# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
只需一次指令微调,即可让普通大模型变身“全能专家天团”?
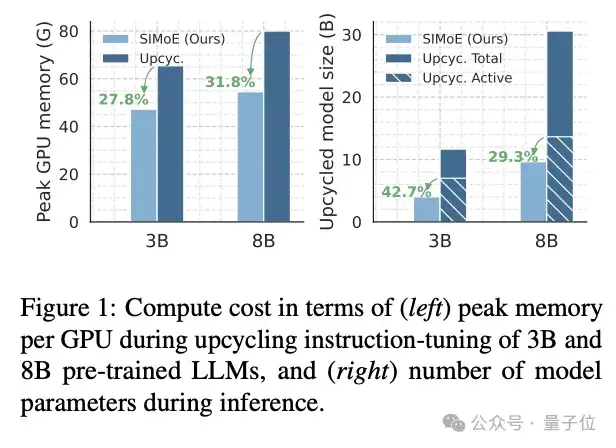
当前预训练语言大模型(LLM)虽具备通用能力,但适应专业领域需高昂的指令微调成本;稀疏混合专家(SMoE)架构作为可扩展的性能-效率平衡框架,虽能提升推理效率并灵活扩展模型容量,但其从头训练消耗巨大资源,因此复用密集大模型参数的升级改造(LLM Upcycling)成为更具成本效益的替代方案。
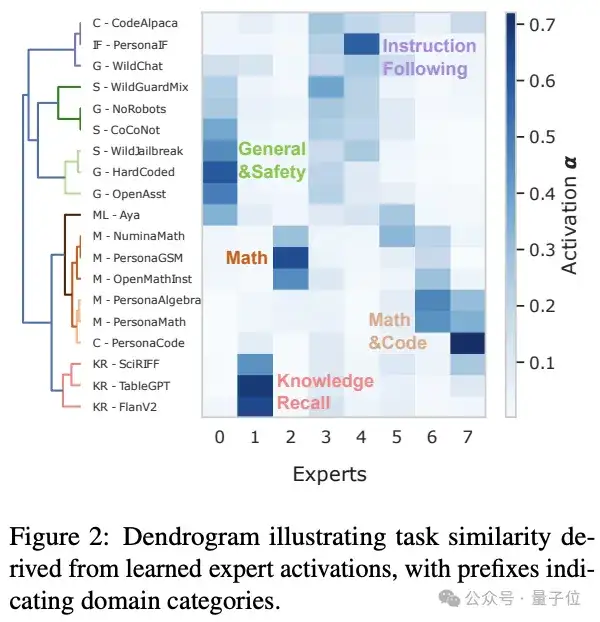
然而现有升级方法存在两大局限:一是依赖人工经验选择可扩展的专家位置(如固定替换FFN层),忽视模型层间动态差异与任务特性;二是缺乏系统机制平衡专家专业化与协作,导致冗余或知识碎片化。
为此,来自浙江大学与Thomson Reuters的研究团队提出全新解决方案稀疏插值混合专家(SIMoE),只需单阶段指令微调,即可将普通大模型自动升级为高性能稀疏专家模型。SIMoE通过结构化稀疏优化自动发现神经元级专家参数子集,创新性地结合专家共享增量参数与掩码正交惩罚在多项基准测试中实现性能、效率的双重突破。
目前相关研究论文已被ICML 2024、ACL 2025 Oral接收,代码及项目网址也已在GitHub上公开。

△ICML2024接收

△ACL 2025 Oral接收
当前大模型升级改造方法用于大模型专业领域适配面临双重困境:
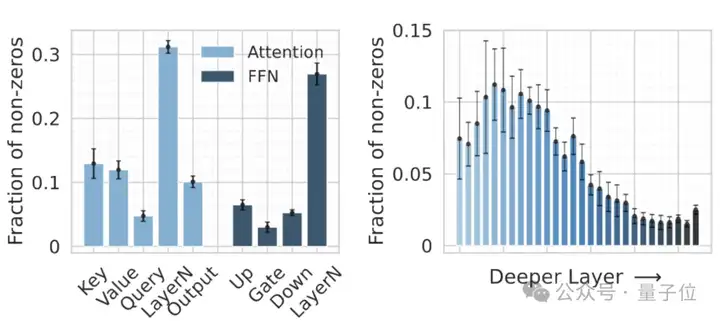
现有方法在决定大模型参数中”何处升级”(where-to-upcycle)时,普遍采用启发式规则,例如固定选择FFN层或Attention模块进行升级,扩展成为SMoE模组。这种静态升级策略忽视了两个关键因素:
1、模型特异性:同一预训练大模型中不同层/参数对模型整体功能的重要性存在显著差异;
2、领域适配需求:不同领域任务会要求特定最优升级位置。
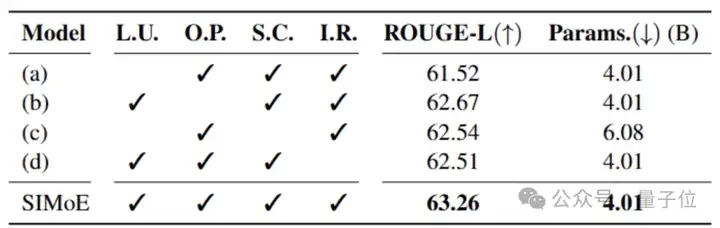
这种算法-模型-数据的脱节导致升级策略僵化,无法自适应特定任务场景,最终导致领域适配性差。如下表所示,传统经验性固定升级策略(i.e.,Learnable Upcycling)—例如升级所有FFN层—对比SIMoE的动态升级策略,其ROUGE-L分数低于SIMoE 1.6–2.5%。
现有方法缺乏系统化机制平衡专家专业化与协同合作:
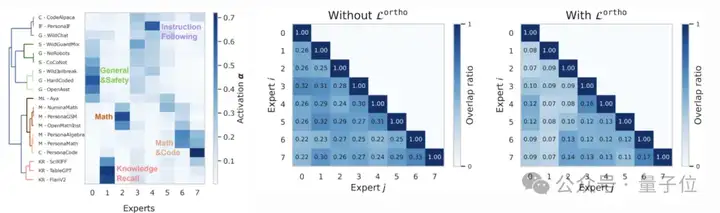
1、专业化不足:为促进知识共享,传统SMoE框架常采用固定共享专家强制协作机制。然而,此类设计会抑制领域专家的专业化能力,极端情况下甚至引发模型崩溃(model collapse)——表现为专家间参数趋同。
2、协作低效:为促进专家专业化,部分升级方法[1]采用独立微调策略——先针对不同领域数据训练多个领域专家,再通过额外训练阶段将其合并为统一SMoE模型。然而,独立训练阻碍了知识迁移,导致专家参数冗余。
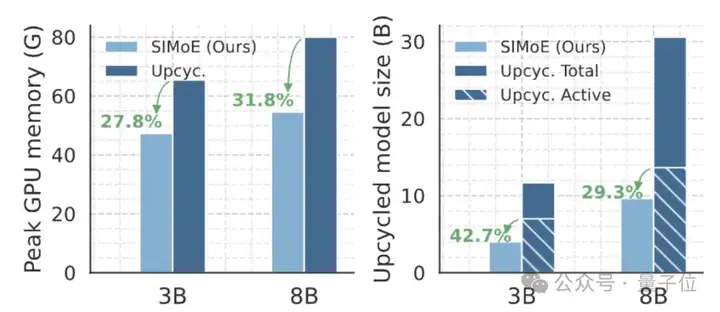
专业化与协作失衡导致泛化性能次优及资源浪费。如图表所示,当前升级方法[1]相较于SIMoE存在性能与参数效率上的双重差距。

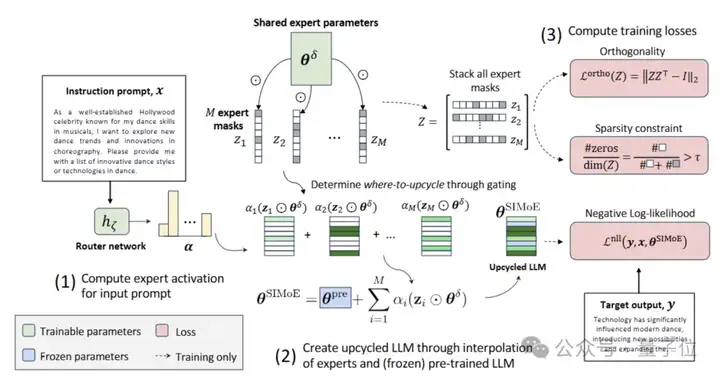
稀疏插值专家(SIMoE)在概念上类似于MoE原理,通过软合并来路由和组合特定专家参数,但在实现上与传统MoE架构不同。SIMoE将每个「插值专家」定义为共享网络中稀疏参数的特定子集。


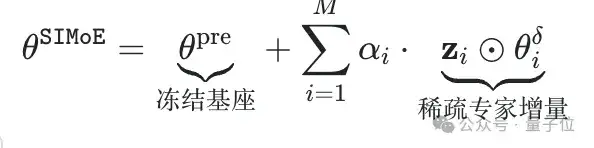
这一设计可带来三重优势:
首先,神经元级升级定位实现全局优化。通过引入L0稀疏约束构建可控优化目标:


最终,冻结基座与稀疏增量协同守护知识完整性。式中θpre的冻结设计确保预训练知识不受扰动,避免指令微调时的灾难性遗忘。配合75%稀疏约束τ=0.75,推理时自动剪枝零值神经元级专家,最终模型尺寸较BTX [1] 缩减66%(10.4B vs 30.58B)。

应用场景多适配:
小样本视觉任务:给定少量任务样本→动态训练特定任务的教师模型→通过知识蒸馏引导「插值专家」模型的组合泛化能力,训练效率提升43%。
零样本指令遵循:通过对「插值专家」二进制掩码的正交约束→鼓励「插值专家」参数专业化→通过训练,达到知识共享于领域专业化的黄金平衡。
视觉基座模型验证:Meta-Dataset大规模视觉小样本学习基准测试。
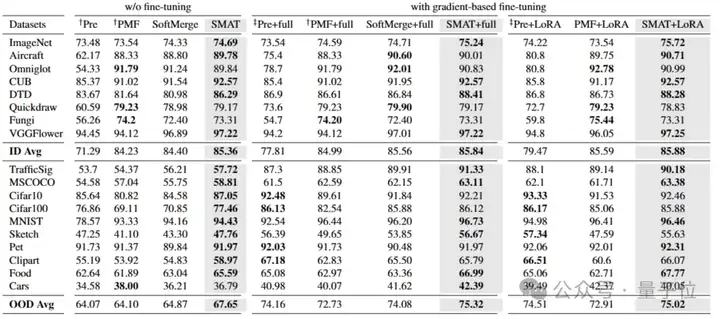
SMAT(SIMoE的视觉版本)在零样本和小样本迁移场景中全面超越基线模型,OOD任务表现尤为惊艳:在零样本设置下,SMAT平均准确率达67.65%,较最佳基线提升2.8%;在小样本场景(few-shot, with gradient-based fine-tuning)中,SMAT以75.02%的准确率刷新SOTA纪录。
自然语言基座模型验证:SuperNaturalInstruction跨任务泛化能力基准测试。
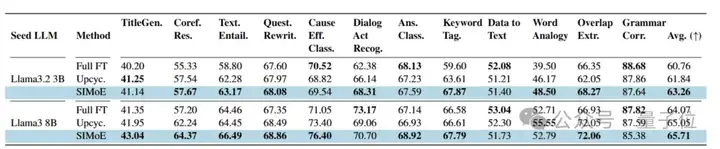
SIMoE在跨任务泛化能力上展现统治级表现。在12类未见任务中,SIMoE在9类任务上显著领先:3B模型较全微调基线提升2.5%,8B模型提升1.6%。
自然语言基座模型验证:Tulu-v3 SFT Mixture多领域泛化能力基准测。

SIMoE在大规模场景仍保持性能统治力。面对8B参数基座模型和百万级指令数据,SIMoE在MMLU、GSM8K等12项核心基准平均得分61.1%,以0.6%优势超越当前SOTA模型Tülu-v3-8B-SFT,在指令遵循(IFEval +1.3%)和安全测试(Safety +1.7%)等任务中展现明显优势。
引用文献:
[1] Sainbayar Sukhbaatar, et al. “Branch-train-mix: Mixing expert LLMs into a mixture-of-experts LLM”. In First Conference on Language Modeling.
论文链接:
ICML 2024:https://arxiv.org/abs/2403.08477
ACL 2025:https://arxiv.org/pdf/2506.12597
项目链接:
https://szc12153.github.io/sparse_meta_tuning/
文章来自于“量子位”,作者“SIMoE团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
