大模型越反思越错,原来是长链推理通过自我说服加重幻觉 | 北邮
大模型越反思越错,原来是长链推理通过自我说服加重幻觉 | 北邮当推理链从3步延伸到50+步,幻觉率暴增10倍;反思节点也束手无策。
来自主题: AI技术研报
9263 点击 2025-07-04 09:35
 搜索
搜索
当推理链从3步延伸到50+步,幻觉率暴增10倍;反思节点也束手无策。

原来,CoT推理竟是假象!Bengio带队最新论文戳穿了CoT神话——我们所看到的推理步骤,并非是真实的。不仅如此,LLM在推理时会悄然纠正错误,却在CoT中只字未提。
像人一样推理。 大模型的架构,到了需要变革的时候? 在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。
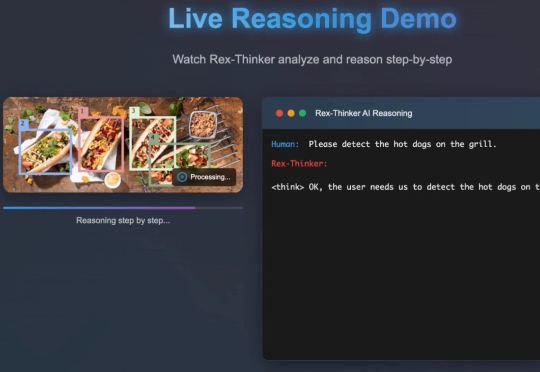
在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。
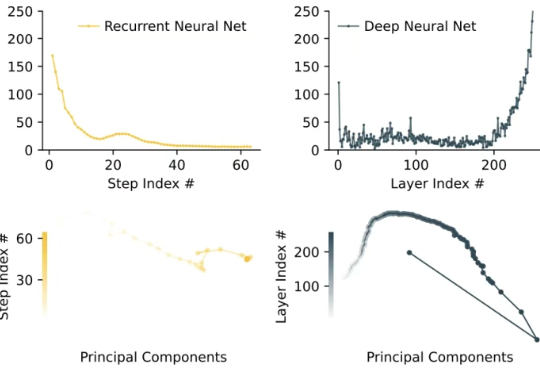
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。

AI也有量子叠加态了?

GRIT能让多模态大语言模型(MLLM)通过生成自然语言和图像框坐标结合的推理链进行「图像思维」,仅需20个训练样本即可实现优越性能!

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
奥特曼使用大模型的方法,竟然是错的?
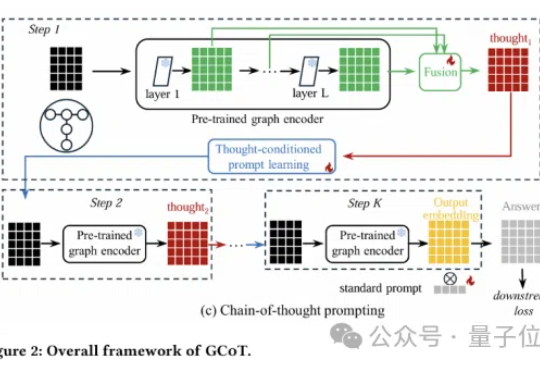
图神经网络还能更聪明?思维链提示学习来了!