
刚刚,Gemini攻克「宇宙弦」终极难题!AI科学家最优雅解法震撼物理学
刚刚,Gemini攻克「宇宙弦」终极难题!AI科学家最优雅解法震撼物理学就在刚刚,Google Research团队用Gemini Deep Think + 树搜索框架,独立攻克了一个理论物理领域的未解积分难题——宇宙弦引力辐射功率谱的精确解析解。AI探索了600条候选路径,找出6种解法,最优雅的那条,让人类物理学家都拍案叫绝。
来自主题: AI资讯
10342 点击 2026-03-07 15:30
 搜索
搜索
就在刚刚,Google Research团队用Gemini Deep Think + 树搜索框架,独立攻克了一个理论物理领域的未解积分难题——宇宙弦引力辐射功率谱的精确解析解。AI探索了600条候选路径,找出6种解法,最优雅的那条,让人类物理学家都拍案叫绝。

只要科学任务可以评分,AI就能找到超越人类专家的方法,实现SOTA结果? 这是谷歌一篇最新论文里的内容: 使用大模型+树搜索,让AI大海捞针就行。

大模型在科研领域越来越高效了。
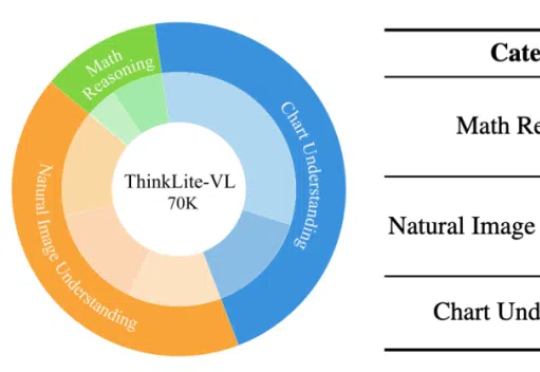
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
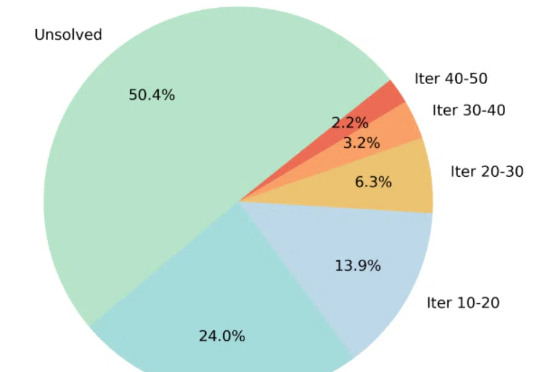
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
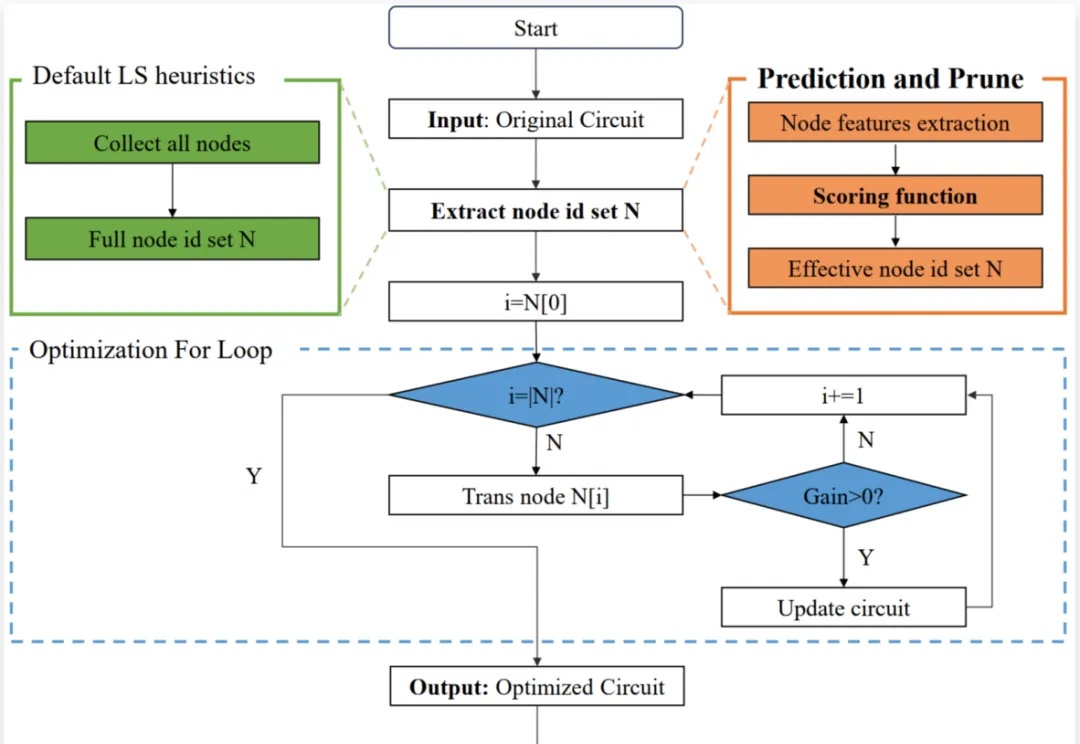
芯片设计是现代科技的核心,逻辑优化(Logic Optimization, LO)作为芯片设计流程中的关键环节,其效率直接影响着芯片设计的整体性能。
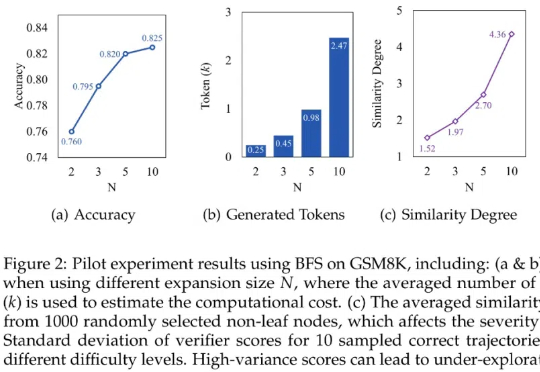
本文探讨基于树搜索的大语言模型推理过程中存在的「过思考」与「欠思考」问题,并提出高效树搜索框架——Fetch。本研究由腾讯 AI Lab 与厦门大学、苏州大学研究团队合作完成。

把扩散模型的生成能力与 MCTS 的自适应搜索能力相结合,会是什么结果?
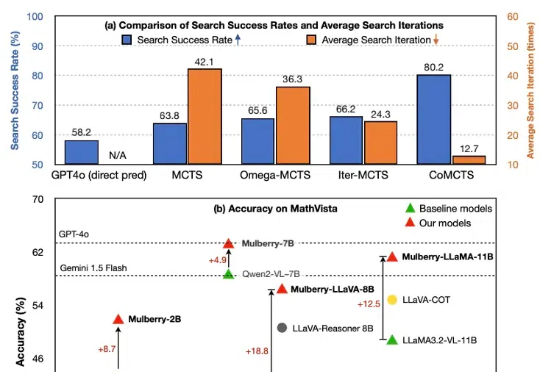
尽管多模态大语言模型(MLLM)在简单任务上最近取得了显著进展,但在复杂推理任务中表现仍然不佳。费曼的格言可能是这种现象的完美隐喻:只有掌握推理过程的每一步,才能真正解决问题。然而,当前的 MLLM 更擅长直接生成简短的最终答案,缺乏中间推理能力。本篇文章旨在开发一种通过学习创造推理过程中每个中间步骤直至最终答案的 MLLM,以实现问题的深入理解与解决。
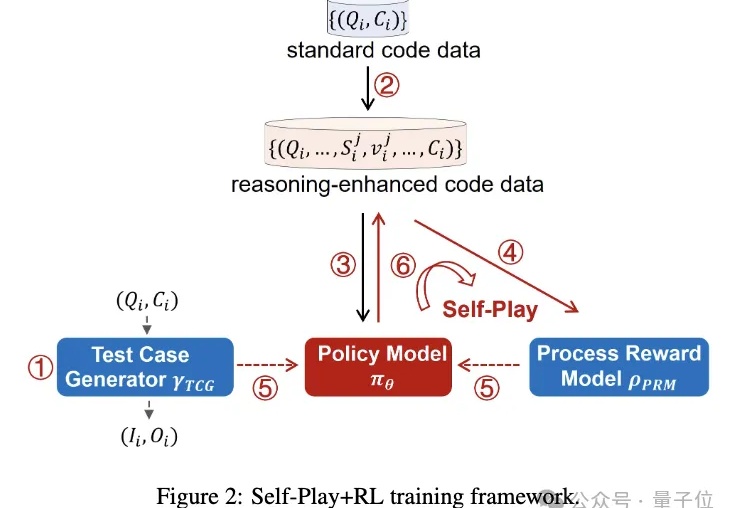
北京交通大学研究团队悄默声推出了一版o1,而且所有源代码、精选数据集以及衍生模型都开源!