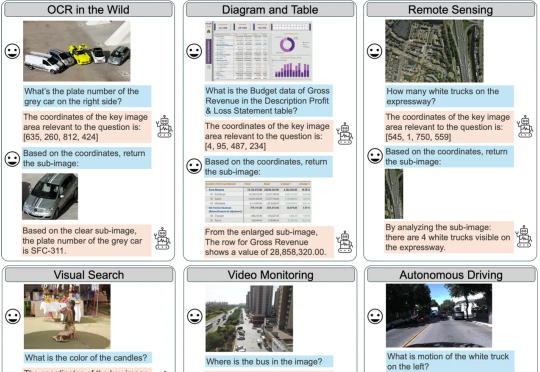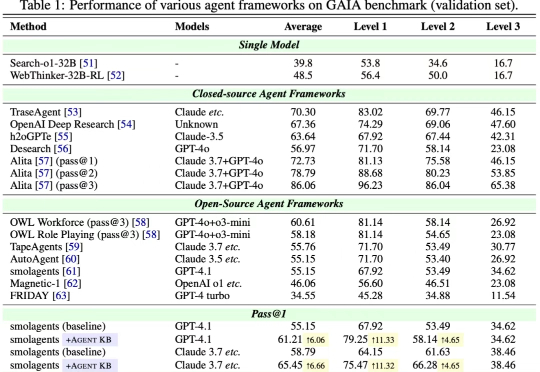
Agent KB:经验池让Agents互相学习!GAIA新开源SOTA,Pass@1性能最高提升6.66
Agent KB:经验池让Agents互相学习!GAIA新开源SOTA,Pass@1性能最高提升6.66近日,来自 OPPO、耶鲁大学、斯坦福大学、威斯康星大学麦迪逊分校、北卡罗来纳大学教堂山分校等多家机构的研究团队联合发布了 Agent KB 框架。这项工作通过构建一个经验池并且通过两阶段的检索机制实现了 AI Agent 之间的有效经验共享。Agent KB 通过层级化的经验检索,让智能体能够从其他任务的成功经验中学习,显著提升了复杂推理和问题解决能力。
来自主题: AI技术研报
9544 点击 2025-07-25 16:50