# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。
如果 scale-up 长链思维是通往 AGI 的路径,那么现有思维链的冗长问题是我们亟待解决的。
那么,能不能让模型「少说废话」,既快又准?
过去的尝试大多失败:各种复杂的长度惩罚(Length Penalty)要么让模型乱答,要么训练不稳定,结果就是效率提升了,准确率却掉了。
现在,英伟达研究院的最新研究给出了答案:关键不在于设计多复杂的惩罚,而在于用对强化学习优化方法。

DLER 首先是细致及全面了分析了引入长度惩罚之后出现的新的强化学习训练问题,包括:
对于这些问题,DLER 提出了一套简单却强大的强化学习训练配方:
基于 DLER 这套训练方法,得到的模型结果令人震惊。新模型产生的推理长度竟然可以减少 70% 以上,但准确率完全保持。在 AIME-24 数学基准上,DLER-Qwen-R1-7B 平均仅用 3230 Tokens 就达到 55.6% 准确率,而 DeepSeek-R1-7B 要花 13241 Tokens 才能做到 55.4%。
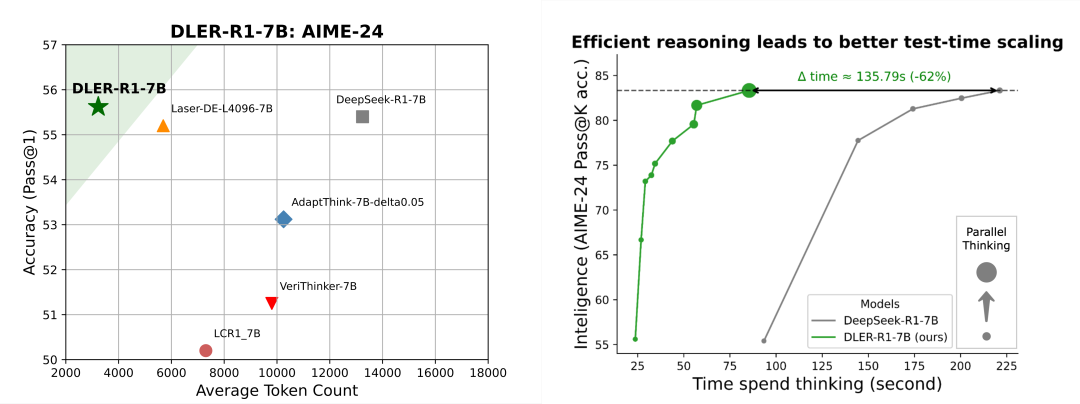
DLER 不仅实现了回复问题更短的输出,更是从另外角度增加了每 token 的智能含量。 在同样的推理时间内,相比于传统的推理模型只能生成一条冗长推理,DLER 模型能并行生成几十条简明推理,最终准确率比 DeepSeek-R1 高出近 50%。这一实验也意味着高效推理才是 Test-time Scaling 的关键。
DLER 的研究揭示了几个颠覆性结论:
更令人惊喜的是,DLER 不仅适用于小模型,在大模型上同样奏效。研究团队还提出了权重选择性合并(magnitude-selective weight merging),解决了大模型用公开数据微调时的性能下降问题:既能恢复全部准确率,又能保持近一半的长度压缩。
这项来自 NVIDIA 的最新工作,让我们重新认识了推理模型的未来方向。首先,推理模型不能只是一味拉长推理链条,而是需要更聪明、更高效地思考。其次,通过 DLER,模型能以更少的 Tokens、更短的时间,做到更高的准确率。 如果说之前的研究 ProRL 让模型「开窍」,那么 DLER 就是帮模型「瘦身健身」,让它们更快、更强、更实用。未来在实际部署中,DLER 无疑会成为让推理模型真正落地的关键技术之一。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
