谷歌突砍Gemini免费版炸锅,数据养模遭背刺?GPT-5.2突袭Gemini 3,Demis Hassabis:谷歌须占最强位
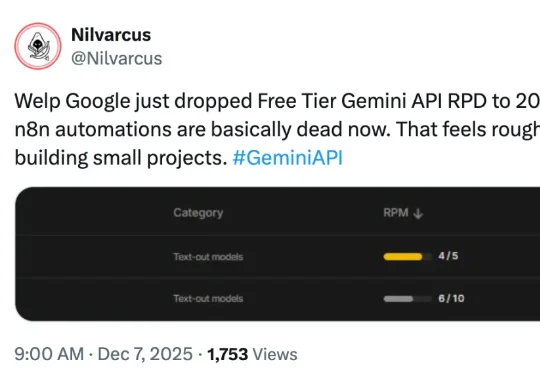
谷歌突砍Gemini免费版炸锅,数据养模遭背刺?GPT-5.2突袭Gemini 3,Demis Hassabis:谷歌须占最强位“谷歌刚把免费版 Gemini API 的每日请求次数从 250 降到了 20,我的 n8n 自动化脚本现在基本都用不了了。这对任何开发小型项目的人来说都是个打击。”网友 Nilvarcus 表示。近日,有网友曝出 Google 收紧了 Gemini API 免费层级的限制:Pro 系列已经取消,Flash 系列每天仅 20 次。这对开发者来说远远不够用。
来自主题: AI资讯
8906 点击 2025-12-09 12:17