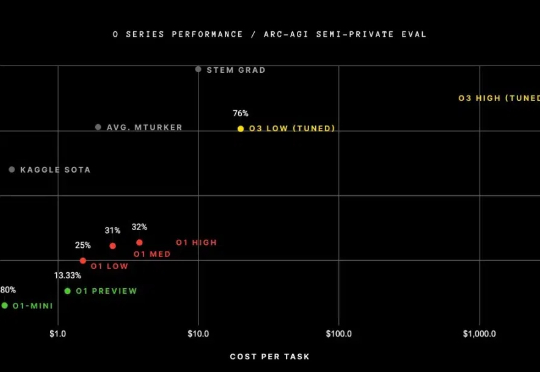
从o1-mini到DeepSeek-R1,万字长文带你读懂推理模型的历史与技术
从o1-mini到DeepSeek-R1,万字长文带你读懂推理模型的历史与技术自 OpenAI 发布 o1-mini 模型以来,推理模型就一直是 AI 社区的热门话题,而春节前面世的开放式推理模型 DeepSeek-R1 更是让推理模型的热度达到了前所未有的高峰。
来自主题: AI技术研报
9895 点击 2025-02-24 14:40
 搜索
搜索
自 OpenAI 发布 o1-mini 模型以来,推理模型就一直是 AI 社区的热门话题,而春节前面世的开放式推理模型 DeepSeek-R1 更是让推理模型的热度达到了前所未有的高峰。
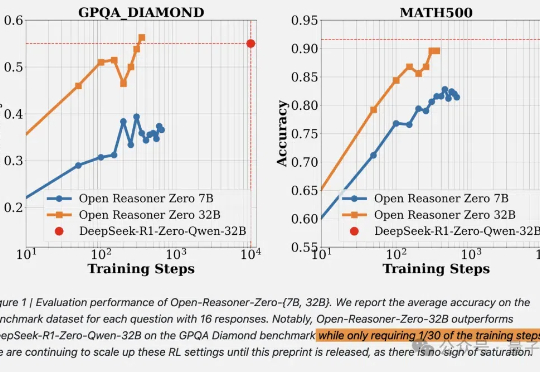
DeepSeek啥都开源了,就是没有开源训练代码和数据。现在,开源RL训练方法只需要用1/30的训练步骤就能赶上相同尺寸的DeepSeek-R1-Zero蒸馏Qwen。
DeepSeek-R1这样的推理模型有着强大的深度思考能力,但也有着一些不同于通用模型的特点与用法,比如不支持函数调用,不支持结构化输出,o1甚至不支持系统提示(System Prompt)等。尽管这和它们的使用场景有关,但有时也会带来不便。今天我们就来说说结构化输出这个常见的问题。
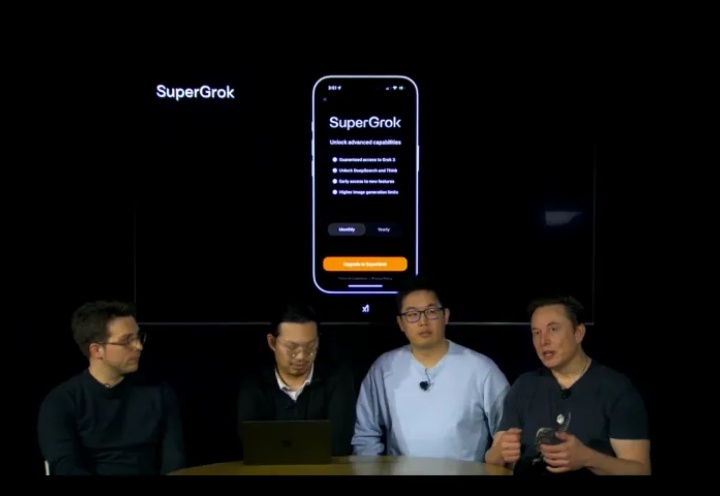
2月18日,被马斯克称为“地球上最聪明的人工智能”Grok 3推理模型亮相。发布会直播现场,他和带队工程师分坐两旁,将C位留给了两位主要负责模型研究的华人科学家。

一些推理模型的使用技巧和启示

AI竞赛白热化!Anthropic秘密研发一种与众不同的AI——语言模型与可控推理能力相结合的混合模型。模型包括一个独特的「滑动条」功能,它赋予开发者对计算资源和成本前所未有的控制权。
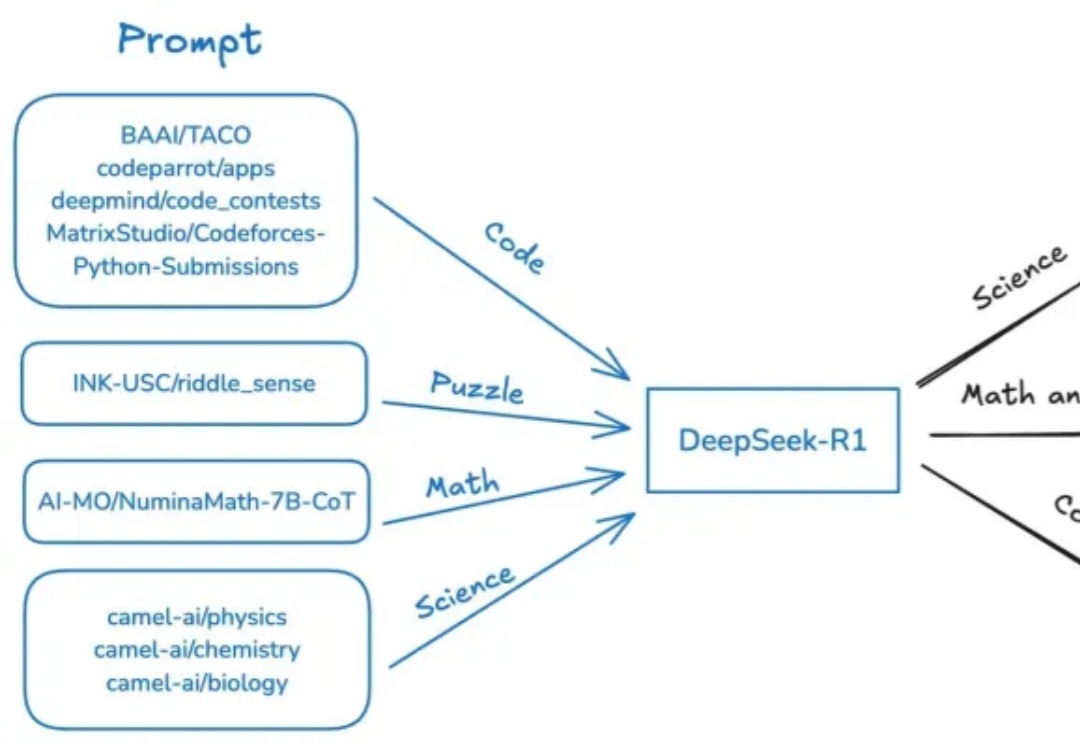
近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。

奥特曼回应一切,OpenAI路线图全曝光。GPT-4.5数周发布,成为GPT系最后一个非推理模型。GPT-5将整合o系和GPT系,打造成一个全能系统。最令人兴奋的是,所有人皆可免费用上GPT-5。
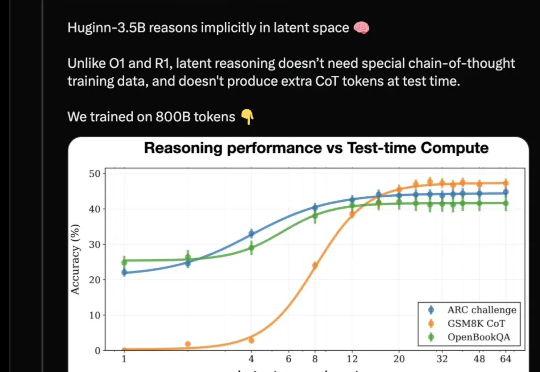
开源推理大模型新架构来了,采用与Deepseek-R1/OpenAI o1截然不同的路线: 抛弃长思维链和人类的语言,直接在连续的高维潜空间用隐藏状态推理,可自适应地花费更多计算来思考更长时间。

这一篇文章来源于我自己的困惑而进行的探索和思考,再进行多次讨论后总觉隔靴搔痒,理解不透彻。 而在我自己整理后,发现已经有小伙伴点明了他们的区别。但是因为了解深度的不够,即使告诉了答案,我也无法理解,总有隔靴搔痒之感。