
GPT-5.2改写粒子物理教科书!人类手算32项算不出,AI一行公式搞定
GPT-5.2改写粒子物理教科书!人类手算32项算不出,AI一行公式搞定粒子物理教科书几十年的结论被推翻,GPT-5.2干的。这已经是GPT-5.2在基础科学领域做出原创贡献的第三个公开案例。 此前GPT-5独立证明了一道存在45年的埃尔德什数论猜想,还在非线性量子力学与相对论兼容性的理论物理论文中提出了核心方法论框架。
来自主题: AI资讯
9097 点击 2026-02-15 16:55
 搜索
搜索
粒子物理教科书几十年的结论被推翻,GPT-5.2干的。这已经是GPT-5.2在基础科学领域做出原创贡献的第三个公开案例。 此前GPT-5独立证明了一道存在45年的埃尔德什数论猜想,还在非线性量子力学与相对论兼容性的理论物理论文中提出了核心方法论框架。
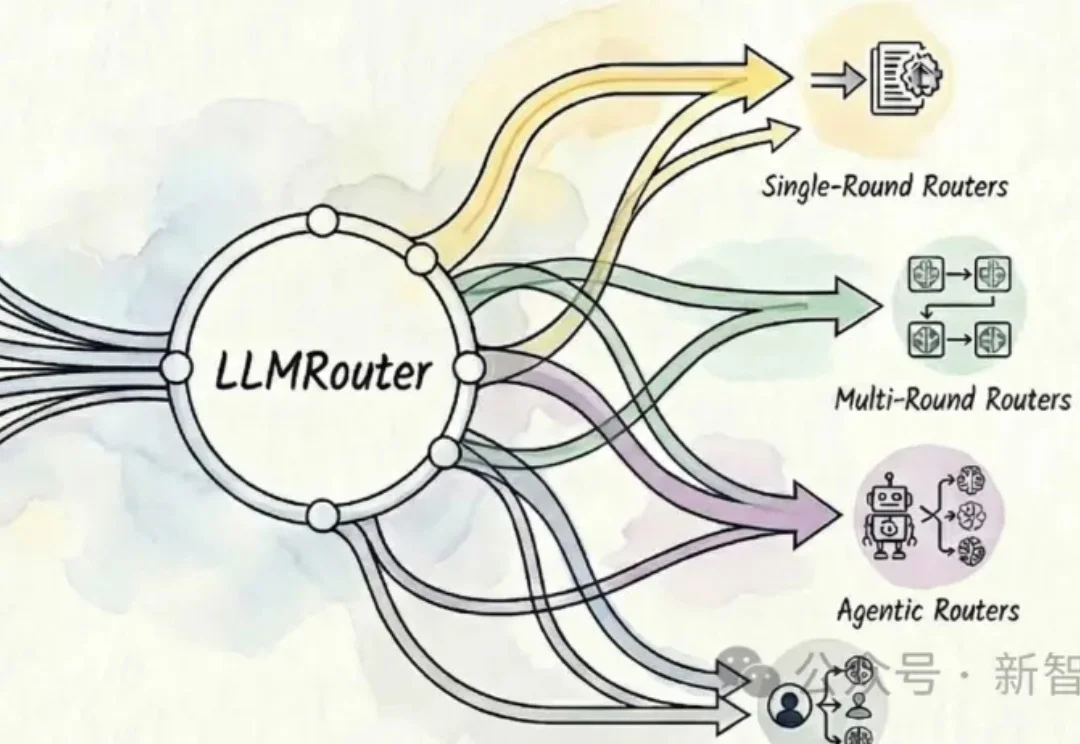
UIUC开源的智能模型路由框架LLMRouter可以自动为大模型应用选择最优模型,提供16+路由策略,覆盖单轮选择、多轮协作、个性化偏好和Agent式流程,在性能、成本与延迟间灵活权衡。
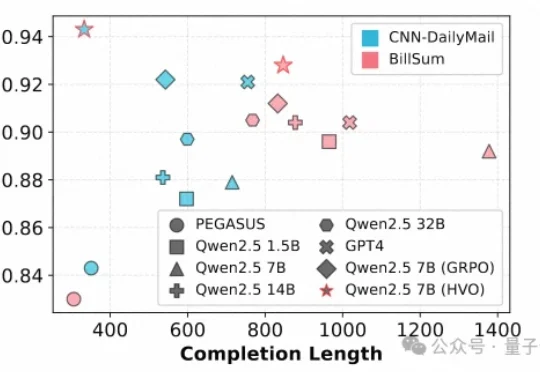
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。

大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。
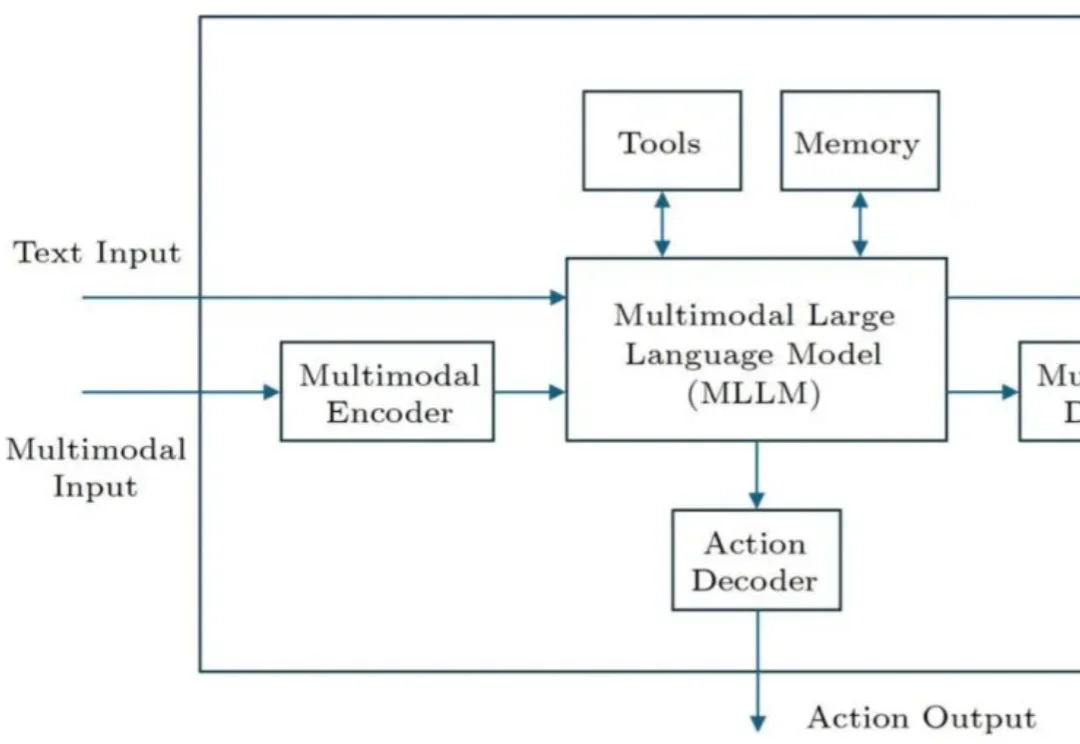
AI 智能体是人工智能领域的重要研究方向之一。近期,字节跳动的李航博士在我国计算机科学领域顶级期刊 Journal of Computer Science and Technology(JCST)上发表了一篇题为《General Framework of AI Agents》的观点论文(将收录于 JCST 创刊 40 周年专辑),提出了一个涵盖软件智能体和硬件智能体的通用框架。
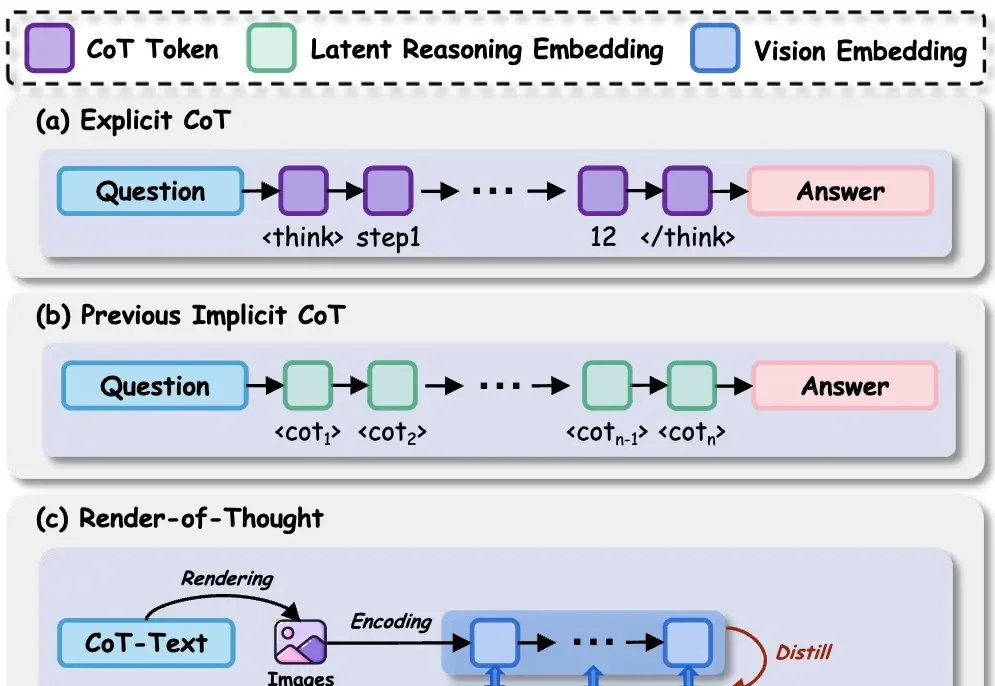
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。

这一框架可用于集成额外文本、语音和视觉等多种模态。
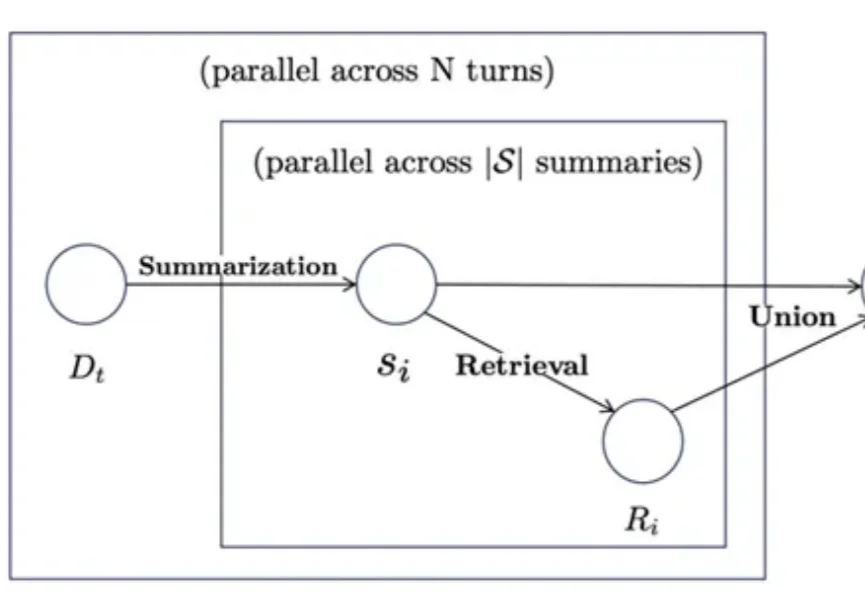
思维导图曾被证明可以帮助学习障碍者快速提升成绩,那么当前已经可堪一用的智能体系统如果引入类似工具是否可以帮助改善长期学习记忆能力呢?有研究团队做出了探索性尝试。
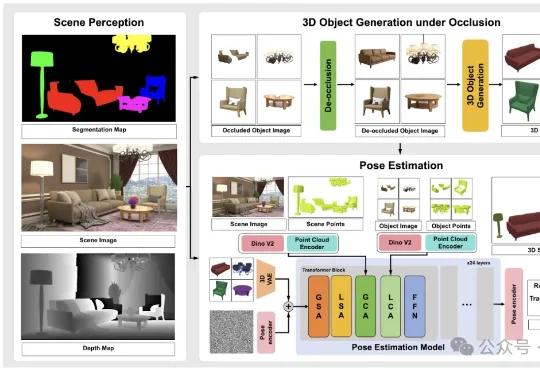
IDEA研究院张磊团队与香港科技大学谭平团队联合推出SceneMaker框架,有望攻克这一问题。 它以视启未来的万物检测模型DINO-X与光影焕像的万物3D生成模型Triverse为基础,实现了从任意开放世界图像(室内/室外/合成图等)到带Mesh的3D场景的完整重建。
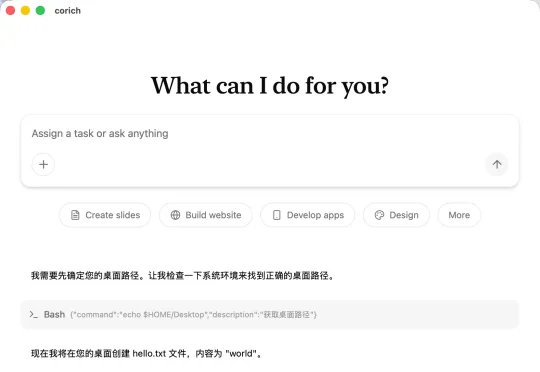
复盘一下我vibe coding 一周,开发 WorkAny 的过程,很有意思。 1. 上周三在香港办卡,临时起意想做个桌面 Agent 项目,对标 cowork,晚上回到广州开始写代码 2. 初期目标是快速发布,没时间去研究哪个 Agent 框架好用了,看很多人在用 claude agent sdk,先用这个吧