
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。
来自主题: AI技术研报
10455 点击 2025-07-11 10:09
 搜索
搜索
MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。

你有没有想过,为什么 Cursor、v0、Perplexity、Lovable、Bold 这些服务数百万用户的顶级 AI agent 产品,竟然都有一个惊人的共同点?它们全部都不是基于任何 AI 框架构建的。

LLM用得越久,速度越快!Emory大学提出SpeedupLLM框架,利用动态计算资源分配和记忆机制,使LLM在处理相似任务时推理成本降低56%,准确率提升,为AI模型发展提供新思路。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。
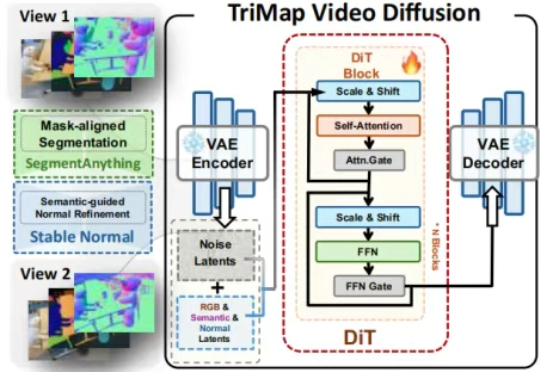
最少只用2张图,AI就能像人类一样理解3D空间了。ICCV 2025最新中稿的LangScene-X:以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。
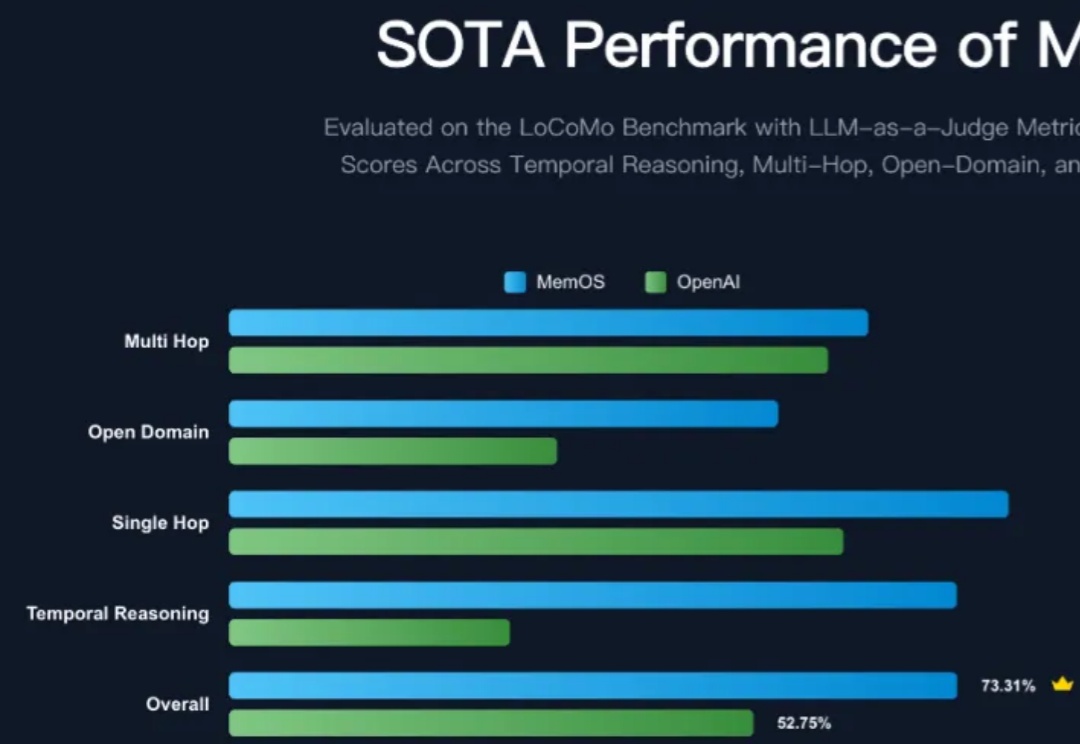
大模型记忆管理和优化框架是当前各大厂商争相优化的热点方向,MemOS 相比现有 OpenAI 的全局记忆在大模型记忆评测集上呈现出显著的提升,平均准确性提升超过 38.97%,Tokens 的开销进一步降低 60.95%,一举登顶记忆管理的 SOTA 框架,特别是在考验框架时序建模与检索能力的时序推理任务上,提升比例更是达到了 159%,相当震撼!
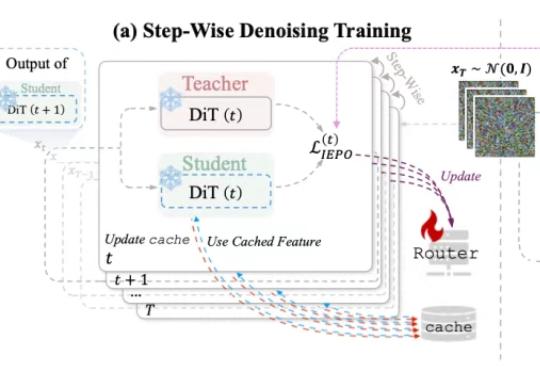
面对扩散模型推理速度慢、成本高的问题,HKUST&北航&商汤提出了全新缓存加速方案——HarmoniCa:训练-推理协同的特征缓存加速框架,突破DiT架构在部署端的速度瓶颈,成功实现高性能无损加速。
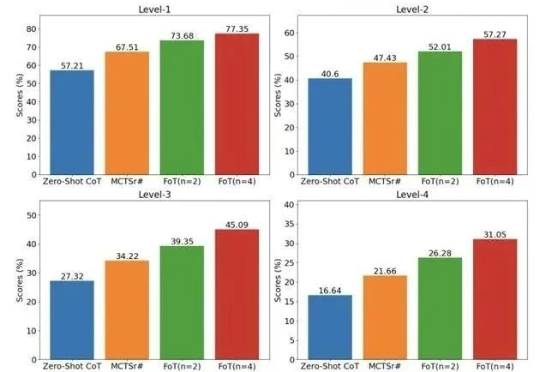
大模型越来越大,通用能力越来越强,但一遇到数学、科学、逻辑这类复杂问题,还是常“翻车”。为破解这一痛点,华为诺亚方舟实验室提出全新高阶推理框架 ——思维森林(Forest-of-Thought,FoT)。
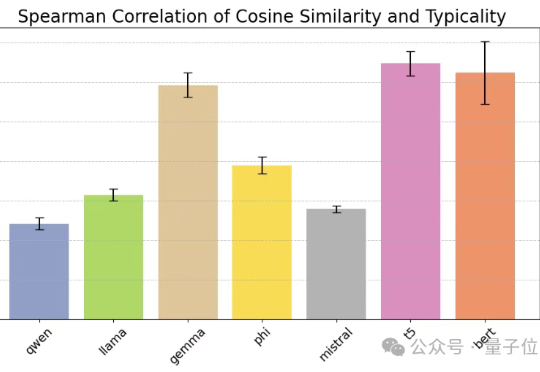
那问题来了:大型语言模型(LLM)虽然语言能力惊人,但它们在语义压缩方面能做出和人类一样的权衡吗?为探讨这一问题,图灵奖得主LeCun团队,提出了一种全新的信息论框架。该框架通过对比人类与LLM在语义压缩中的策略,揭示了两者在压缩效率与语义保真之间的根本差异:LLM偏向极致的统计压缩,而人类更重细节与语境。