从少样本到千样本!MachineLearningLM给大模型上下文学习装上「机器学习引擎」
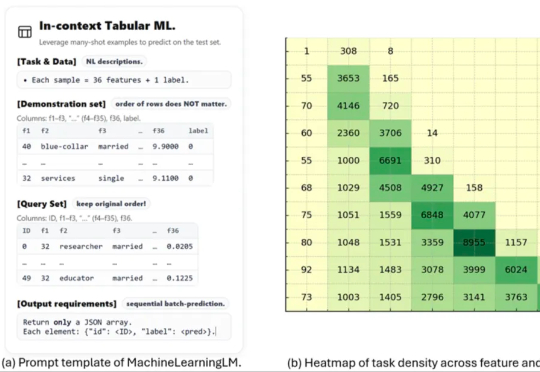
从少样本到千样本!MachineLearningLM给大模型上下文学习装上「机器学习引擎」这项名为 MachineLearningLM 的新研究突破了这一瓶颈。该研究提出了一种轻量且可移植的「继续预训练」框架,无需下游微调即可直接通过上下文学习上千条示例,在金融、健康、生物信息、物理等等多个领域的二分类 / 多分类任务中的准确率显著超越基准模型(Qwen-2.5-7B-Instruct)以及最新发布的 GPT-5-mini。
来自主题: AI技术研报
9461 点击 2025-09-17 09:30