
谷歌AI攻克6道世界级难题,比IMO金牌更震撼!陶哲轩指明新玩法
谷歌AI攻克6道世界级难题,比IMO金牌更震撼!陶哲轩指明新玩法Google DeepMind最新AI智能体Aletheia在FirstProof挑战赛中,独立攻克了6道世界级数学难题,实现了从竞赛水平到PhD科研级的质变。人类数学研究的「手工时代」或许正步入倒计时。
来自主题: AI资讯
9394 点击 2026-03-01 11:28
 搜索
搜索
Google DeepMind最新AI智能体Aletheia在FirstProof挑战赛中,独立攻克了6道世界级数学难题,实现了从竞赛水平到PhD科研级的质变。人类数学研究的「手工时代」或许正步入倒计时。
Perplexity发推表示,推出新产品Perplexity Computer,一个基于浏览器的、全能型通用数字员工。按照官方的说法,它能推理、委派、搜索、构建、记忆、编码、交付,部署项目、设计文件、研究课题、管理工作流程……

2024年农历新年前一周,深圳南山区一个出租屋里,徐雨豪和吴显昆等Kuse核心成员围站在一块白板前,从芯片聊到客户服务,从技术壁垒聊到大厂动向。窗外这座城市正在快速空下来,人们拎着年货涌向火车站和机场,而他们已经在小屋里闭关了整整7天。
近期,多家国内模型厂商先后推出对标 OpenClaw 的产品,Mini Max 推出的 MaxClaw,Kimi 推出的 Kimi Claw,显然,OpenClaw 所展现出的 AI 执行力,以及开发者们对 AI 执行结果所展现出来的包容程度让市场看到了价值空间。

可自主规划连续执行40天的全自动智能体来了! Factory最新上线的Missions,直接超越OpenClaw,把一盘剥好的肉端上桌——不整虚的!只需一个任务指令,就能交付全自动工程闭环。
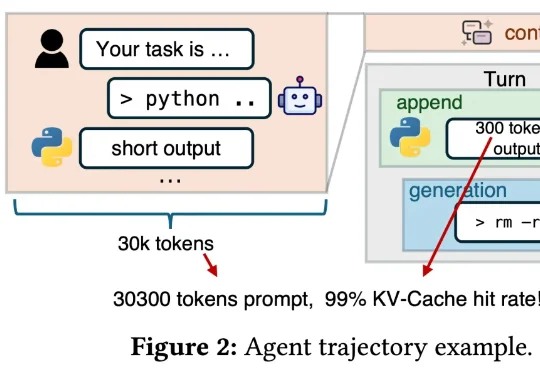
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。

基于Gemini 3 Deep Think的谷歌数学智能体Aletheia在更难的挑战赛FirstProof中拿下的最佳成绩。在公布的完整成绩单中,10道题Aletheia全程0人工参与解出6道,其中5题专家全票通过,还有一题拿到了5/7的通过率。
原本以为,三星 Galaxy S26 系列早已被曝光,发布会也就走个流程。没想到三星和 Google 还藏了一手。 两家公司共同展示了 S26 搭载的全新 Gemini 智能体能力:口头吩咐一句话,G
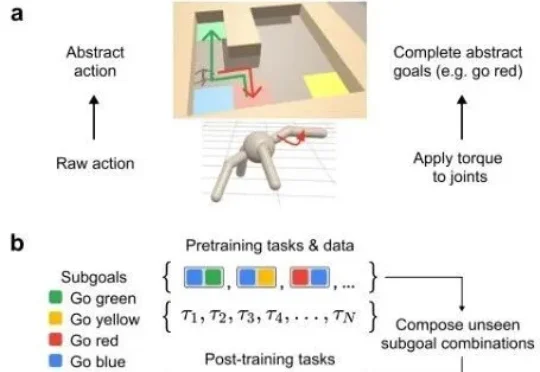
传统AI模型在稀疏奖励环境中,往往会找不到激励难以学会层次化思考。如今,谷歌团队通过引入元控制器操控模型内部残差流,让智能体学会了「跳跃式思考」。该研究揭示了大模型内部可自发形成了类似人脑的层次化决策机制,为AI在需要多步的复杂任务提供了全新的训练范式。
Anthropic 周三宣布已收购 Vercept,这家 AI 初创公司团队核心成员与西雅图科技界的多家知名企业渊源深厚。此次收购是继去年 12 月 Anthropic 收购编程智能体引擎 Bun 以推动 Claude Code 规模化发展之后的最新动作。