美团王兴,又开源一款大模型!
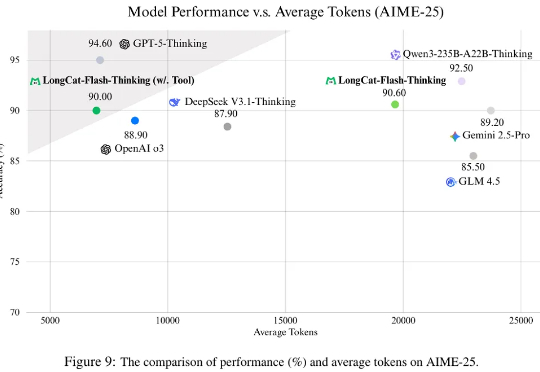
美团王兴,又开源一款大模型!最近,美团在AI开源赛道上在猛踩加速。今天,在开源其首款大语言模型仅仅24天后,美团又开源了其首款自研推理模型LongCat-Flash-Thinking。与其基础模型LongCat-Flash类似,效率也是LongCat-Flash-Thinking的最大特点。美团在技术报告中透露,LongCat-Flash-Thinking在自研的DORA强化学习基础设施完成训练
来自主题: AI技术研报
9307 点击 2025-09-22 23:05