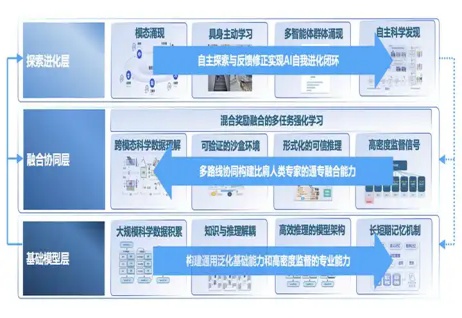
通专融合,思维链还透明,上海AI Lab为新一代大模型打了个样
通专融合,思维链还透明,上海AI Lab为新一代大模型打了个样OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
来自主题: AI技术研报
11491 点击 2025-05-24 15:33
 搜索
搜索
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
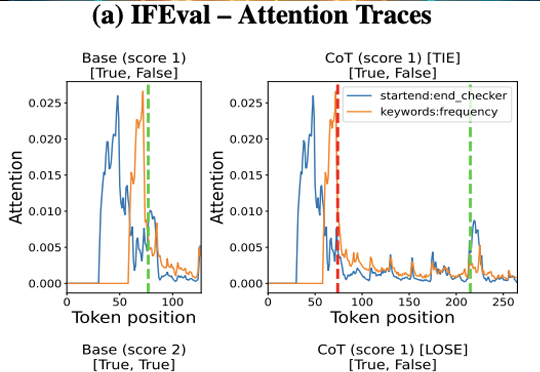
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!

《Why We Think》。 这就是北大校友、前OpenAI华人VP翁荔所发布的最新万字长文—— 围绕“测试时计算”(Test-time Compute)和“思维链”(Chain-of-Thought,CoT),讨论了如何通过这些技术显著提升模型性能。
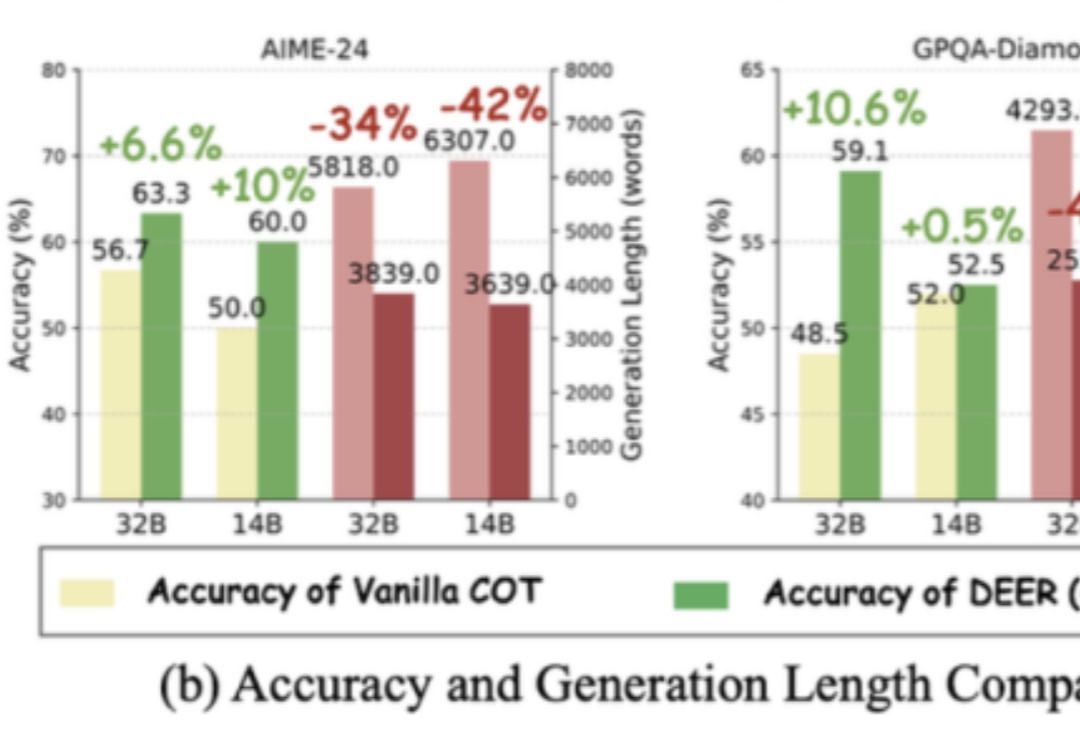
长思维链让大模型具备了推理能力,但如果过度思考,就有可能成为负担。
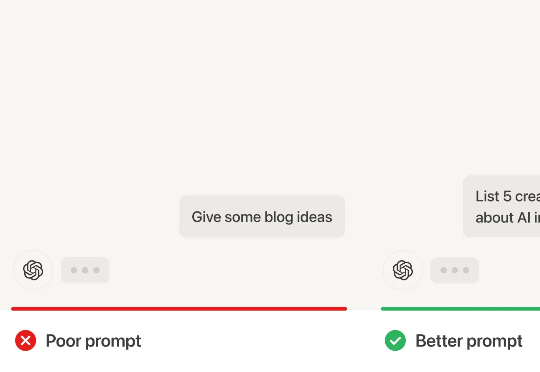
AI输出陷入"无效对话"困境?其实是你不懂提问的艺术。从指令颗粒度拆解到思维链编织,本文揭示精准提问如何唤醒AI潜能——与其焦虑技术颠覆,不如掌握这套数字化时代的元能力,让语言真正成为撬动生产力的支点。文章来自编译。
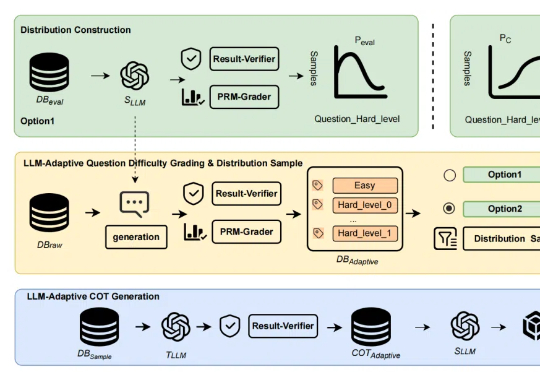
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。

尽管LLM看似能够进行流畅推理和问题解答,但它们背后的思维链其实只是复杂的统计模式匹配,而非真正的推理能力。AI模型仅仅通过海量数据和经验法则来生成响应,而不是通过深刻的世界模型和逻辑推理来做决策。
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。
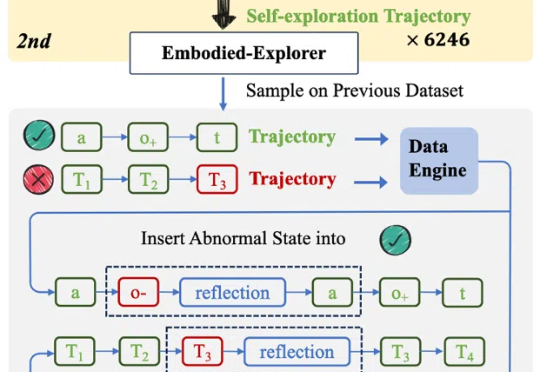
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。

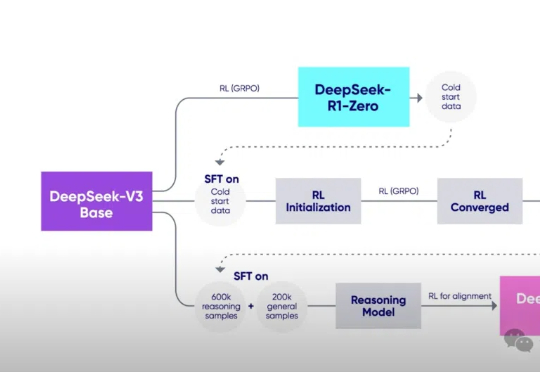
DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。