
微软开源多模态AI基础模型Magma!无需额外微调轻松拿捏网页、机器人
微软开源多模态AI基础模型Magma!无需额外微调轻松拿捏网页、机器人微软研究院官宣开源多模态AI——Magma模型。首个能在所处环境中理解多模态输入并将其与实际情况相联系的基础模型。
来自主题: AI技术研报
8504 点击 2025-03-10 22:22
 搜索
搜索
微软研究院官宣开源多模态AI——Magma模型。首个能在所处环境中理解多模态输入并将其与实际情况相联系的基础模型。

在面对复杂的推理任务时,SFT往往让大模型显得力不从心。最近,CMU等机构的华人团队提出了「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过200万个样本的强化学习方法。
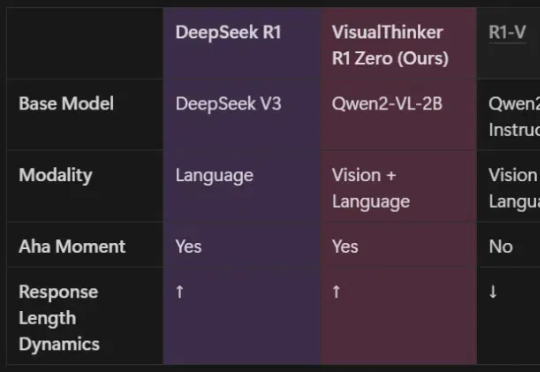
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!
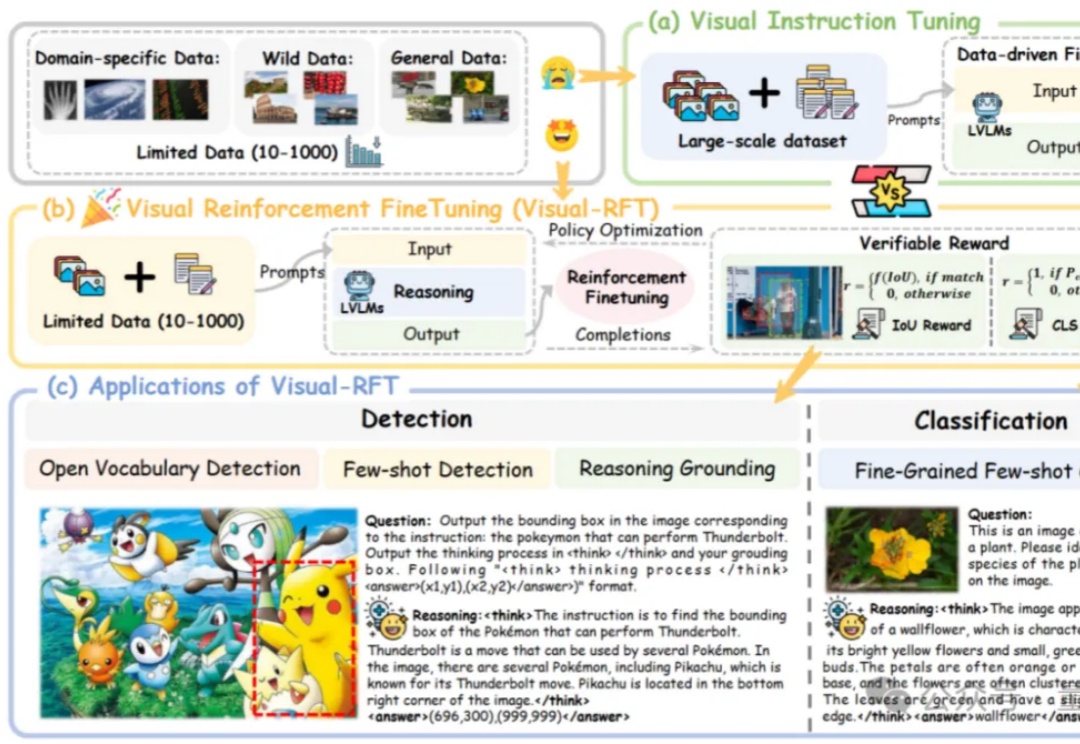
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!
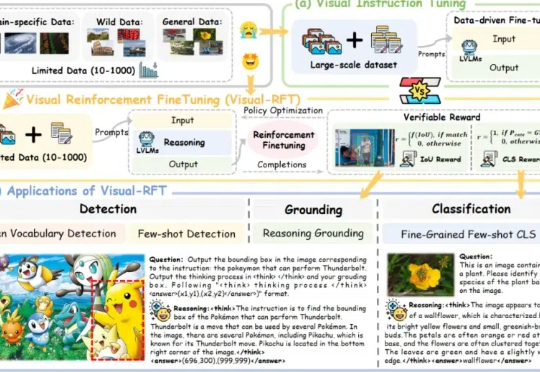
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
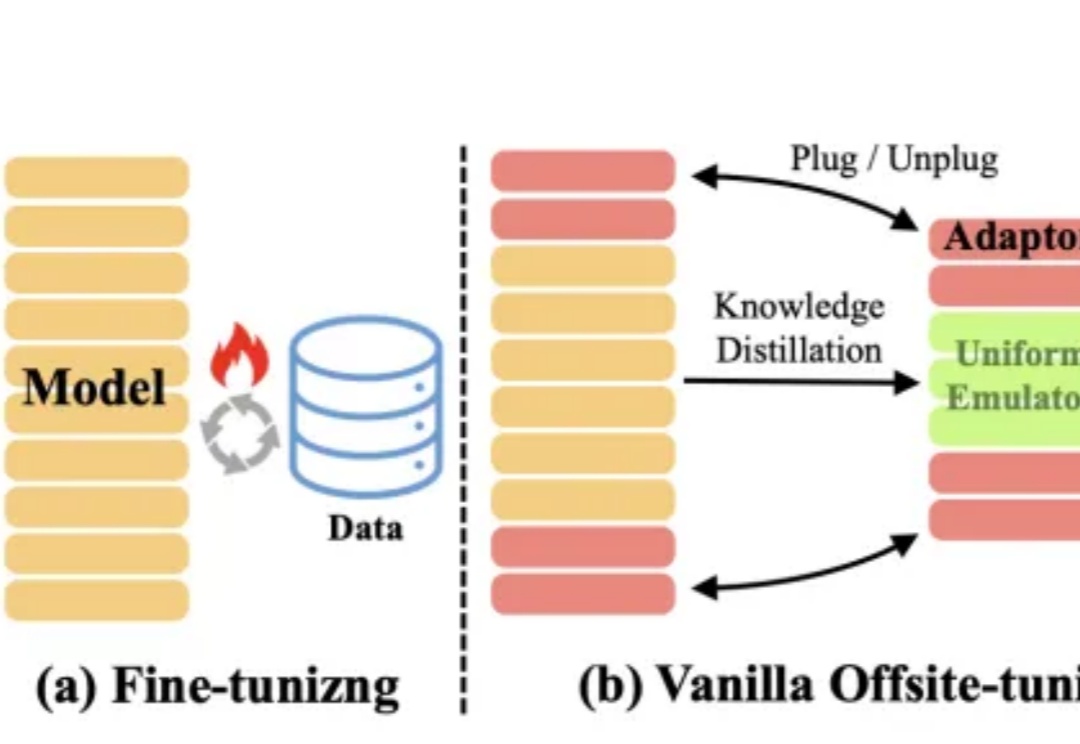
大模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。

据众擎机器人介绍,众擎机器人SE01自主研发的“动态重心补偿算法”以每秒1000次的姿态微调对抗前倾失控风险;仿生肌肉驱动系统使关节瞬时扭矩高达330N·m;而毫米波雷达与视觉融合感知系统则将落地误差控制在±2cm内。

3月1日,潞晨科技官微发布了两则消息。先是宣布:“尊敬的用户,潞晨云将在一周后停止提供DeepSeek API服务,请尽快用完您的余额。如果没用完,我们全额退款。”后又发布消息:“感谢网友的热心提醒,Colossal-AI此前发布对DeepSeek-R1(671B)模型的LoRA微调,在参数加载过程中因参数名称不匹配的Bug导致Loss异常,已在GitHub线上修复。”
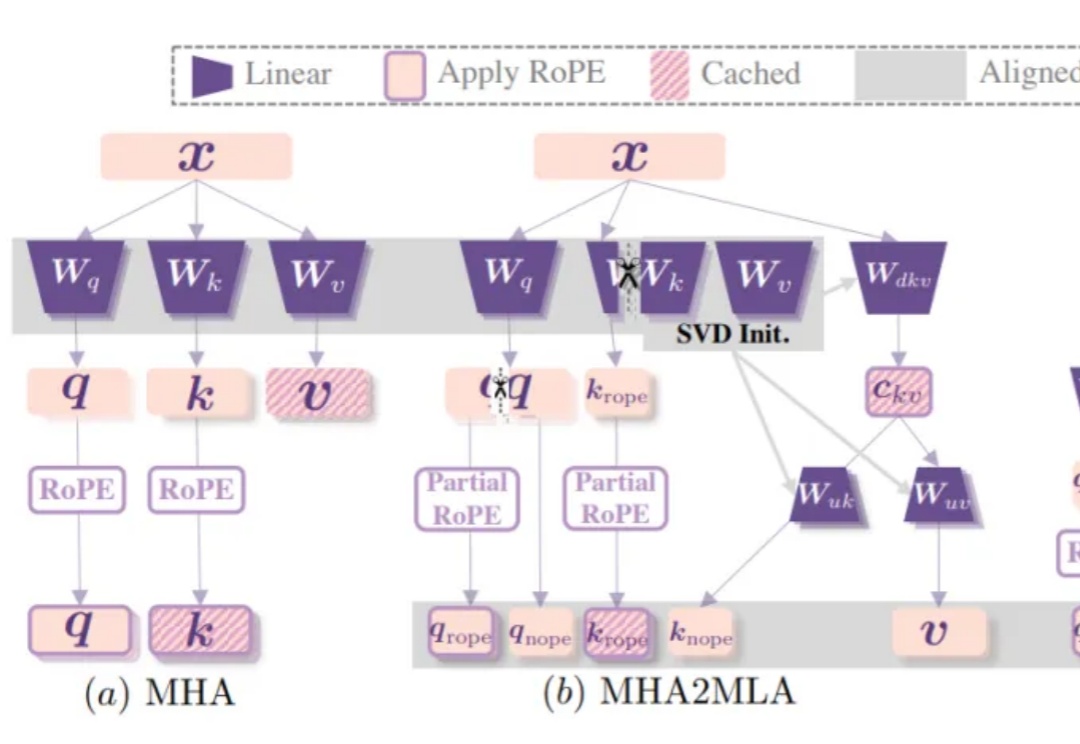
DeepSeek-R1背后关键——多头潜在注意力机制(MLA),现在也能轻松移植到其他模型了!