
废片也能变大片!北大开源首个「美学照片重构」模型 | ICML'26
废片也能变大片!北大开源首个「美学照片重构」模型 | ICML'26北大彭宇新团队提出「美学照片重构」新任务,从摄影教学视频中自动构建数据集AesRecon,并开发两阶段模型AesFormer,通过优化构图、视角与人物姿态,提升照片的美感与艺术表现力。
来自主题: AI技术研报
9989 点击 2026-06-08 14:49
 搜索
搜索
北大彭宇新团队提出「美学照片重构」新任务,从摄影教学视频中自动构建数据集AesRecon,并开发两阶段模型AesFormer,通过优化构图、视角与人物姿态,提升照片的美感与艺术表现力。
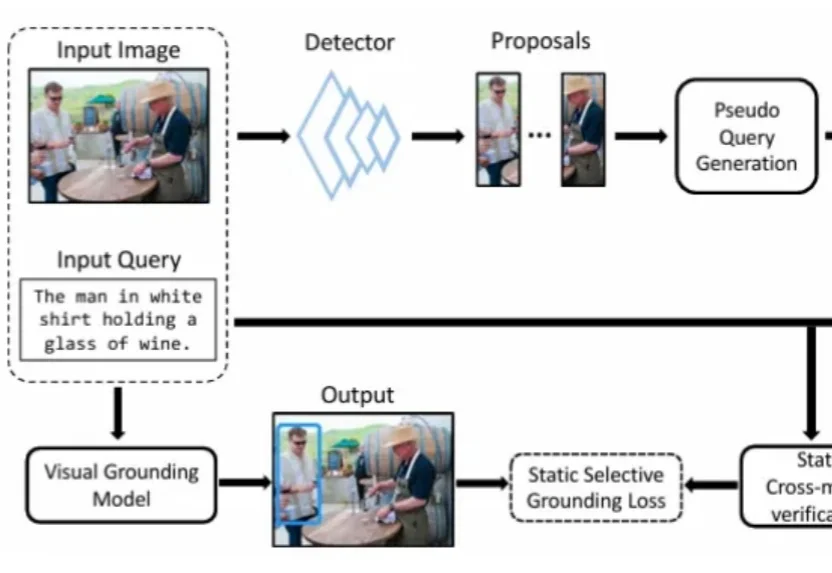
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

一张蓝锥嘴雀的图片,你能认出它是“鸟”,但能认出它是“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”吗?
本文是北京大学彭宇新教授团队在文本生成视频领域的最新研究成果,相关论文已被 CVPR 2026 接收。

你随手拍下一张照片,AI也许只会夸“真好看”,却说不出一句真正有用的建议。
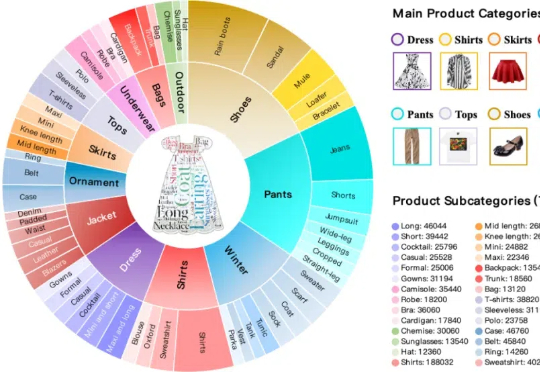
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。
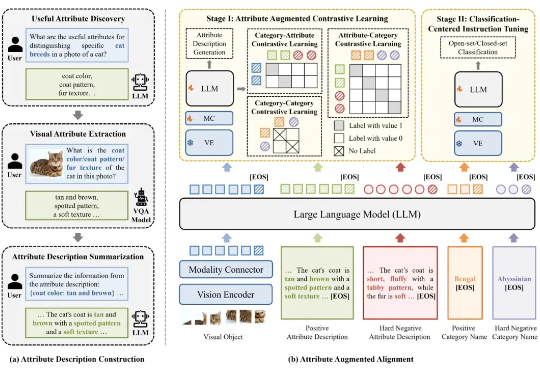
尽管多模态大模型在通用视觉理解任务中表现出色,但不具备细粒度视觉识别能力,这极大制约了多模态大模型的应用与发展。针对这一问题,北京大学彭宇新教授团队系统地分析了多模态大模型在细粒度视觉识别上所需的 3 项能力:对象信息提取能力、类别知识储备能力、对象 - 类别对齐能力,发现了「视觉对象与细粒度子类别未对齐」