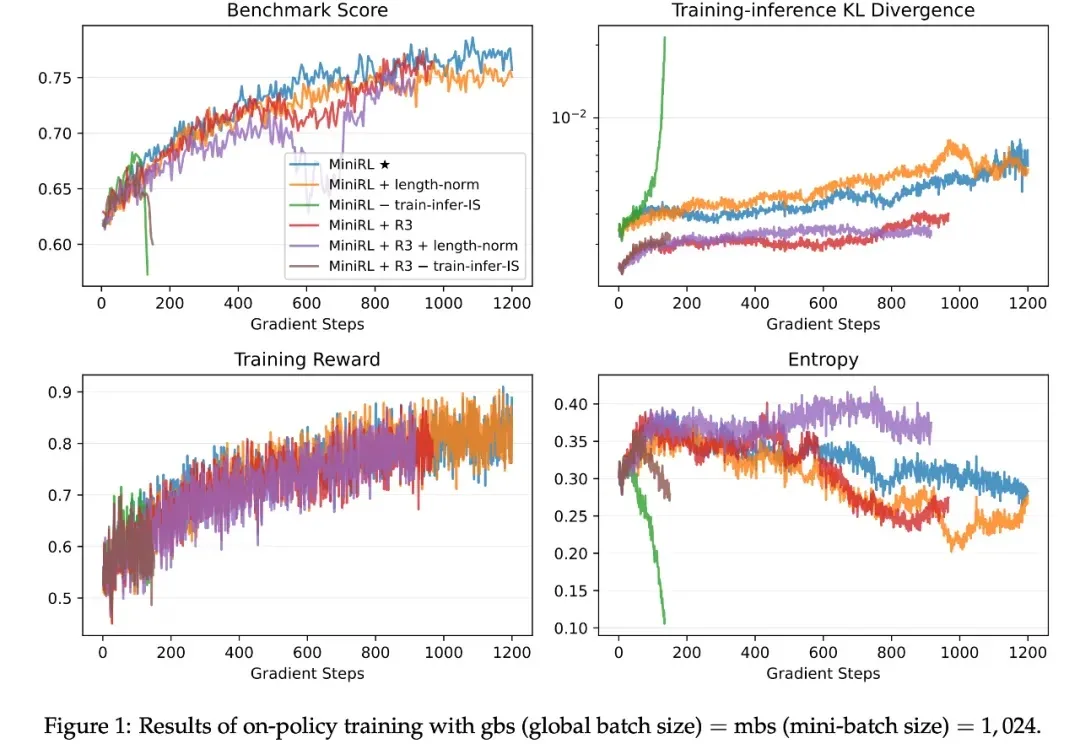
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。

本科毕业于北大工学院,早期研究聚焦于自动驾驶;博士后期间在卡内基梅隆大学,利用强化学习解决核聚变反应堆控制问题。陈佳玉的科研生涯,始终围绕着复杂系统的智能控制展开。

Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。
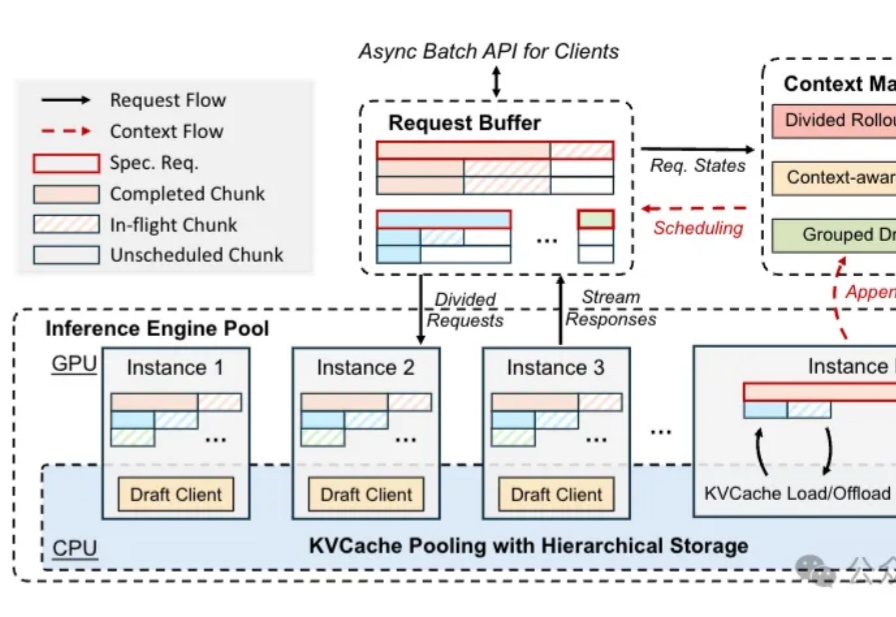
u1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢……

继轻量级强化学习(RL)框架 slime 在社区中悄然流行并支持了包括 GLM-4.6 在内的大量 Post-training 流水线与 MoE 训练任务之后,LMSYS 团队正式推出 Miles——一个专为企业级大规模 MoE 训练及生产环境工作负载设计的强化学习框架。