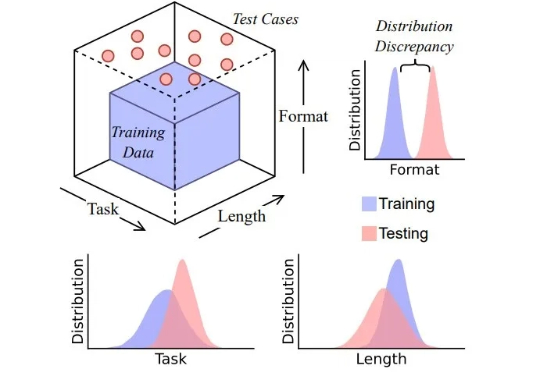
链式思维是幻象吗?从数据分布视角重新审视大模型推理,马斯克回复,Grok破防
链式思维是幻象吗?从数据分布视角重新审视大模型推理,马斯克回复,Grok破防思维链 (CoT) 提示技术常被认为是让大模型分步思考的关键手段,通过在输入中加入「Let’s think step by step」等提示,模型会生成类似人类的中间推理步骤,显著提升复杂任务的表现。然而,这些流畅的推理链条是否真的反映了模型的推理能力?
来自主题: AI技术研报
8060 点击 2025-08-15 12:38
 搜索
搜索
思维链 (CoT) 提示技术常被认为是让大模型分步思考的关键手段,通过在输入中加入「Let’s think step by step」等提示,模型会生成类似人类的中间推理步骤,显著提升复杂任务的表现。然而,这些流畅的推理链条是否真的反映了模型的推理能力?
随着推理大模型和思维链的出现与普及,大模型具备了「深度思考」的能力,不同任务的泛用性得到了很大的提高。
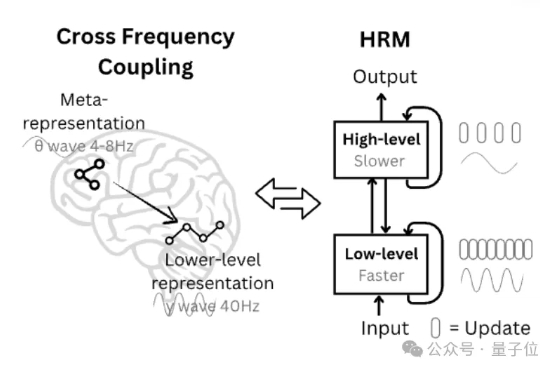
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。

如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。 就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。 Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。
离开OpenAI,只是为了Meta天价薪资?Jason Wei离职博客,泄露天机:未来AI更令人向往!

这次是真真真挖到OpenAI大动脉了。 Jason Wei,思维链的提出者、o1系列模型的关键人物,被曝也被扎克伯格请走,即将入职Meta。
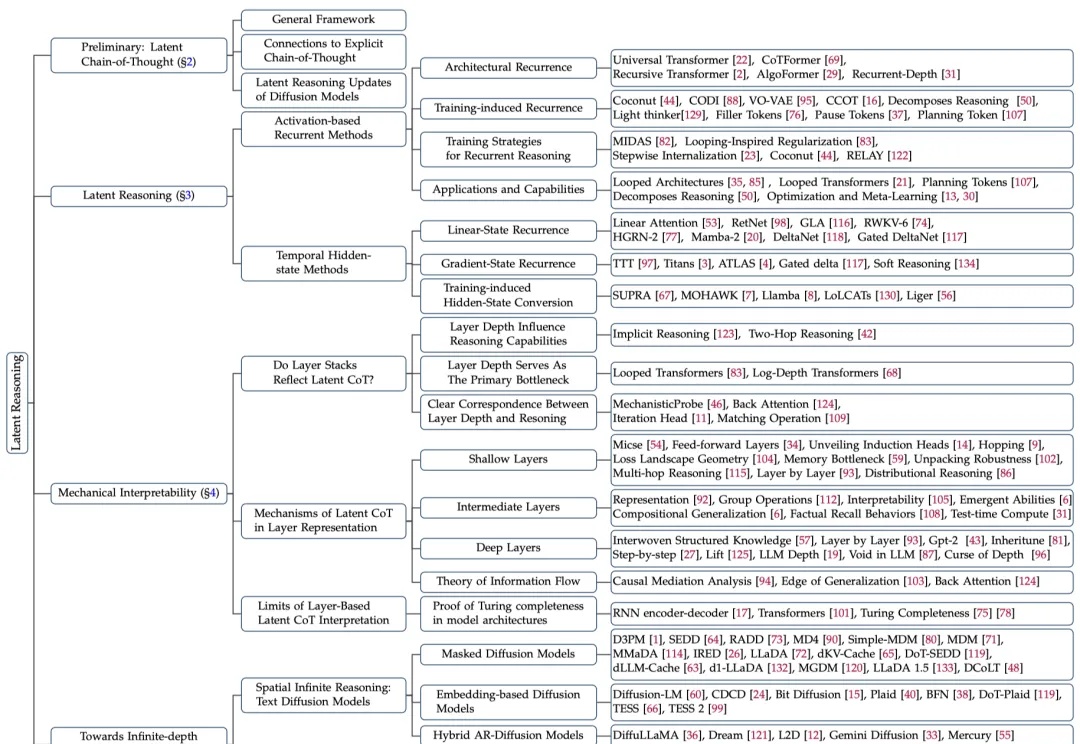
大模型在潜空间中推理,带宽能达到普通(显式)思维链(CoT)的2700多倍?
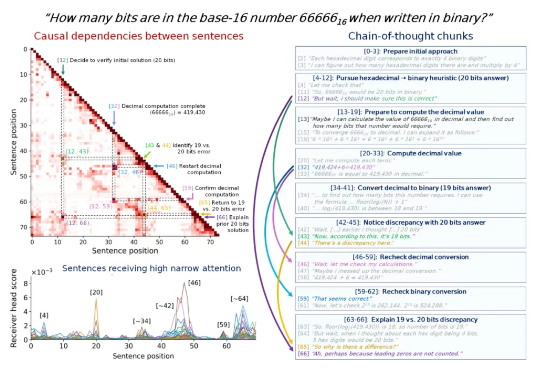
思维链里的步骤很重要,但有些步骤比其他步骤更重要,尤其是在一些比较长的思维链中。 找出这些步骤,我们就可以更深入地理解 LLM 的内部推理机制,从而提高模型的可解释性、可调试性和安全性。