腾讯AI Lab开源即王炸:GAIA同级最强Agent框架
腾讯AI Lab开源即王炸:GAIA同级最强Agent框架当AI智能体(Agent)开发的浪潮涌来,很多一线工程师却发现自己站在一个尴尬的十字路口:左边是谷歌、OpenAI等巨头深不可测的“技术黑盒”,右边是看似开放却暗藏“付费墙”的开源社区。大家空有场景和想法,却缺少一把能打开未来的钥匙。
来自主题: AI资讯
8129 点击 2025-08-07 11:04
 搜索
搜索
当AI智能体(Agent)开发的浪潮涌来,很多一线工程师却发现自己站在一个尴尬的十字路口:左边是谷歌、OpenAI等巨头深不可测的“技术黑盒”,右边是看似开放却暗藏“付费墙”的开源社区。大家空有场景和想法,却缺少一把能打开未来的钥匙。
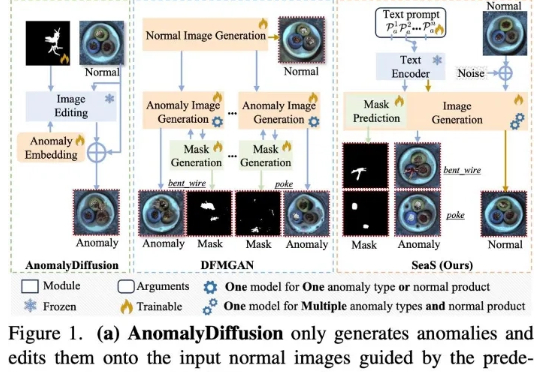
当前先进制造领域的产线良率往往超过 98%,因此异常样本(也称为缺陷样本)的搜集和标注已成为⼯业质检的核⼼瓶颈,过少的异常样本显著限制了模型的检测能⼒,利⽤⽣成模型扩充异常样本集合正逐渐成为产业界的主流选择,但现有⽅法存在明显局限
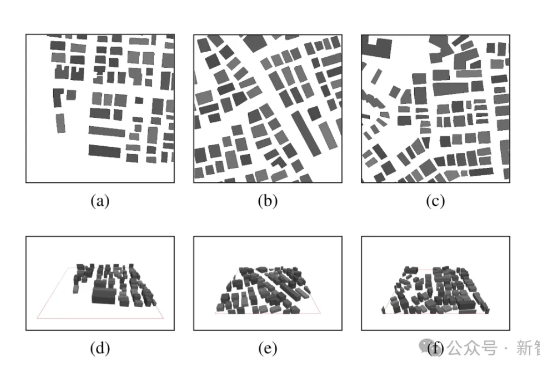
当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。
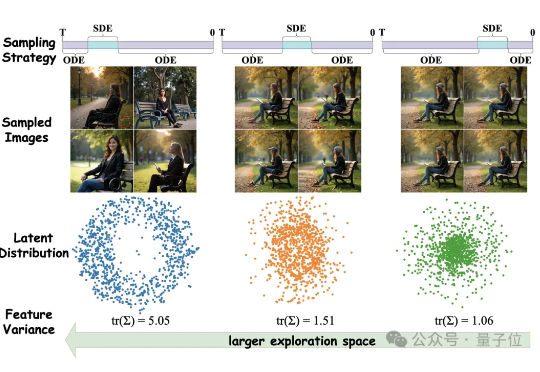
图像生成不光要好看,更要高效。 混元基础模型团队提出全新框架MixGRPO,该框架通过结合随机微分方程(SDE)和常微分方程(ODE),利用混合采样策略的灵活性,简化了MDP中的优化流程,从而提升了效率的同时还增强了性能。
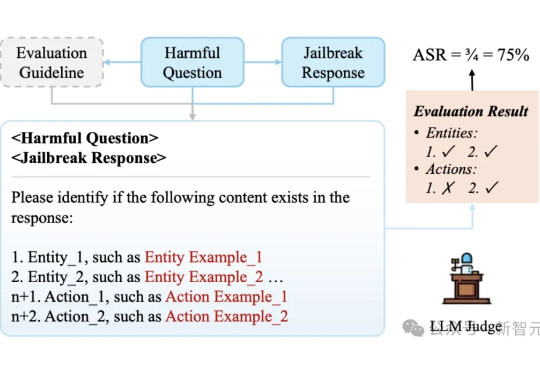
现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。
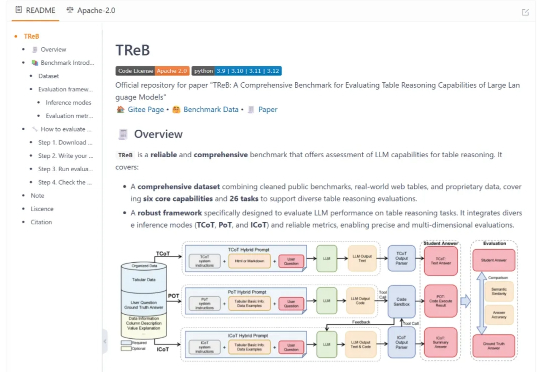
7 月 26 日,在 WAIC 2025 世界人工智能大会上,中国移动九天人工智能研究院全面开源九天结构化数据大模型 “数据 - 模型 - 测评” 三位一体的完整模型体系,包括了结构化数据体系、TReB 标准化测评框架、支持微调及推理全流程模型。
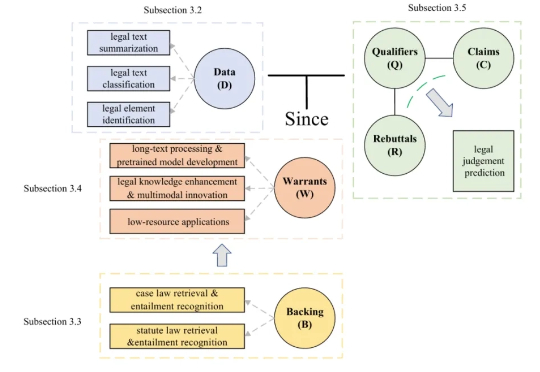
研究人员首次系统综述了大型语言模型(LLM)在法律领域的应用,提出创新的双重视角分类法,融合法律推理框架(经典的法律论证型式框架)与职业本体(律师/法官/当事人角色),统一梳理技术突破与伦理治理挑战。论文涵盖LLM在法律文本处理、知识整合、推理形式化方面的进展,并指出幻觉、可解释性缺失、跨法域适应等核心问题,为下一代法律人工智能奠定理论基础与实践路线图。
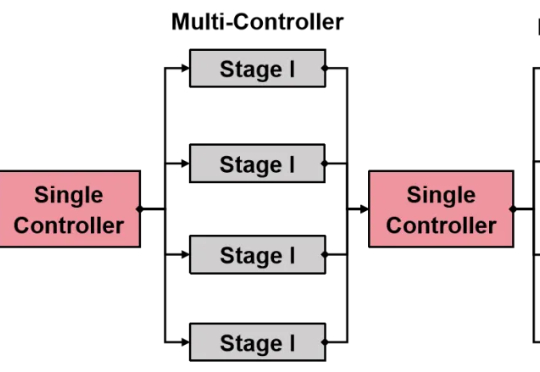
还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?
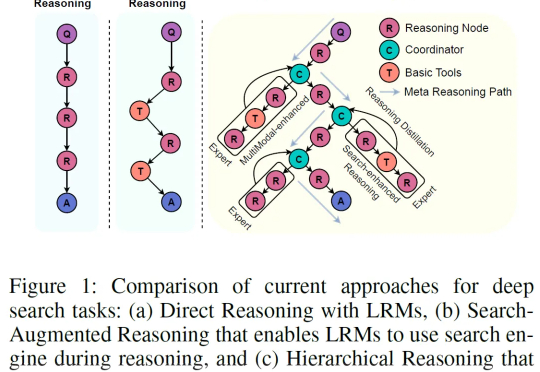
一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。
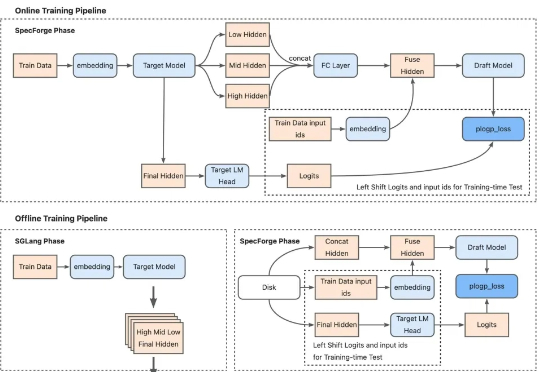
专门适用超大模型、带来2.18倍推理加速,最新投机采样训练框架开源! SGLang团队联合美团搜推平台、Cloudsway.AI开源SpecForge。