# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 AI 领域,我们对模型的期待总是既要、又要、还要:模型要强,速度要快,成本还要低。但实际应用时,高质量的向量表征往往意味着庞大的数据体积,既拖慢检索速度,也推高存储和内存消耗。
量化(Quantization)正是破解这一矛盾、实现规模化应用的关键技术。量化是一种常用的神经网络模型压缩技术,本质并不复杂:通过把高精度的小数四舍五入成更粗的整数,主动牺牲一部分精度,换来模型体积的大幅缩减。
量化不仅节省了存储和内存,还让向量计算变得更快,显著提升了检索效率。更重要的是,量化作为一种通用的数值优化手段,它不挑数据、不看场景、不依赖特定领域知识,适用于各类模型和应用场景。
一般认为,量化总会牺牲精度,有得必有失。但我们发现,通过量化感知训练(Quantization-Aware Training, QAT),可以在压缩体积的同时,最大程度保留模型性能。我们已经将这一技术应用在 jina-embeddings-v4,为极致空间敏感的场景带来更小、更高效的向量表征。
Jina Embeddings v4 是我们最新推出的为搜索而生的四代目模型,全球首个集多模态、多向量、多语言于一体的开源向量模型。
HF 🤗 https://huggingface.co/jinaai/jina-embeddings-v4
技术报告 📖 https://arxiv.org/abs/2506.18902
API 💻 https://jina.ai/embeddings/
模型量化是提升大模型落地效率的关键工具。结合实际应用背景,目前主流的量化方法大致可以分为四类:
1. 训练后量化 (Post-training quantization, PTQ)
这种方法最为直接,针对已经训练好的向量模型,直接对输出的浮点数进行取整或缩放处理。模型本身的结构和参数不会发生变化,不需要再进行额外训练。。常用于快速压缩向量体积,操作简单,见效快,但模型本身大小和推理速度不变。
2. 输出量化感知训练 (Training for quantized embedding outputs, Output QAT)
这种方法的关键在于:让模型在训练阶段就知道输出会被量化。 通过在训练过程中引入量化操作,模型主动适应低精度输出的限制,自动调整参数,使量化后的向量尽量保留原始信息。
虽然模型参数会有所调整,但模型权重的精度保持不变,因此模型整体的体积不会缩小,变化的只是输出向量的尺寸。适合对模型结构和推理速度有要求,但希望输出更紧凑的场景。
3. 全量化感知训练 (Training for fully quantized models, Full QAT)
以一个训练好的高精度模型为起点,先将模型权重降低到目标精度,再针对精度损失进行再训练和微调。最终不仅能获得更小的向量表征,还能压缩模型体积、加速推理。由于涉及权重和结构的全面调整,这种方法对训练资源和工程成本的要求最高。
4. 蒸馏 (Distillation)
蒸馏是一种以大带小的策略,通过用一个强大的大模型(教师模型)生成大量训练数据,来训练一个专为量化设计、结构更小的新模型(学生模型)。实现模型和向量的双重压缩,性能接近原模型,适合极致压缩和加速场景,但开发周期较长。
下表总结了这四种方法的特点:
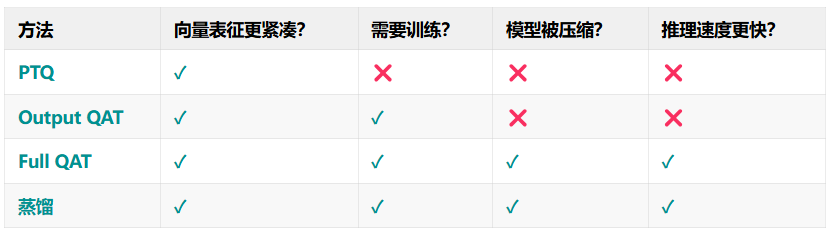
简单总结一下:四种方法都能实现向量压缩,但除了压缩向量外,还想同时获得更小、更快的模型,则需选择全量化感知训练(Full QAT) 或蒸馏,并承担更高的训练成本。
考虑到应用门槛和性价比,本文将聚焦于训练后量化(PTQ)和输出量化感知训练(Output QAT)这两种无需更改模型结构、也不影响推理速度的量化方案。它们能够大幅减小向量体积,在实际场景中应用门槛低,易于落地。
本次实验选择 jina-embeddings-v4 作为基准模型,配备了检索任务专用的 LoRA 适配器。默认状态下,它会生成 2048 维的 FP32(32 位浮点)向量,每个向量占用 8KB 存储空间。
我们在 NanoBEIR 基准上,系统性地评估了多种量化级别(8bit、4bit、三元、二元),并分别采用训练后量化(PTQ)和输出向量量化感知训练(Output QAT)两种策略。部分实验还对比了不同的缩放方法(最大最小值与滚动平均缩放)。
(注:本次实验均使用该模型的内部测试版,其公开发布版的性能会更高。)
我们测试了以下四种不同粒度的量化等级,它们的压缩效果层层递进:
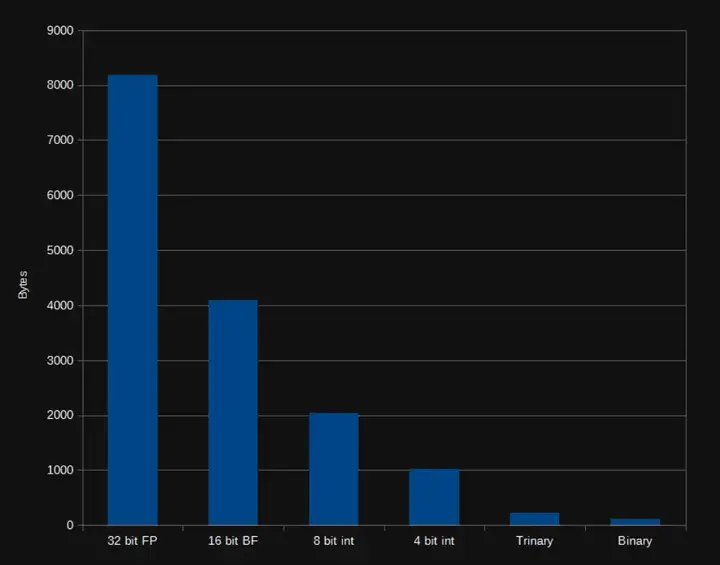
不同量化等级带来的向量体积压缩效果
在二元量化中,操作极为直接:每个数值只需判断正负,正数映射为 1,零和负数映射为 -1。
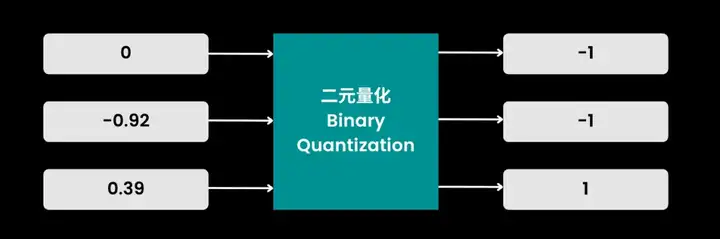
二元量化。所有负值变为-1,其他值变为1。
其他量化方式则需要先将原始向量的数据范围(理论上是无穷大)映射到一个有限区间 [min, max],然后再进行取整。我们主要采用了两种区间确定方法:一是直接取每批数据的最大/最小值,二是通过滚动平均动态调整区间。
三元量化的规则:
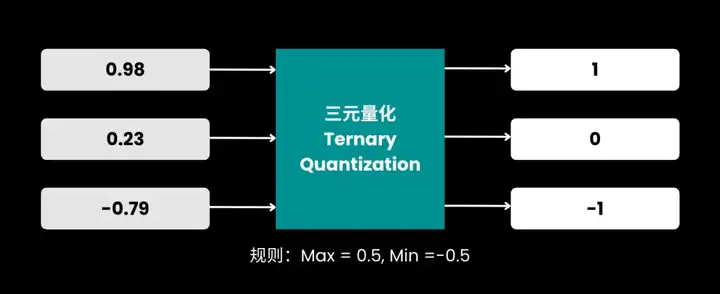
三元量化示意图:设定阈值区间,区间内所有数值归零,区间外分别映射为 -1 和 1
4 位整数量化的规则:
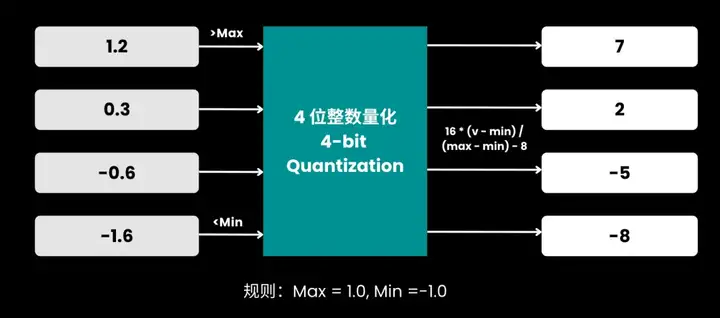
4位量化示意图:所有数值根据区间归一化并离散到 [-8, 7],边界外分别截断为 -8 和 7
8 位整数量化的规则:
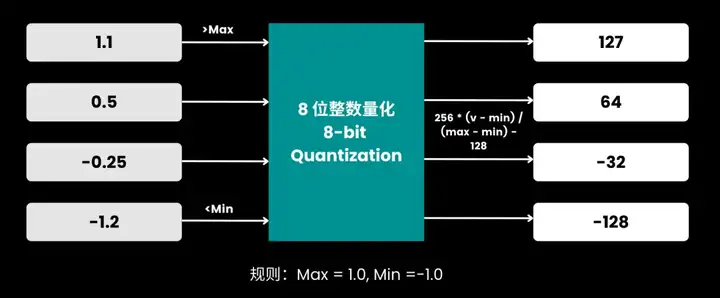
8位量化示意图:所有数值映射并离散到 [-128, 127] 区间
为了确定缩放边界 max 和 min,我们探索了两种策略:
两种量化策略的实验方法有所不同。对于训练后量化(PTQ),我们冻结原模型,仅对它的输出向量应用前述的量化方法。
对于输出量化感知训练(Output QAT),为了能够有效微调,我们采用了直通估计器 (Straight-Through Estimation, STE) 技术。它的核心机制是,在前向传播时对输出进行量化,但在反向传播计算损失时,将量化结果还原为全精度数值,从而用全精度的损失信号来优化模型参数。
我们将每种配置都微调了 10000 步,并每隔 500 步保存一个模型检查点(checkpoint)。训练结束后,我们从所有检查点中,选出在 NanoBEIR 基准测试上得分最高的那一个作为最终模型。
值得注意的是,PTQ 和 Output QAT 这两种方法,其优化的重点在于减小向量的尺寸,从而节省存储空间并提升检索速度。它们并不会压缩模型本身的体积,也不会加快模型的推理(即向量生成)过程。
考虑到在检索场景中,需要长期大量存储的是文档向量,而用户的查询向量则是临时生成的。基于这一点,我们设计并测试了一种非对称量化 (Asymmetric Quantization) 方案:
只量化需要海量存储的『文档向量』,而用于即时检索的『查询向量』则保持完整的原始精度。
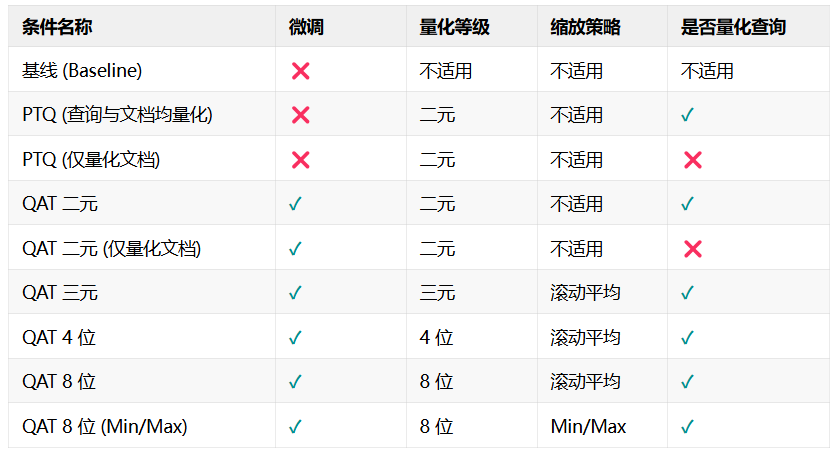
我们总计测试了九种实验条件,所有实验配置与最终在 NanoBEIR 基准上的平均得分汇总如下
实验条件一览
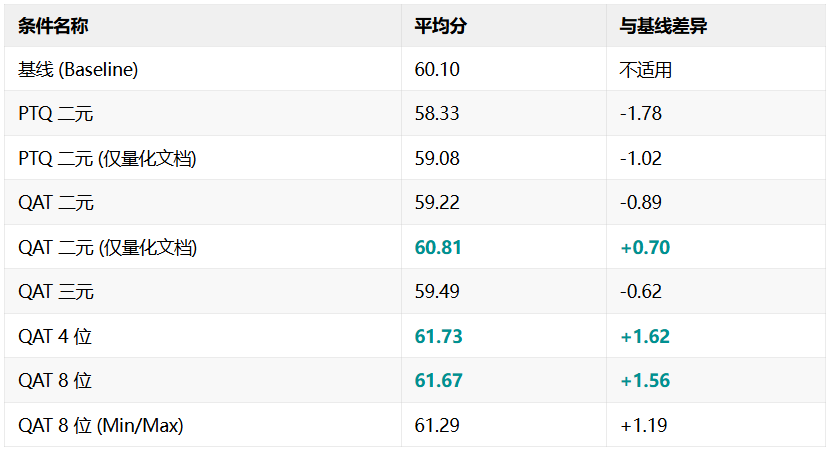
在 12 个 NanoBEIR 基准测试中,各条件的平均得分(正确率%)
从实验数据中,我们可以解读出几个清晰的趋势。
首先,微调的价值无可替代。 训练后量化(PTQ)与 量化感知训练(Output QAT) 在二元量化条件下,唯一差异是是否微调,但 QAT 得分明显更高;即便只量化文档,QAT 依然带来近 2% 的提升,充分说明量化感知训练的实际价值。
其次,量化精度与表现成正比。 精度越低,压缩越激进,性能损失越大。4 位优于三元,三元优于二元。但值得注意的是,8 位与 4 位之间几乎没有差别,或许说明量化存在性能阈值。
再次,非对称量化能有效提升性能。 在二元量化中,仅量化文档的 QAT 方案性能达到了 60.81 分,成功超越了基线。这证明了在查询侧保留完整信息的有效性。
最后,动态缩放优于静态缩放。滚动平均法在信息保留上优于简单 min/max,带来了更优的整体表现。
量化技术大幅压缩了向量体积,加快检索速度,为实际应用带来直接的运营优势。
我们的实验显示,简单的训练后量化(PTQ) 操作简单但有精度损失;输出量化感知训练(Output QAT)在训练阶段让模型主动适应量化,能有效缓解性能损失,表现更优。
整体来看,量化程度直接影响着模型性能,毕竟这项技术的基础就是降低数值精度。所以量化越温和,性能越好,比如 4 位优于二元量化;但令人意外的是,在 Jina Embeddings v4 上,8 位量化和 4 位量化之间的性能没有显著差异。这或许意味着,精度存在一个阈值:在跨过某个临界点之前,进一步放宽或收紧量化程度,对模型性能的影响可能微乎其微。
此外,缩放策略同样关键。实验表明,滚动平均缩放法明显优于固定的最大最小值缩放法。 更能适应数据分布,值得深入探索。
总之,量化能帮您用更低成本,发掘向量模型的更大价值。本文虽然未能覆盖所有量化选项,但深入探讨的这两种方法都容易实现,且收益实在。我们对量化技术的探索不会止步,jina-embeddings-v4 的二元量化支持也即将推出,敬请期待。
文章来自于“Jina Al”,作者“Jina Al”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
