
首个三模式大语言模型:4倍token吞吐量,长文本秒级时代要来了?
首个三模式大语言模型:4倍token吞吐量,长文本秒级时代要来了?英伟达提出了全球首个三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。
来自主题: AI技术研报
9420 点击 2026-05-22 15:33
 搜索
搜索
英伟达提出了全球首个三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。
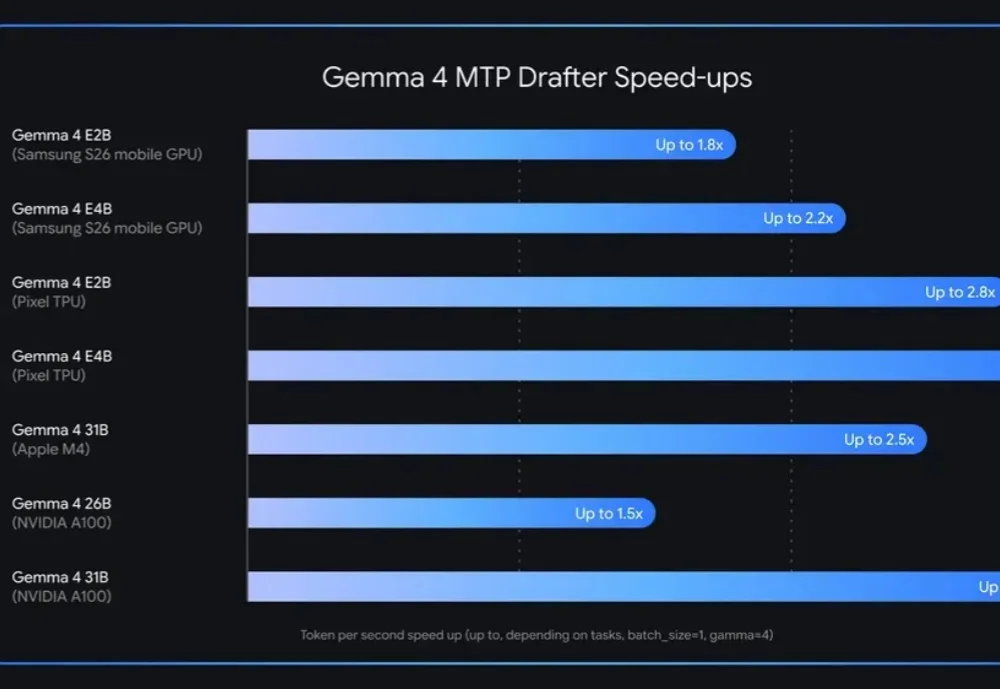
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。
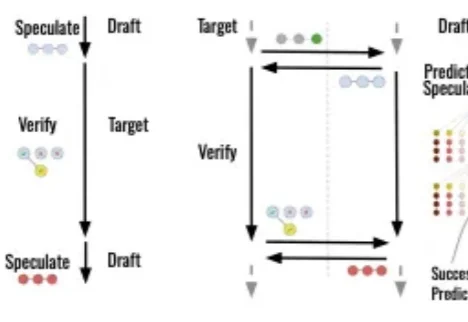
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。

目前,最先进的对齐方法是使用知识蒸馏(Knowledge Distillation, KD)在所有 token 上最小化 KL 散度。然而,最小化全局 KL 散度并不意味着 token 的接受率最大化。由于小模型容量受限,草稿模型往往难以完整吸收目标模型的知识,导致直接使用蒸馏方法的性能提升受限。在极限场景下,草稿模型和目标模型的巨大尺寸差异甚至可能导致训练不收敛。

近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

推测解码(Speculative Decoding)是谷歌等机构在 2022 年发现的大模型推理加速方法。它可以在不损失生成效果前提下,获得 3 倍以上的加速比。GPT-4 泄密报告也提到 OpenAI 线上模型推理使用了它。

去年,在加速大语言模型推理层面,我们迎来了一个比推测解码更高效的解决方案 —— 普林斯顿、UIUC 等机构提出的 Medusa。如今,关于 Medusa 终于有了完整技术论文,还提供了新的版本。