
一文看懂Gen AI浪潮下数据中心的新机遇
一文看懂Gen AI浪潮下数据中心的新机遇数据中心设计转向高功率密度应对AI需求增长。
来自主题: AI资讯
8651 点击 2024-10-16 15:41
 搜索
搜索
数据中心设计转向高功率密度应对AI需求增长。

TeleAI 李学龙团队提出具身世界模型,挖掘大量人类操作视频和少量机器人数据的共同决策模式。

AI对待每个人类都一视同仁吗? 现在OpenAI用53页的新论文揭示:ChatGPT真的会看人下菜碟。 根据用户的名字就自动推断出性别、种族等身份特征,并重复训练数据中的社会偏见。

按照传统,FDA会每年秋季都会更新一次人工智能数据库,目前,FDA数据库中共有950个设备。 截至2024年10月,还没有任何使用生成式人工智能或由大型语言模型驱动的设备获批。
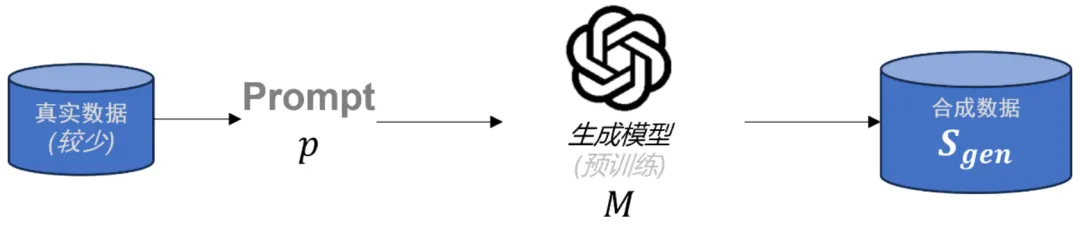
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。

多模态AI是一种将不同形式的数据(如文本、图像、音频等)融合在一起的技术,旨在让模型从多个维度感知和理解信息。这种融合使得AI系统能够从每种模态中获取独特的但互补的信息,从而构建出更全面的世界观。例如,在一个自动驾驶场景中,图像数据可以帮助系统识别道路上的行人,而雷达数据则能够感知车距,两者结合能够显著提升决策准确性。

LightRAG通过双层检索范式和基于图的索引策略提高了信息检索的全面性和效率,同时具备对新数据快速适应的能力。在多个数据集上的实验表明,LightRAG在检索准确性和响应多样性方面均优于现有的基线模型,并且在资源消耗和动态环境适应性方面表现更优,使其在实际应用中更为有效和经济。

经过三年的努力,ImageNet成为了一个包含1500万张互联网图像的数据集,涵盖了22000个物体类别概念。

随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。