
断供OpenAI!Anthropic收购SDK工具公司Stainless
断供OpenAI!Anthropic收购SDK工具公司Stainless刚刚,Anthropic买下了SDK工具公司Stainless,从开源MCP到收购Stainless,Anthropic的智能体棋盘已集齐模型、接口、连接三件套。
来自主题: AI资讯
8031 点击 2026-05-21 21:20
 搜索
搜索
刚刚,Anthropic买下了SDK工具公司Stainless,从开源MCP到收购Stainless,Anthropic的智能体棋盘已集齐模型、接口、连接三件套。
大多数开发者刚接触代码编辑类的 AI 智能体 (AI Agent) 时,通常只让它们干一件事:写代码。比如让它检查一下代码库,生成个差异对比 (diff),跑跑测试,然后再提个合并请求 (pull request)。
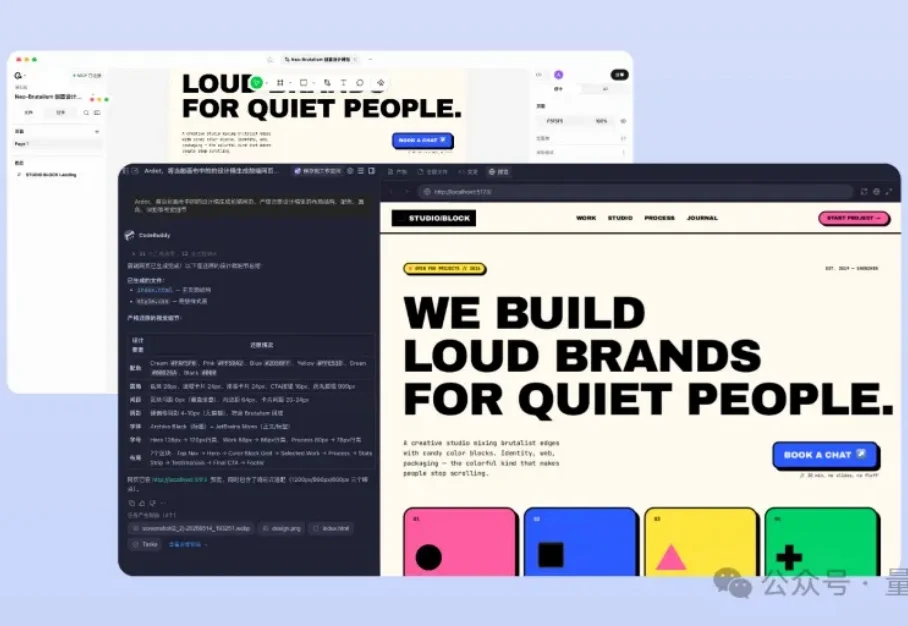
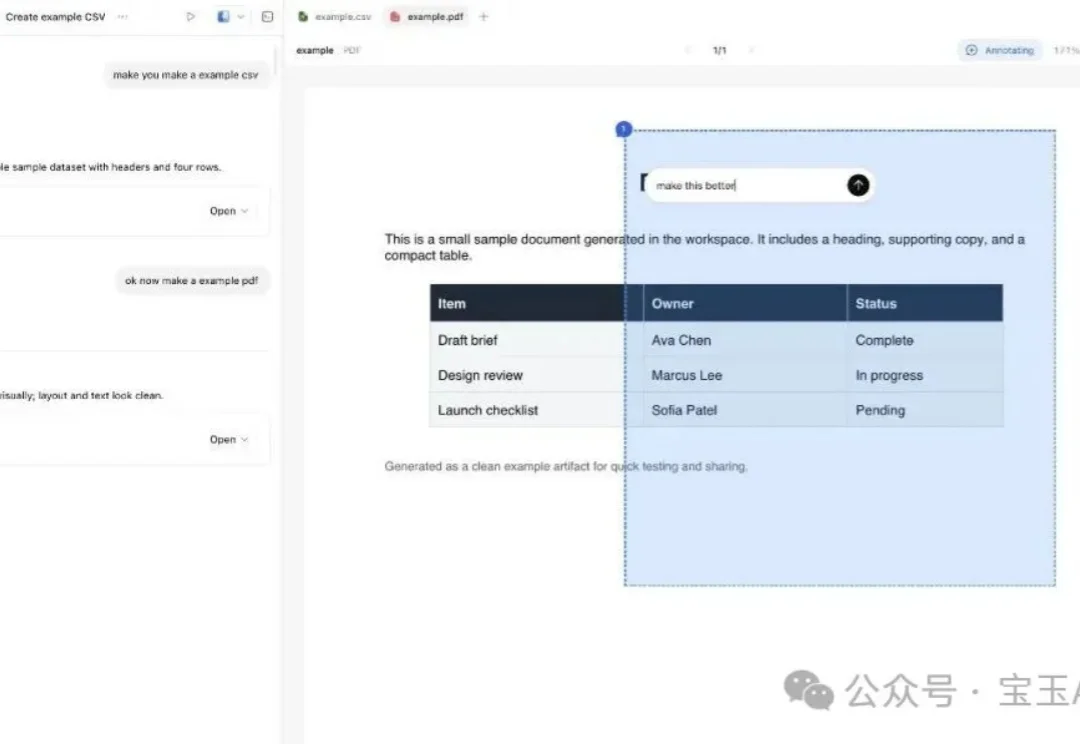
Claude Design前脚刚把设计圈炸完,腾讯又公测了一个Ardot—— AI设计智能体平台,一句话生成可编辑UI设计稿、Figma文件零成本导入、一键转代码直通IDE、多人在线评审……
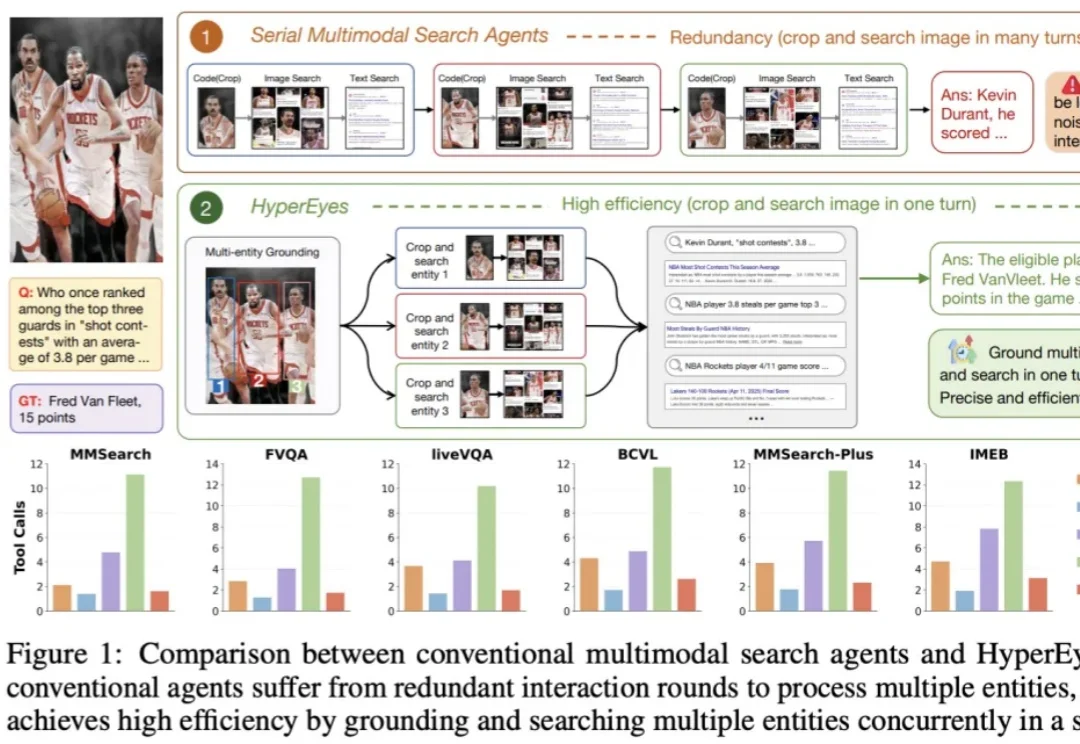
现有的开源多模态搜索智能体普遍受困于「裁剪 - 再搜索」的串行处理模式,面对多目标时往往陷入交互冗长、错误级联累积的泥沼。

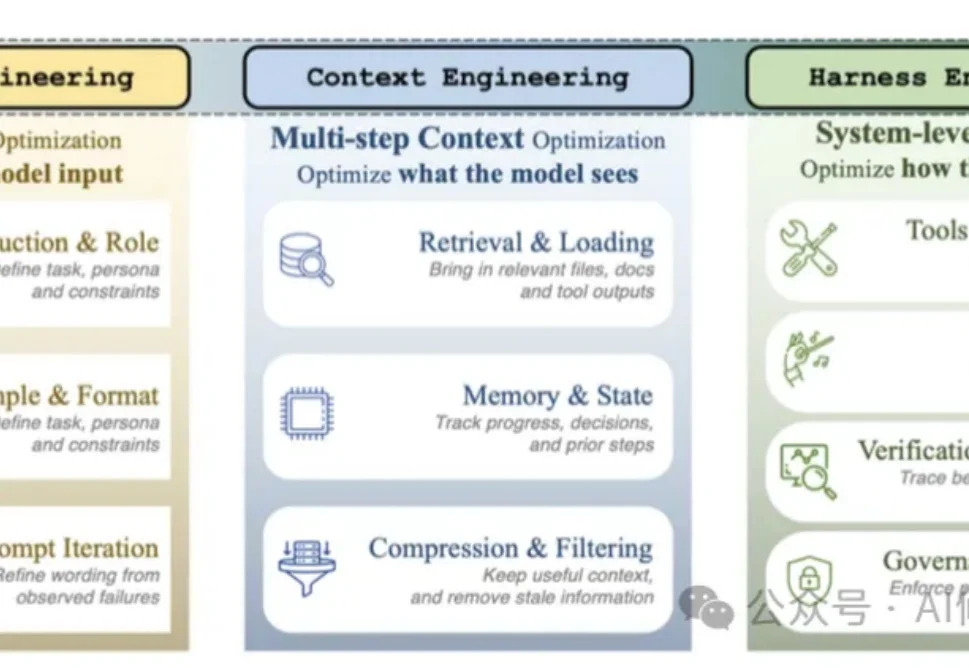
你是否在使用Agent工作或者写代码时,总感觉上下文不够用?或者感觉反复使用Agent时并没有变得更聪明?感觉目前的记忆方案仍然不够用?今日,香港中文大学联合浙江大学发布的一篇论文关注了这个问题,并引起了学术界广泛讨论:你以为Agent在「记忆」,其实只是在记备忘录。
经常切换使用CC、Codex、OpenClaw这类Agent的人会发现:同一个模型,放进不同系统里,表现可能完全不同。

全行业都在押注多Agent。
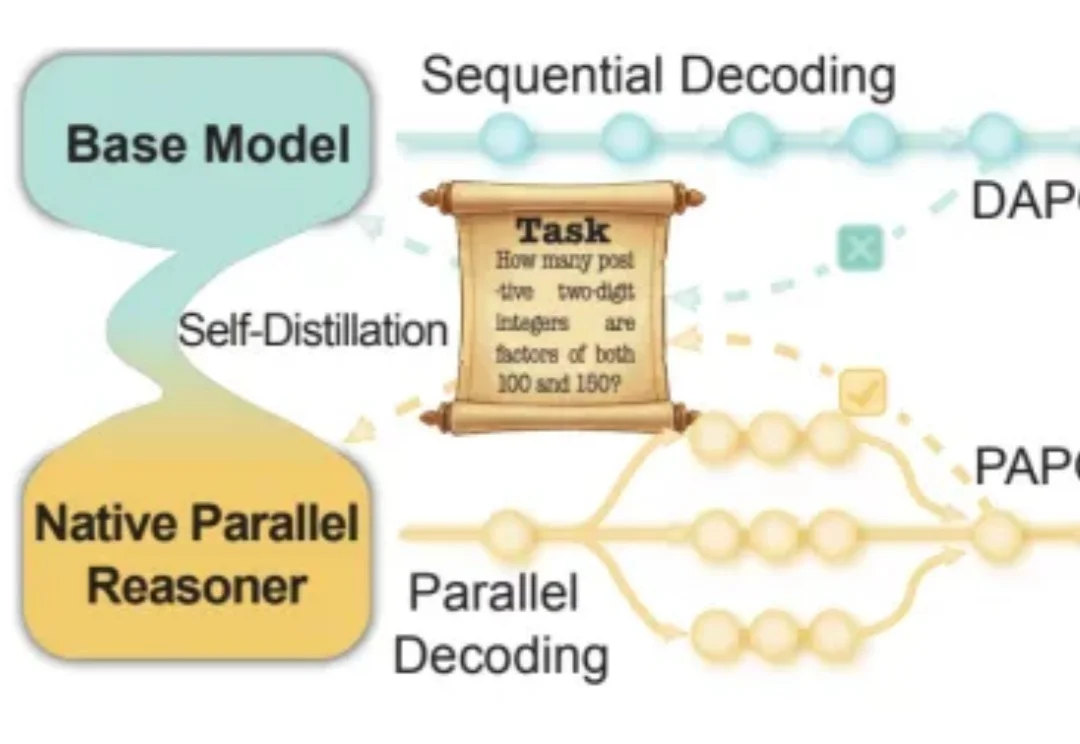
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。
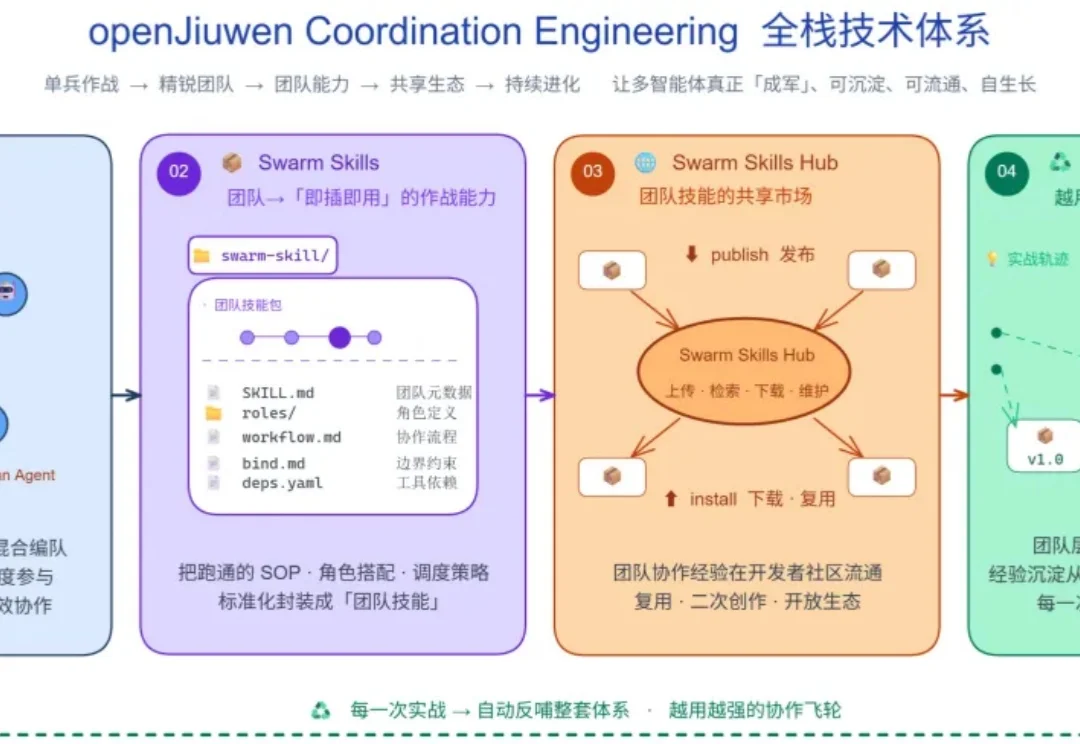
刚刚,华为支持的开源 AI Agent 平台社区 openJiuwen 发布并开源了蜂群智能体 JiuwenSwarm。

20美元Token费,2小时运行,AI智能体没问任何人,自主翻遍互联网,选中麦肯锡,把它的「数字大脑」Lilli彻底攻破。4650万条战略聊天记录、72万份核心文件、95条系统提示词……全部明文读写权限到手。AI震惊地说出了「WOW!」