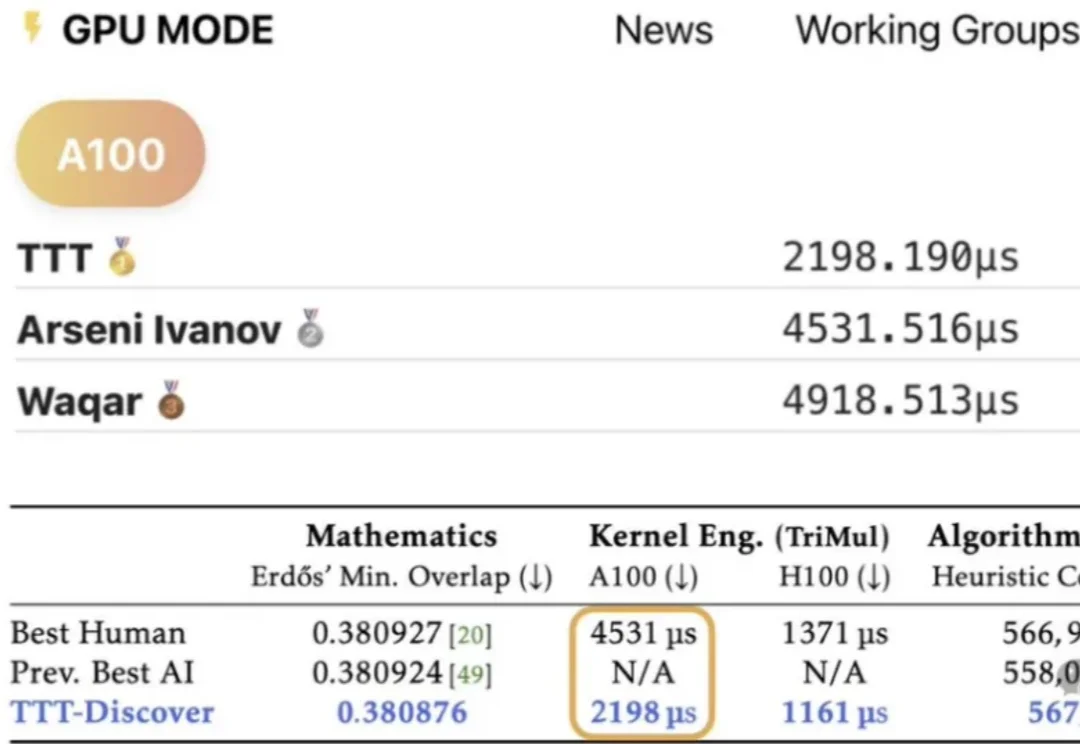
斯坦福英伟达推出测试时强化学习:微调开源模型胜过顶级闭源模型,仅需几百美元
斯坦福英伟达推出测试时强化学习:微调开源模型胜过顶级闭源模型,仅需几百美元大模型持续学习,又有新进展!
来自主题: AI技术研报
9679 点击 2026-01-27 16:15
 搜索
搜索
大模型持续学习,又有新进展!
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
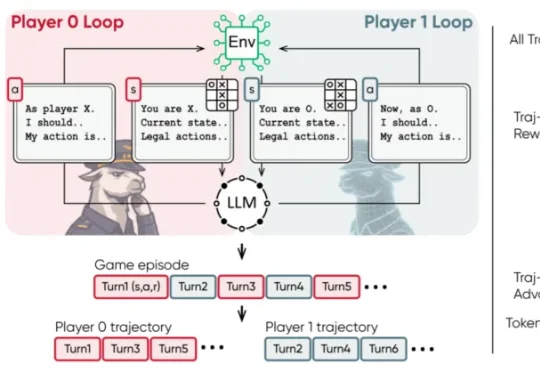
近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水

清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。
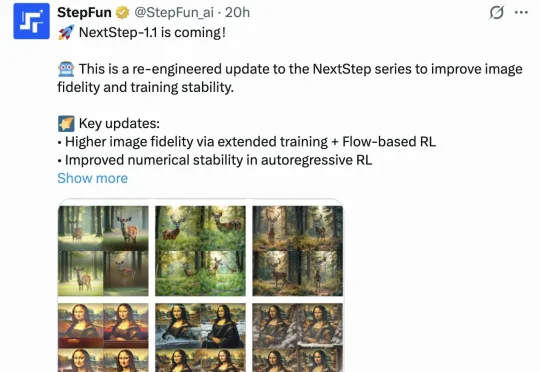
直到刚刚,用最新的图像模型NextStep-1.1,扳回一球。总体来看,这次开源的NextStep-1.1解决了之前NextStep-1中出现的可视化失败(visualization failures )问题。其通过扩展训练和基于流的强化学习(RL)后训练范式,大幅提升了图像质量。
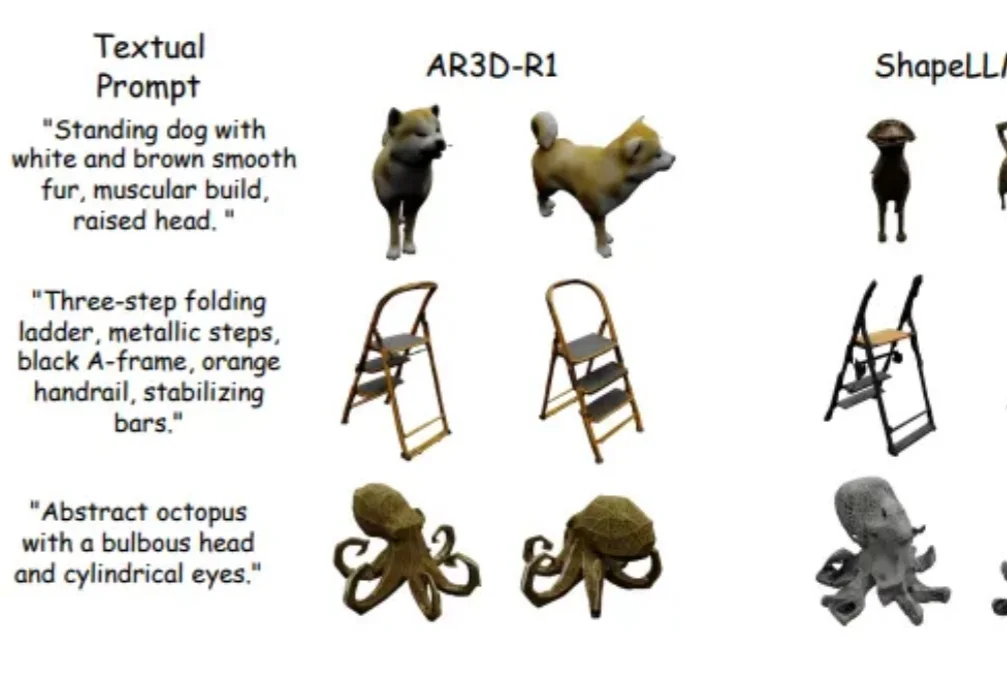
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
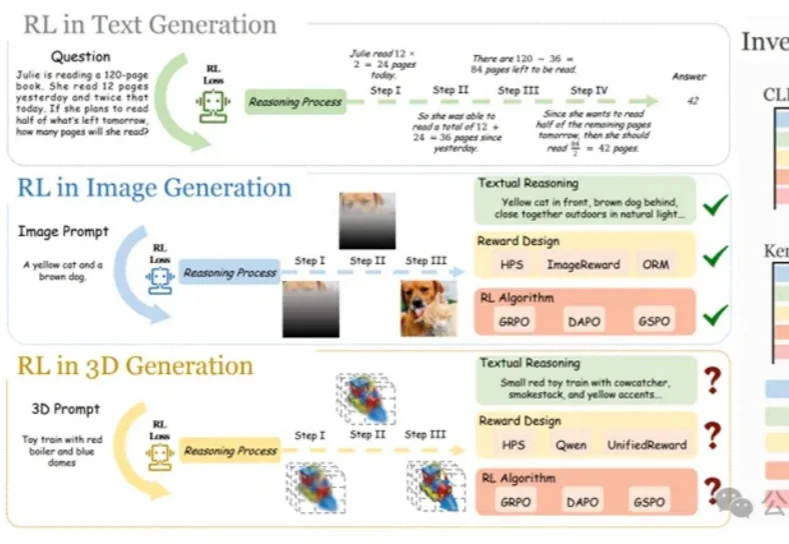
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。

本周四消息,于两年前创立亚马逊 AGI 团队的高级副总裁兼首席科学家 Rohit Prasad 已官宣离职。