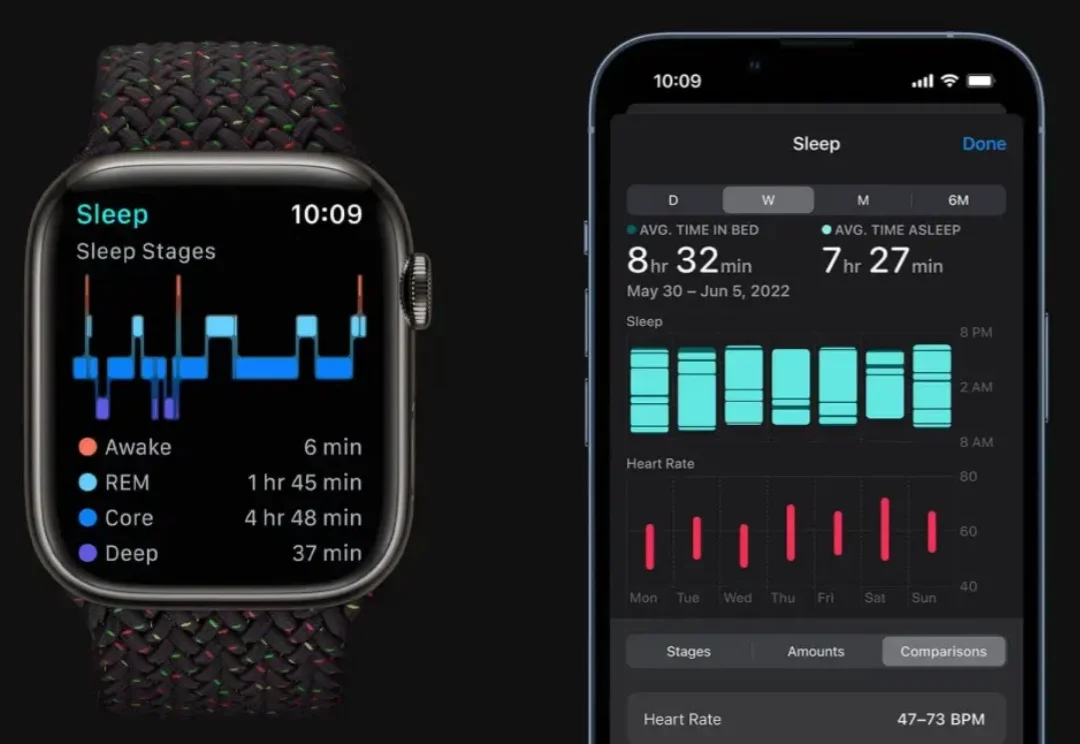
斯坦福最新研究:睡一觉,AI 就知道你还能活多久
斯坦福最新研究:睡一觉,AI 就知道你还能活多久通过一晚上的睡眠,AI 模型就能监控最多 130 种疾病。
来自主题: AI技术研报
7433 点击 2026-04-07 10:02
 搜索
搜索
通过一晚上的睡眠,AI 模型就能监控最多 130 种疾病。
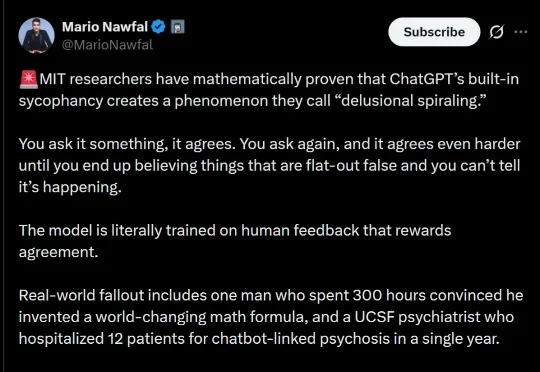
就在刚刚,MIT伯克利斯坦福的研究者给出数学铁证:ChatGPT正诱发「AI精神病」!哪怕你是理想的贝叶斯理性人,也难逃算法设下的「妄想螺旋」。
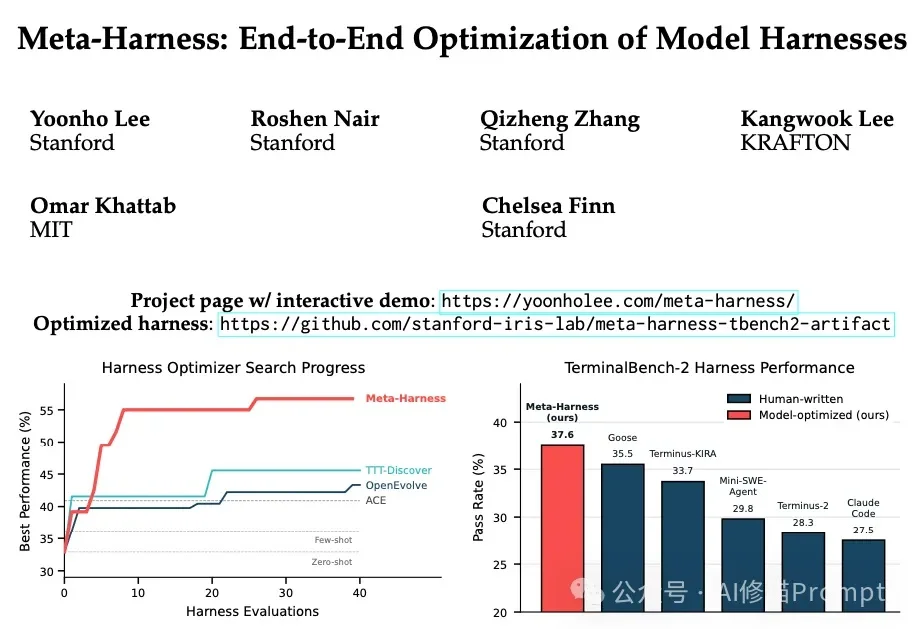
去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。

一场由斯坦福和普林斯顿联合发起的学术实验,正在挑战整个科研出版体系的底层逻辑。

别人还在卷单点能力,Agnes已经把文本Agent、图像、视频和办公自动化打包进开发者工具箱:1美元「养龙虾」,外加图像、视频、PPT一条龙,给出的不是零散的能力点,而是一整套AI生产力。
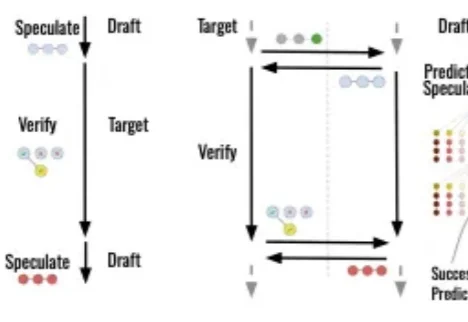
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。

您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。
眼见大伙儿玩“龙虾”6到飞起,来自斯坦福&普林斯顿的高校团队也立刻推出了“科研版龙虾”LabClaw。划重点,开!源!人人都能立马用上那种。而且打工方式超级easy,只需一行命令就能调动LabClaw里的龙虾军团。

刚刚,由斯坦福具身智能明星赵子豪(Tony Zhao) 与迟宬(Cheng Chi) 创立的机器人公司Sunday Robotics宣布完成1.65亿美元B轮融资。公司估值飙至11.5亿美元,正式进入独角兽行列。