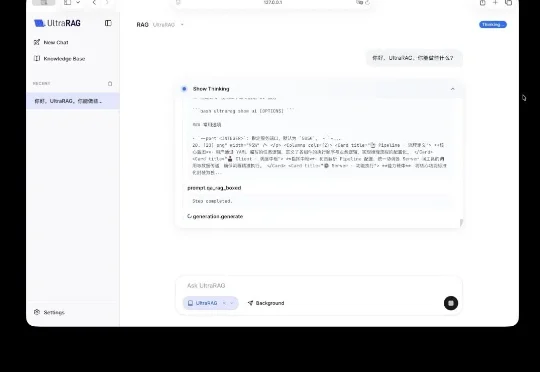
UltraRAG 3.0 发布:拒绝“盲盒”开发,让每一行推理逻辑都清晰可见
UltraRAG 3.0 发布:拒绝“盲盒”开发,让每一行推理逻辑都清晰可见今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:
来自主题: AI资讯
11707 点击 2026-01-24 15:14
 搜索
搜索
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:

GEM框架利用认知科学原理,从少量人类偏好中提取多维认知评估,让AI在极少标注下精准理解人类思维,提高了数据效率,在医疗等专业领域表现优异,为AI与人类偏好对齐提供新思路。

现有AI记忆评测存在局限,如数据源单一、忽视变化本质、注入成本高等。CloneMem通过层次化生成框架构建合成人生,设计贴近真实场景的评测任务,涵盖多种问题类型。

中国团队首次在全球顶尖期刊发表“大模型+医疗”领域的相关标准研究! 作为Nature体系中专注于数字医疗的旗舰期刊,《npj Digital Medicine》(JCR影响因子15.1,中科院医学大类1区Top期刊)此次收录的CSEDB研究,首次提出了一套用于评估医疗大模型真实临床能力的系统性框架。

华东师范大学Planing Lab提出APEX框架,通过自然语言指令实现学术海报的局部可控编辑,并引入「审查—调整」机制提升编辑可靠性。
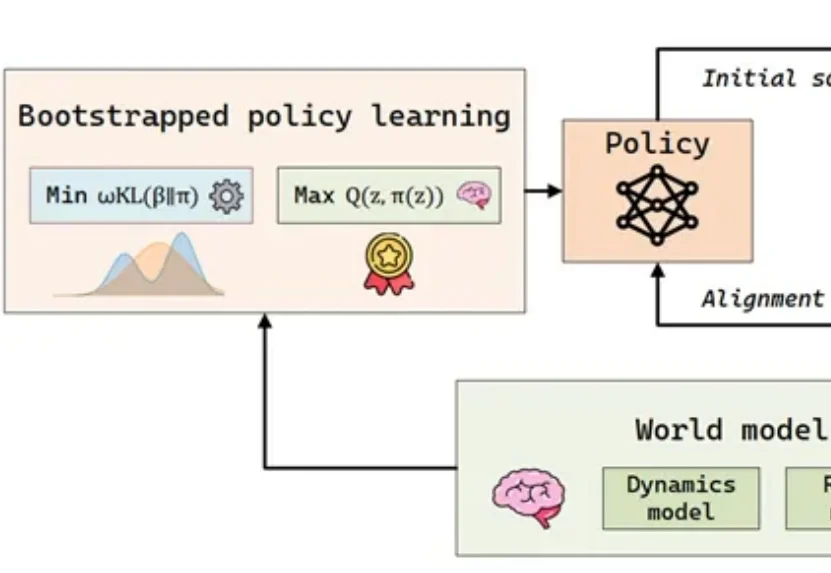
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
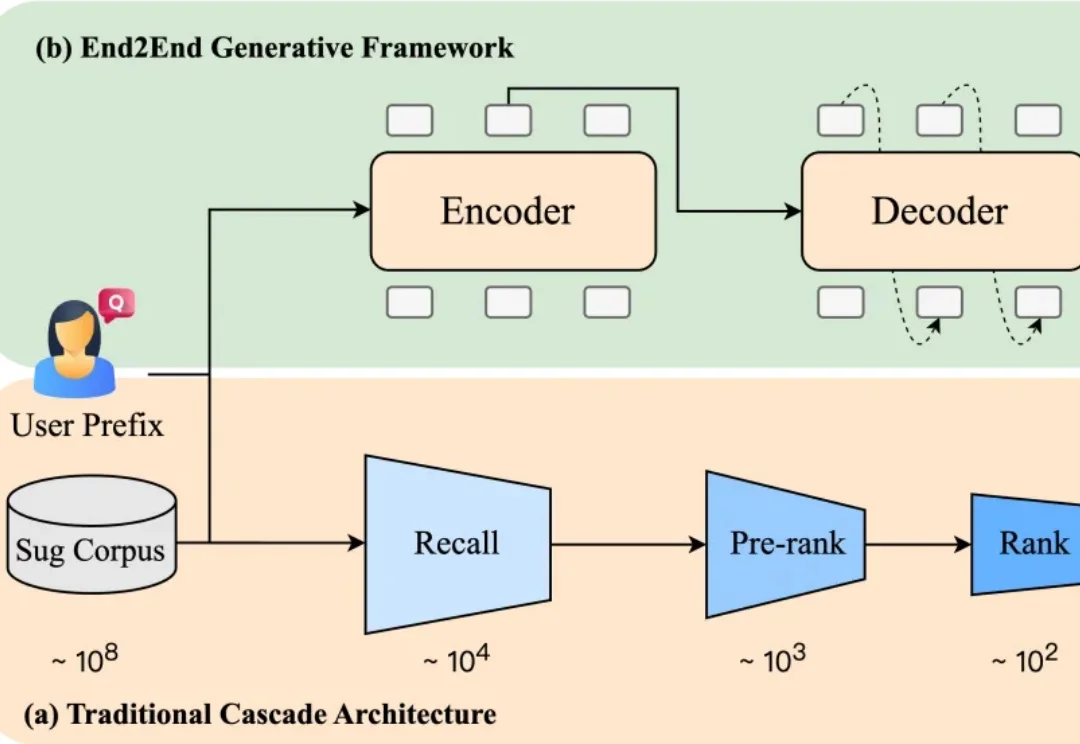
当你在电商平台搜索“苹果”,系统会推荐“水果”还是“手机”?或者直接跳到某个品牌旗舰店?短短一个词,背后承载了完全不同的购买意图。而推荐是否精准,直接影响用户的搜索体验,也影响平台的转化效率。
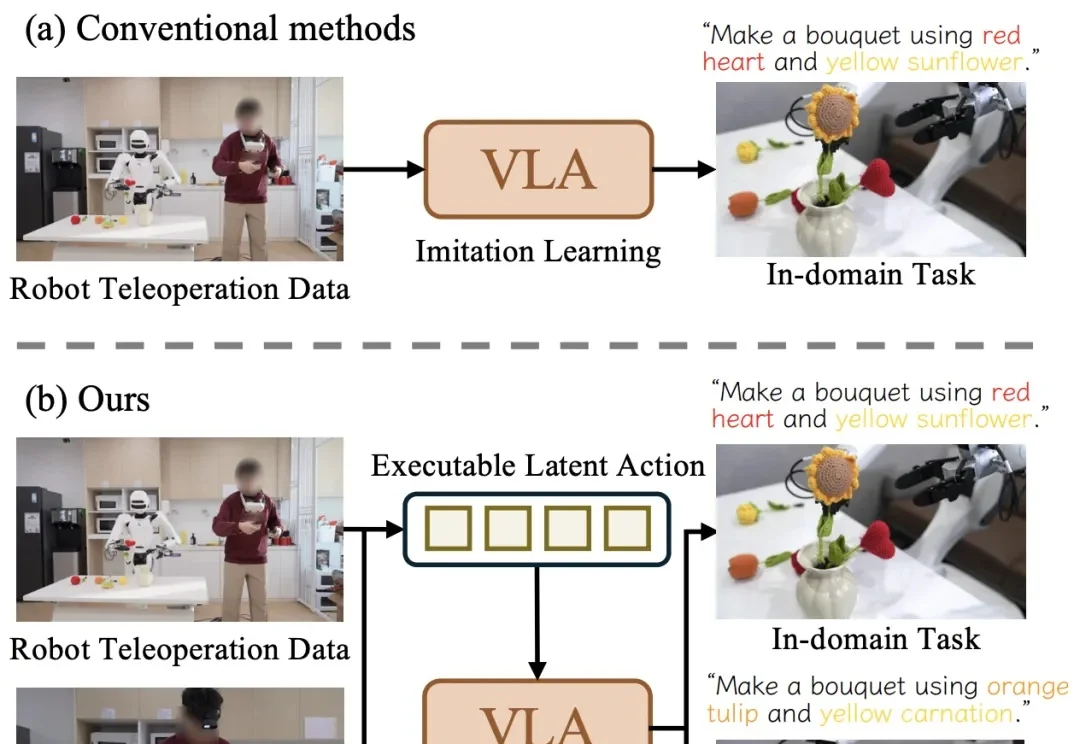
近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!
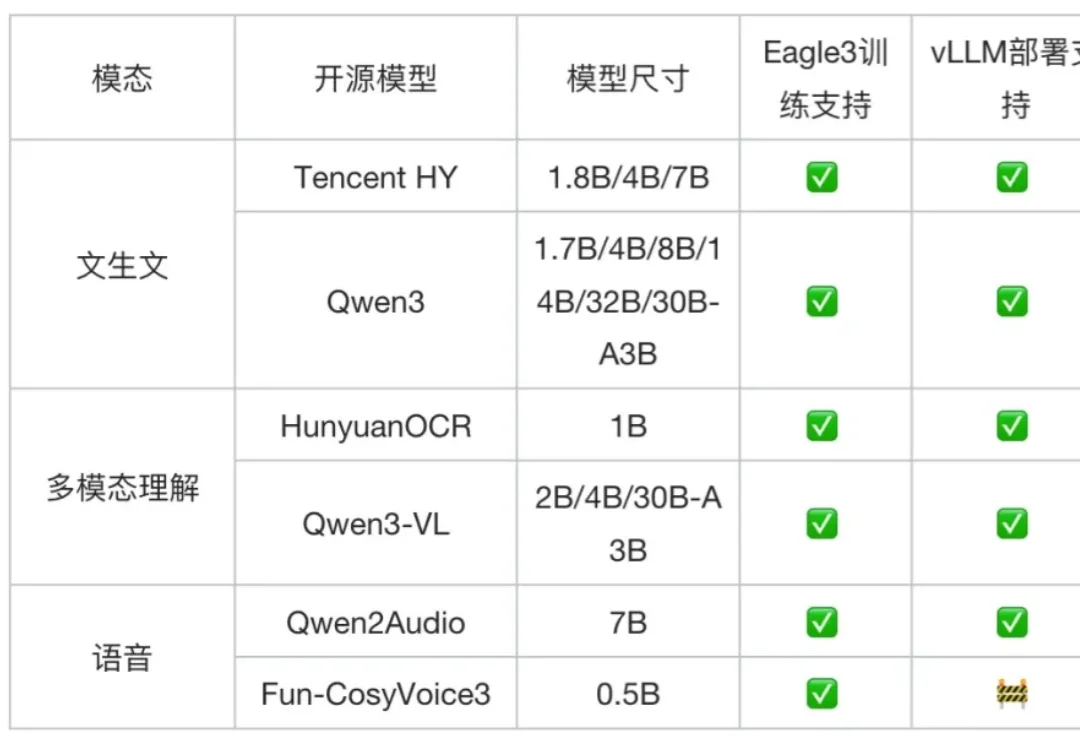
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。

香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。