
为Token付费是一件很愚蠢的事情,用户应该为智能付费丨RockAI刘凡平@MEET2026
为Token付费是一件很愚蠢的事情,用户应该为智能付费丨RockAI刘凡平@MEET2026“人工智能要发展到下一个台阶,一定要突破两座大山。第一座大山是Transformer,第二座大山是反向传播算法。”在大模型规模不断拔高、算力与数据卷到极致的当下,RockAI创始人刘凡平提出了一个与主流共识截然不同的判断。
来自主题: AI资讯
8928 点击 2025-12-14 10:47
 搜索
搜索
“人工智能要发展到下一个台阶,一定要突破两座大山。第一座大山是Transformer,第二座大山是反向传播算法。”在大模型规模不断拔高、算力与数据卷到极致的当下,RockAI创始人刘凡平提出了一个与主流共识截然不同的判断。

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。
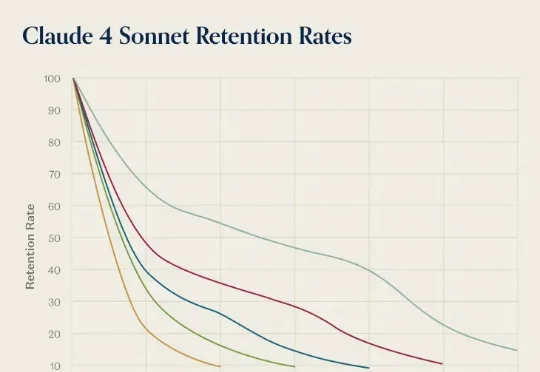
前几天,AI 推理服务供应商 OpenRouter 发布了一份报告《State of AI》,基于平台上 60 多家提供商的 300 多个模型,100 万亿个 token 的交互数据,对 LLM 的实际应用情况进行了分析。报告中,提到了一个「灰姑娘水晶鞋效应」,特别有意思。研究者在分析用户留用数据时发现一个现象:AI 模型发布第一个月进来的用户,往往比后来进来的用户留存率更高。

实现通用机器人的类人灵巧操作能力,是机器人学领域长期以来的核心挑战之一。近年来,视觉 - 语言 - 动作 (Vision-Language-Action,VLA) 模型在机器人技能学习方面展现出显著潜力,但其发展受制于一个根本性瓶颈:高质量操作数据的获取。
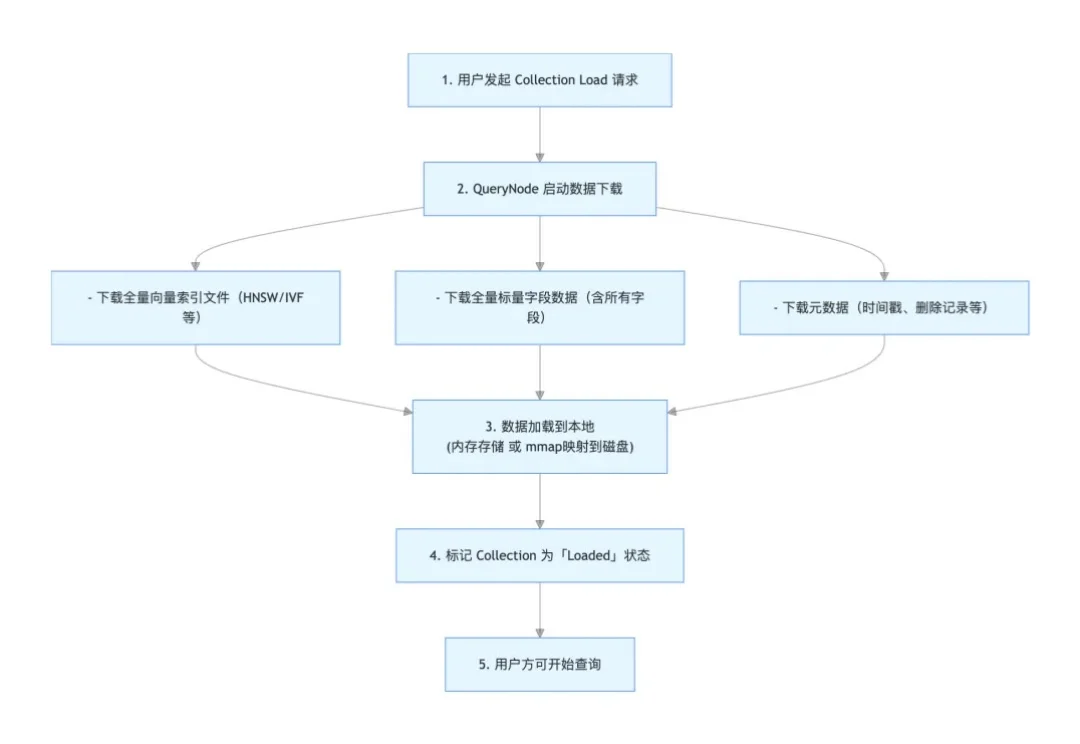
本文为Milvus Week系列第7篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。

灵初智能发布全球首个具身原生人类数据采集方案 Psi-SynEngine。该方案由灵初智能全栈自研,包含便携式外骨骼触觉手套数采套装、大规模 in the wild 数采数据管线、基于世界模型和强化学习的跨本体数据迁移模型,并已率先将采集到的人类数据应用于物流等真实场景。
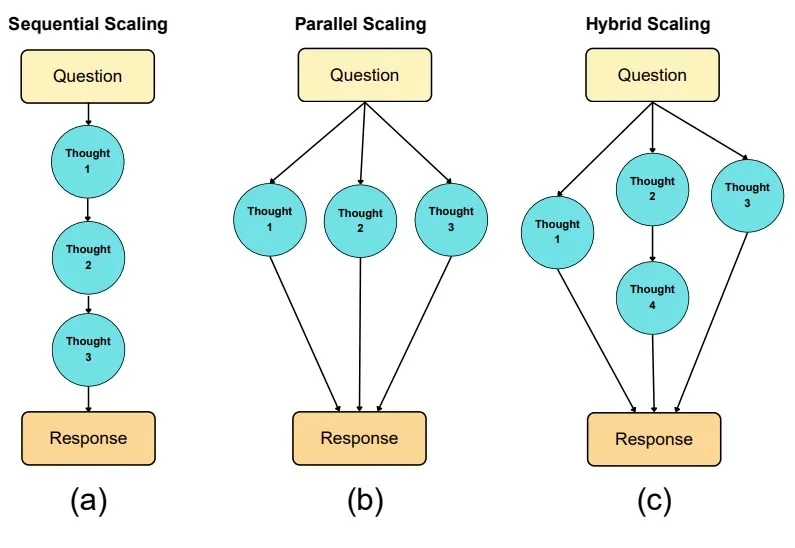
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。
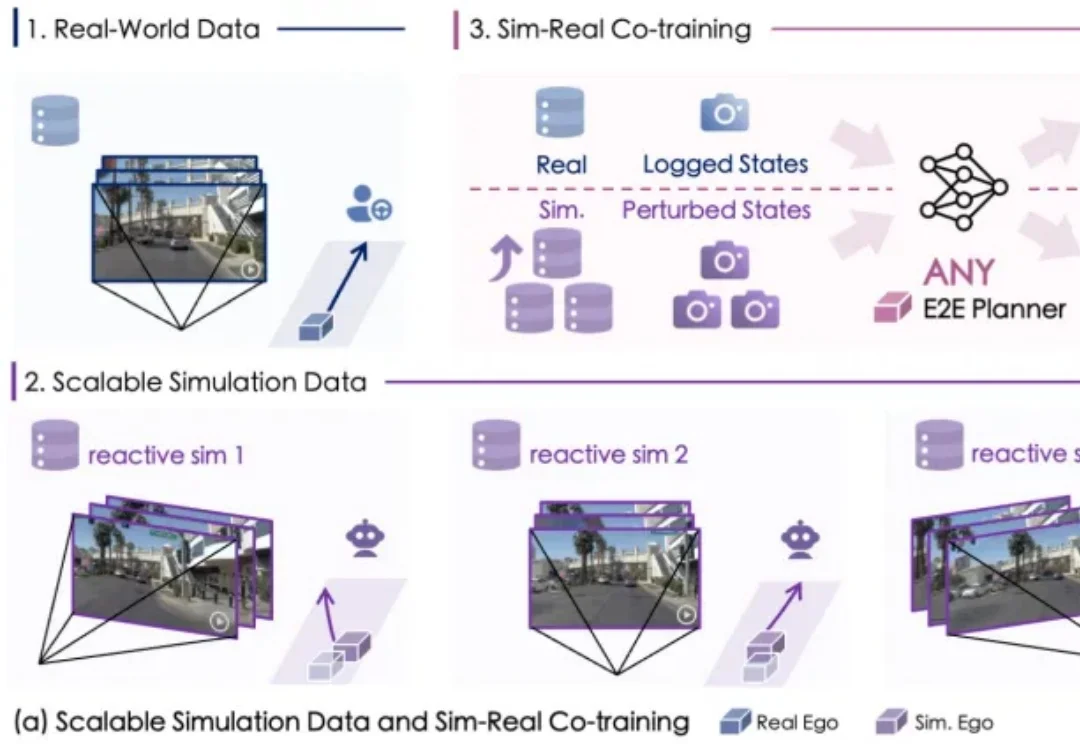
自动驾驶数据荒怎么破?

最终能把机器人做成功的,还是机器人行业内的人。
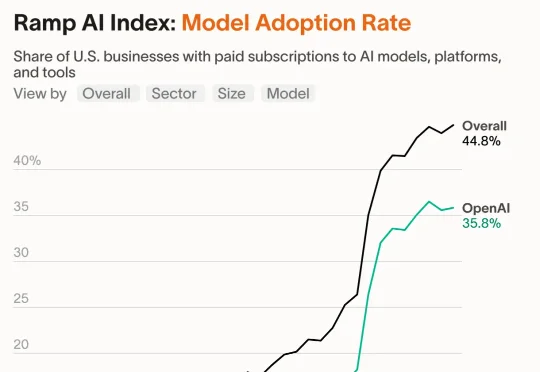
当你还在纠结要不要用一下AI时,OpenAI已经拎着8亿人的加班数据,在被谷歌和Anthropic逼到墙角的企业战场上拼命自救——到底是谁在每天白赚1小时,谁又在被时代悄悄淘汰?