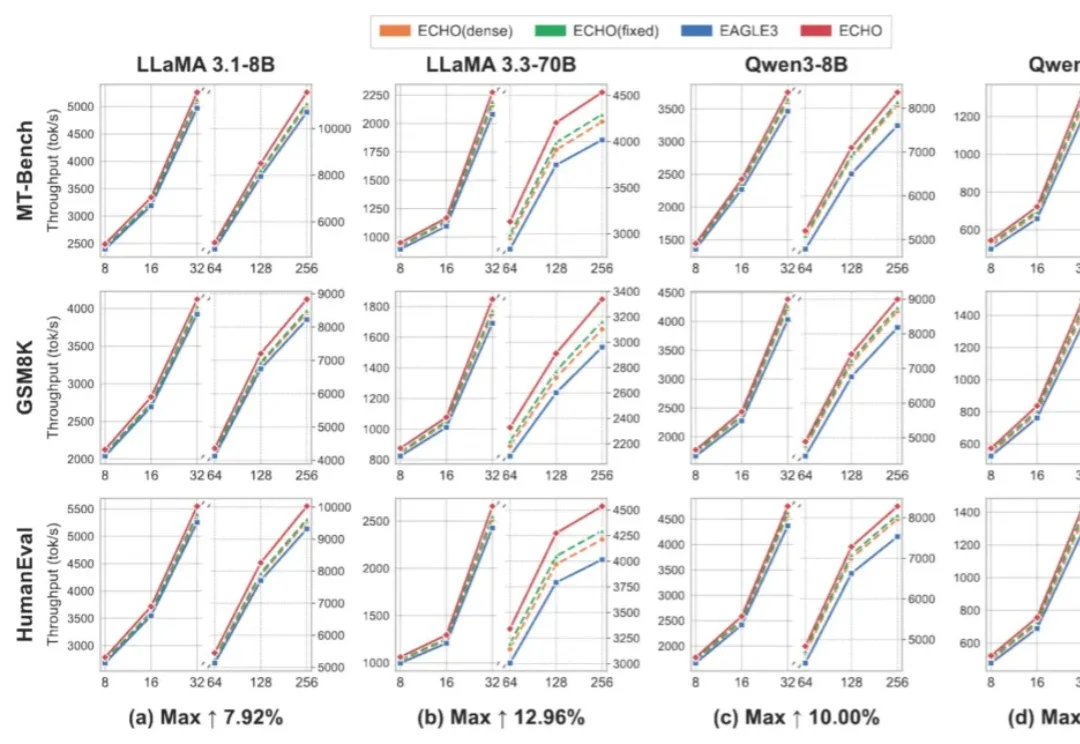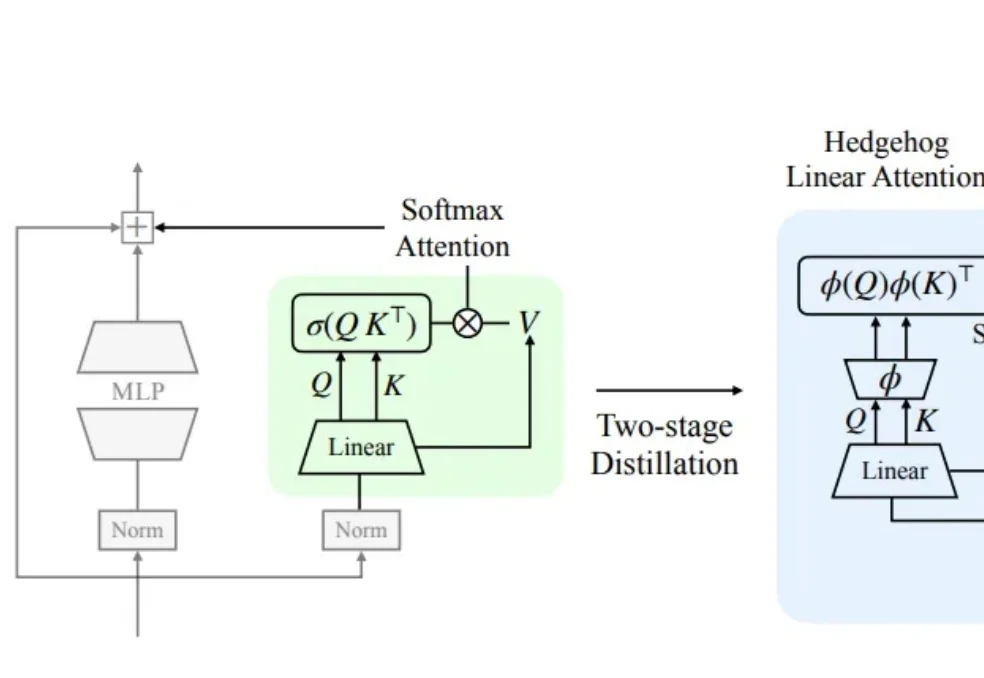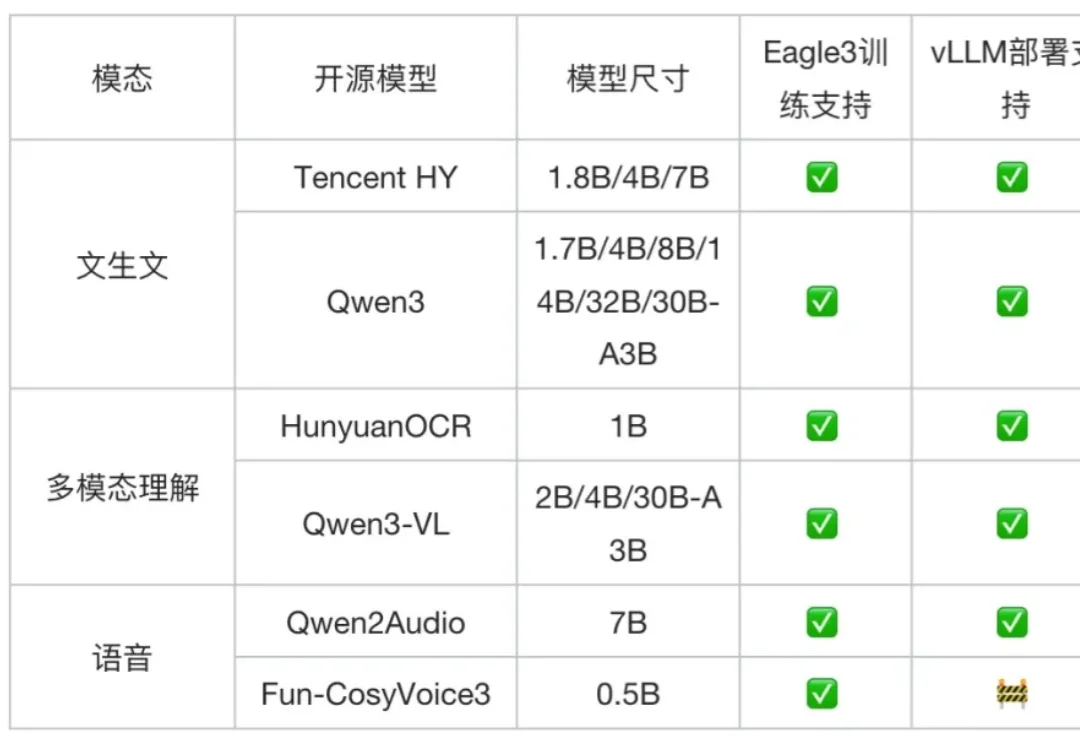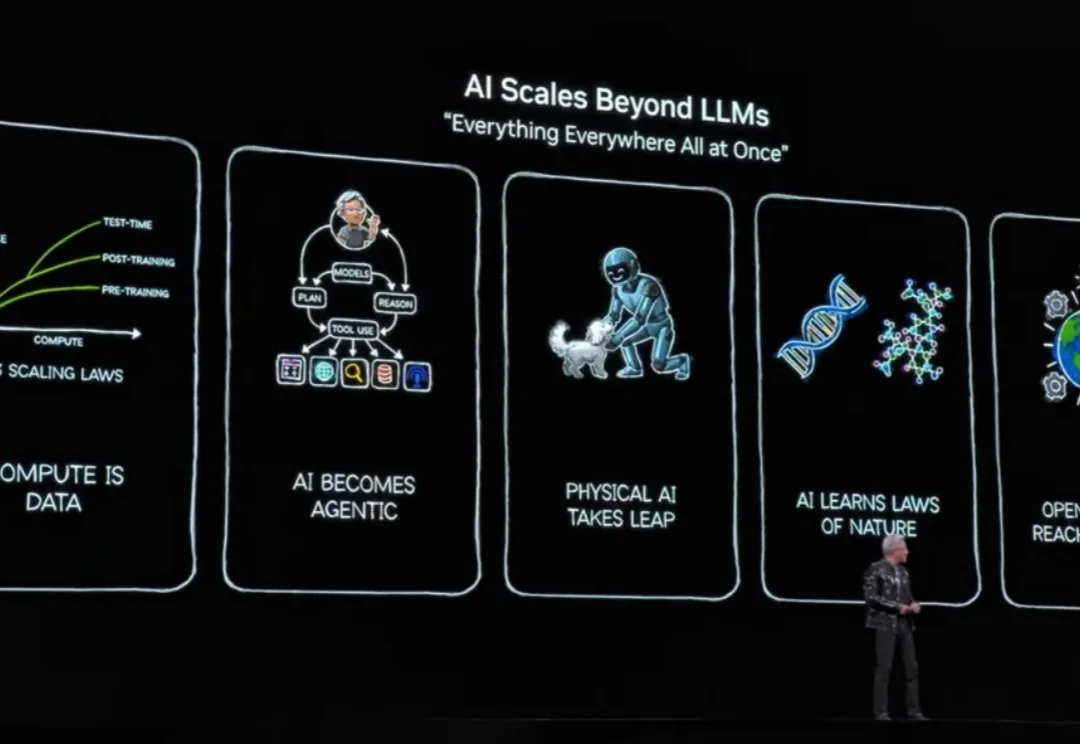
速递|Base44推出自研氛围编程模型Base1,降低对Anthropic等外部API依赖,降低推理成本
速递|Base44推出自研氛围编程模型Base1,降低对Anthropic等外部API依赖,降低推理成本Base44 是一家 vibe-coding 平台,一年前被 Wix 以 8000 万美元收购。当时,这家公司成立还不到六个月,团队只有 8 个人。如今,Base44 开始推出自己的 AI 模型,帮助用户通过自然语言创建应用。
来自主题: AI资讯
9679 点击 2026-07-02 14:53