
速递|软银组建Roze AI:用自主机器人建造数据中心,目标估值1000亿美元
速递|软银组建Roze AI:用自主机器人建造数据中心,目标估值1000亿美元科技公司正竞相建设基础设施,以进一步推动自动化浪潮。如今,日本跨国企业软银据报计划成立一家新公司,专门负责自动化建设这些基础设施。
来自主题: AI资讯
10010 点击 2026-05-06 14:29
 搜索
搜索
科技公司正竞相建设基础设施,以进一步推动自动化浪潮。如今,日本跨国企业软银据报计划成立一家新公司,专门负责自动化建设这些基础设施。

2026 年,「数据」正成为具身智能竞赛的新焦点,京东、百度等科技巨头纷纷入局。然而,喧嚣之中,一个根本问题悬而未决:什么样的数据,才是具身智能真正需要的?
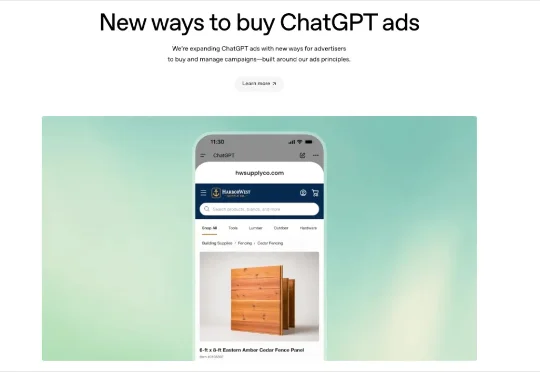
OpenAI准备向企业主全量上线广告平台了。这个非常有意思,我觉得还是可以聊聊的。这玩意你可以理解成,ChatGPT的广告投放后台,美国的企业主可以直接注册账号,充钱,设预算,选竞价策略,上传广告素材,然后一键投放到ChatGPT的对话里,最后实时看数据,实时优化。

Anthropic联合创始人Jack Clark读完数百份公开数据,得出一个让他自己也坐不住的结论:2028年底前,AI自己造AI的概率是60%。支撑他这一判断的,是编程、科研复现、模型训练优化等多条能力曲线:每一条都在向右上方飞,没有减速迹象。
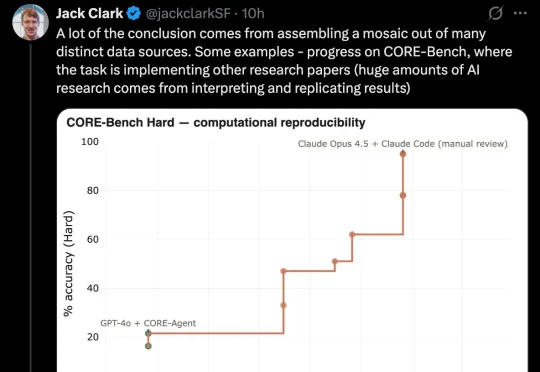
AI 很快就能自己改造自己了?Anthropic 联合创始人 Jack Clark 发帖称,他最近几周阅读了大量公开的 AI 开发数据后,认为到 2028 年底,递归自我改进(recursive self-improvement)发生的概率有 60%。

斯坦福大学宣布:将旗下两大AI与数据科学组织——Stanford HAI(以人为本人工智能研究院)和Stanford Data Science(斯坦福数据科学)合并为一个统一机构,名称保留Stanford HAI,由计算机科学家James Landay全面掌舵。
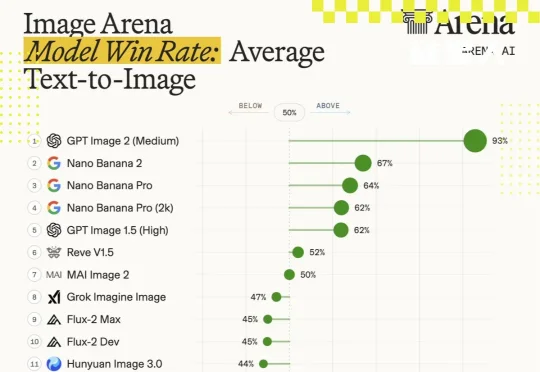
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。

来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。

系列:卧底GEO三十天(2/3)我学会了一种新算术。不是加减乘除那种,是GEO行业专属的。入职第二周,我从内容组调到了效果交付组。组长是个瘦高的姑娘,大家叫她阿梅,说话很快,手指敲键盘更快。她看了看我,说:"你数学好不好?"

天弘基金持有人数据显示,2025年末,公司旗下所有AI产业链指数产品的95后持有人户数同比增长92.14%;00后持有人户数同比增长超2倍。而05后入场AI投资的势头最为迅猛,持有人户数较2024年末猛增十倍。整体来看,30岁以下持有人占比从2024年的1.94%近乎翻倍至3.78%。